


概述
随着大型语言模型(LLMs)驱动的 Agent 和多 Agent 系统(MAS)的快速发展,Agent 的安全问题日益受到关注。然而,现有研究在系统性方面仍有提升空间。
为应对这一挑战,来自南洋理工大学、松鼠AI的研究团队近期发布了 TrustAgent Survey。该研究并非旨在面面俱到地覆盖所有 Agent 安全研究领域,而是聚焦于凝练 Agent 安全的模块化体系架构。研究团队精选了近期具有代表性的文献,并尝试构建一份关于 Agent 安全的系统性参考。

论文标题:
A Survey on Trustworthy LLM Agents: Threats and Countermeasures
论文地址:
https://arxiv.org/abs/2503.09648
GitHub 主页:
https://github.com/Ymm-cll/TrustAgent

TrustAgent Survey 的价值
TrustAgent Survey 可能为研究者带来以下价值:
✅ 系统性地了解 Agent 安全的框架体系;
✅ 相对高效地掌握 Agent 安全领域的最新进展;
✅ 提供启发,促进未来在相关领域的深入研究工作。
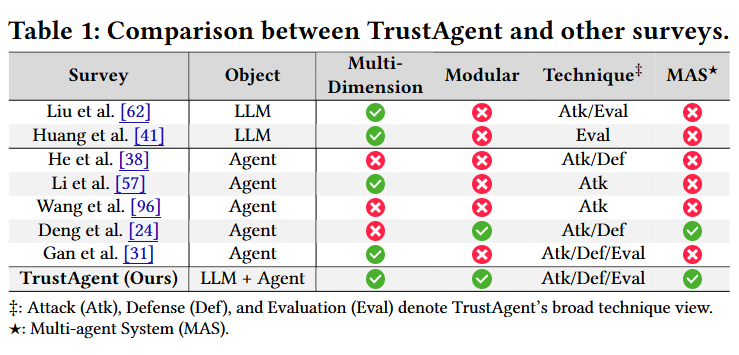
▲ 图1. TrustAgent Survey 与现有 Surveys 的比较

