


作者:李宝珠
编辑:大头
转载请联系本公众号获得授权,并标明来源
HyperAI超神经官网上线了「使用 vLLM 部署 Gemma-3-27B-IT」教程,能够处理文本和图像输入,并生成文本输出,适用于各种文本生成和图像理解任务,包括问答、摘要和推理。
3 月 12 日晚间,谷歌发布了「单卡大魔王」Gemma 3,号称是能在单个 GPU 或 TPU 上运行的最强模型,真实战绩也证实了官方 blog 所言非虚——其 27B 版本击败 671B 的满血 DeepSeek V3,以及 o3-mini、Llama-405B,仅次于 DeepSeek R1,但在算力需求方面却远低于其他模型。如下图所示:
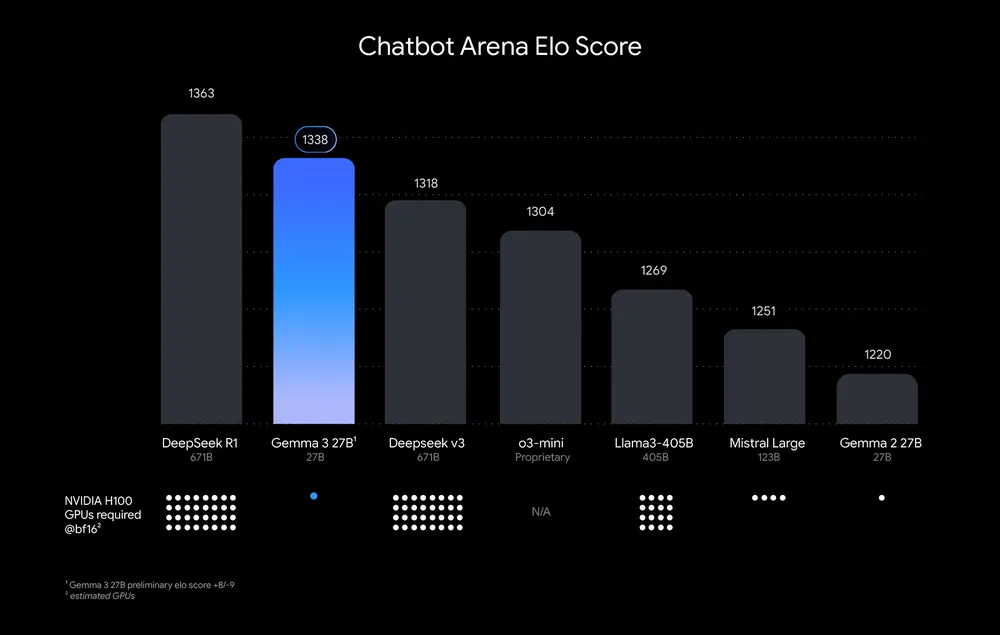
*按照 Chatbot Arena Elo 分数对模型进行排名;圆点表示预估的算力需求
随后,谷歌也是毫不吝啬地解禁了 Gemma 3 的技术报告。其中介绍道,Gemma 3 结合蒸馏、强化学习和模型合并等方法,预训练和指令微调版本的性能均优于 Gemma 2。同时还引入了视觉理解能力以及更广泛的语言理解能力,支持超 140 种语言理解,及 128k 长上下文。
在应用场景上,多模态大模型 Gemma 3 能够处理文本和图像输入,并生成文本输出,适用于各种文本生成和图像理解任务,包括问答、摘要和推理。本次开源的 1B、4B、12B 和 27B 四种参数版本,既有预训练模型,也有通用指令微调版本,可以直接在手机、笔记本电脑和工作站等设备上快速运行。
为了让大家更好地体验这个「单 GPU 最强多模态模型」,HyperAI超神经官网的教程版块上线了「使用 vLLM 部署 Gemma-3-27B-IT」,即 270 亿参数的指令优化版本。
教程链接:
https://go.hyper.ai/3QZNk
此外,我们还为大家准备了一份惊喜福利 —— 4 小时 单卡 RTX A6000 免费使用时长(资源有效期 1 个月),新用户使用邀请码「Gemma-3」注册即可获取,仅有 10 个福利名额,先到先得!