核心贡献
3.1 系统性视角
TrustAgent Survey 从“模块化角度”出发,将 Agent 系统拆解为内部模块(Brain, Memory, Tool)和外部模块(User, Agent, Environment),梳理各模块面临的安全风险和现有应对策略。
通过深入研究和总结新出现的针对代理和多智能体系统的攻击、防御和评估方法,TrustAgent Survey 将可信 LLM 的概念扩展到可信 Agent 的新兴范式。
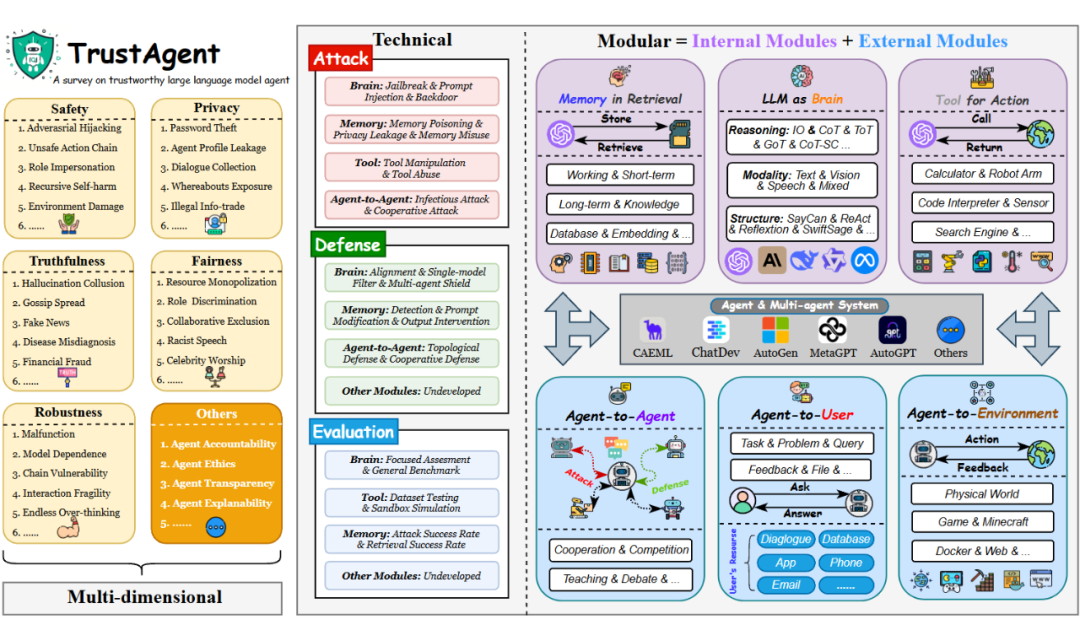
▲ 图2. TrustAgent Survey 分类法概述
TrustAgent Survey 中的分类法具有以下特点:
模块化:严格根据代理的内部和外部组件对可信度问题进行分类,分为内在(大脑、记忆、工具)和外在(用户、其他代理、环境)两个方面。
技术性:专注于可信代理的实现,从攻击、防御和评估三个方面对相关技术栈进行了全面的总结和展望。
多维性:将 LLM 可信度的维度扩展到单代理和 MAS 的上下文中,具体分为安全性、隐私性、真实性、公平性和鲁棒性,并引用了所有这些维度的现有工作。
3.2 技术框架
TrustAgent Survey 严格根据代理的内部和外部组件对可信度问题进行分类,具体分为内在和外在两个方面:
3.2.1 内生安全
内在可信度关注 Agent 系统内部模块的可信度。在 TrustAgent Survey 的定义中,Agent 系统是一个具有类人认知的独立实体,由具有记忆的大脑和工具形式的行为组成。由于这些模块的功能和性质不同,由此产生的可信度问题也各不相同。
3.2.2 外生安全
外部可信度关注与 Agent 系统交互的外部模块的可信度。在运行过程中,Agent 不断与外部交互,以收集信息或执行决策等。TrustAgent Survey 将与外部模块的交互分为三类:Agent 与 Agent、Agent 与环境和 Agent 与用户。
3.3 精选文献
TrustAgent Survey 侧重于精选近期且具有代表性的 148 篇 Agent 安全研究,希望能帮助读者快速了解领域进展,把握研究脉络。
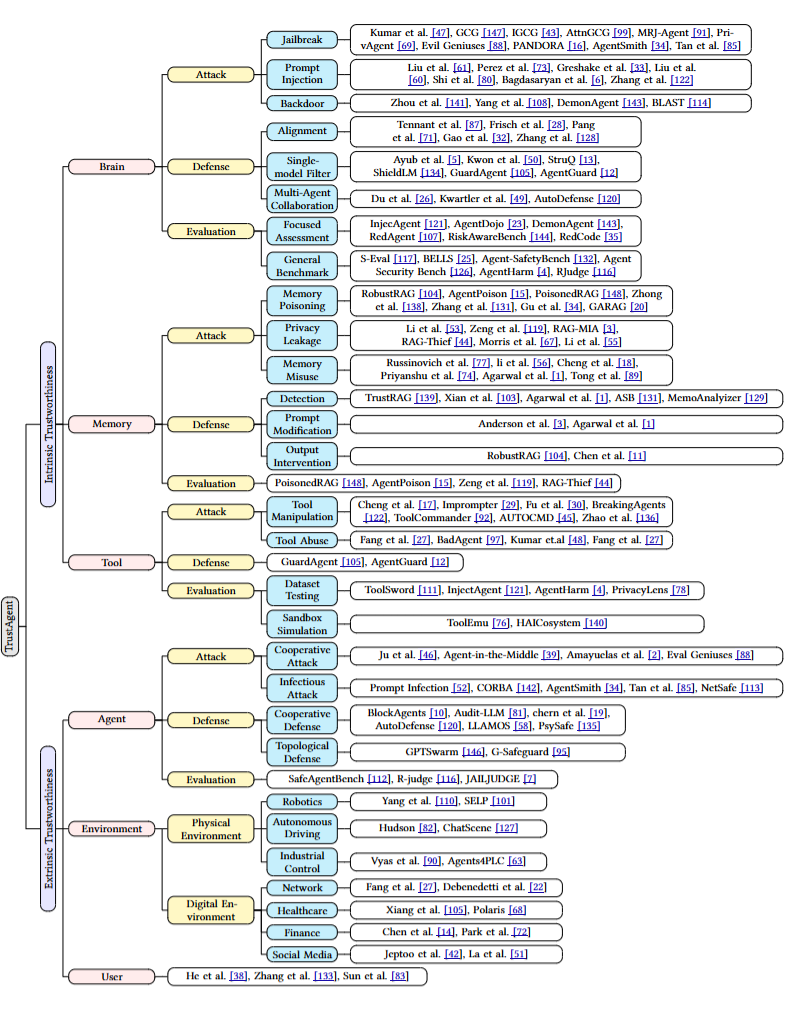
▲ 图3. TrustAgent Survey 的综合分类
3.4 研究展望
TrustAgent Survey 对每个模块进行了分析和总结,尝试提炼研究展望(Insights)和未来方向,希望能为 Agent 安全研究提供一些参考。
3.4.1 内生安全模块
在内生安全方面,文章指出当前协作攻击可通过单个被攻陷的智能体迅速传播至多个智能体,因此亟需开发协作安全机制,如分布式共识协议,以确保智能体在关键决策前进行集体验证。
同时,针对内存中心攻击方法的局限性,文章强调了在防御层面需从向量数据库端入手,防止有毒样本注入,并通过多轮对抗对话训练提升智能体的鲁棒性。此外,工具调用中的安全性问题也亟待解决,未来研究应关注工具链的多重调用安全与防御机制。
3.4.2 外生安全模块
在外生安全方面,文章揭示了智能体间交互带来的新型威胁——传染性攻击,并建议从自动化攻击、反传播防御及拓扑结构评估等角度展开研究。同时,环境与智能体间的可信交互被忽视,需系统化地设计攻击与防御机制以提升系统安全性。
文章还指出当前评估过于局限于特定领域,未来应开发跨学科、跨领域的安全评估框架,并强调通过自适应信任校准与可解释智能体技术提升用户与智能体间的信任透明度。
(文:PaperWeekly)