Demo 运行
1.登录 hyper.ai,在「教程」页面,选择「使用 vLLM 部署 Gemma-3-27B-IT」,点击「在线运行此教程」。
2. 页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
3.选择「NVIDIA A6000」以及「PyTorch」镜像,点击「继续执行」。我们已经将最新版本的 vLLM 提前 input 到了容器中。
OpenBayes 平台上线了新的计费方式,大家可以按照需求选择「按量付费」或「包日/周/月」,新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
HyperAI超神经专属邀请链接(直接复制到浏览器打开):
https://openbayes.com/console/signup?r=Ada0322_NR0n
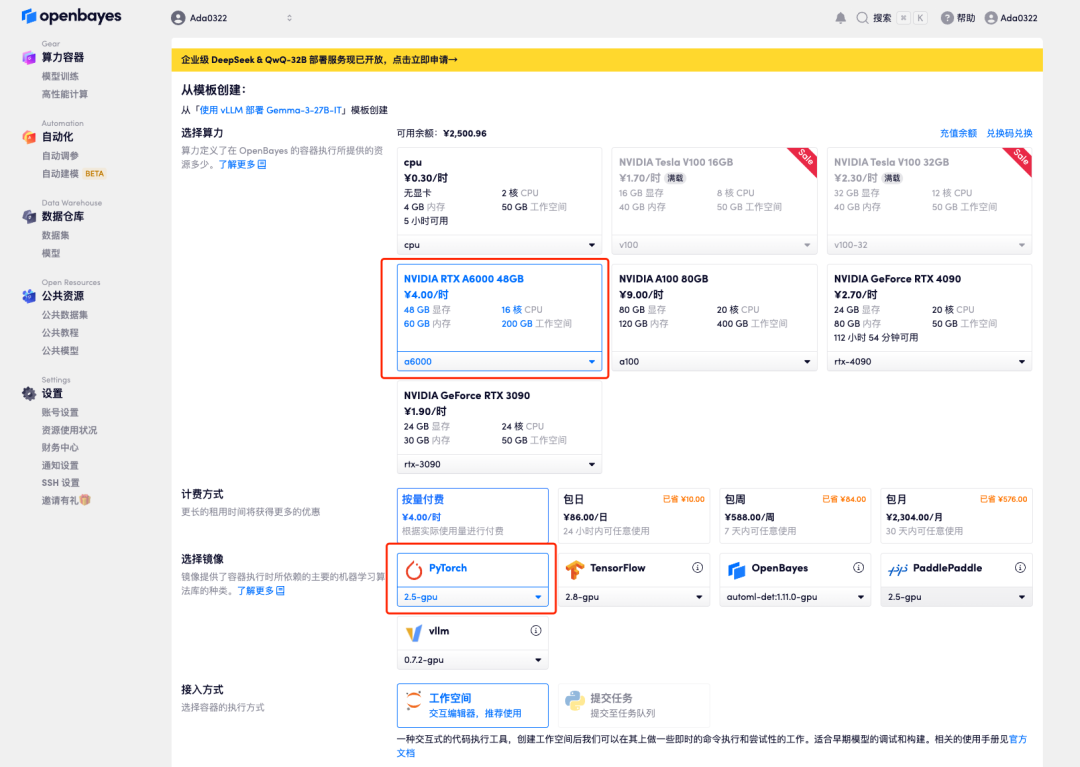
4.等待分配资源,首次克隆需等待 2 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」旁边的跳转箭头,即可跳转至 Demo 页面。由于模型较大,需等待约 3 分钟显示 WebUI 界面,否则将显示「Bad Gateway」。请注意,用户需在实名认证后才能使用 API 地址访问功能。
效果展示
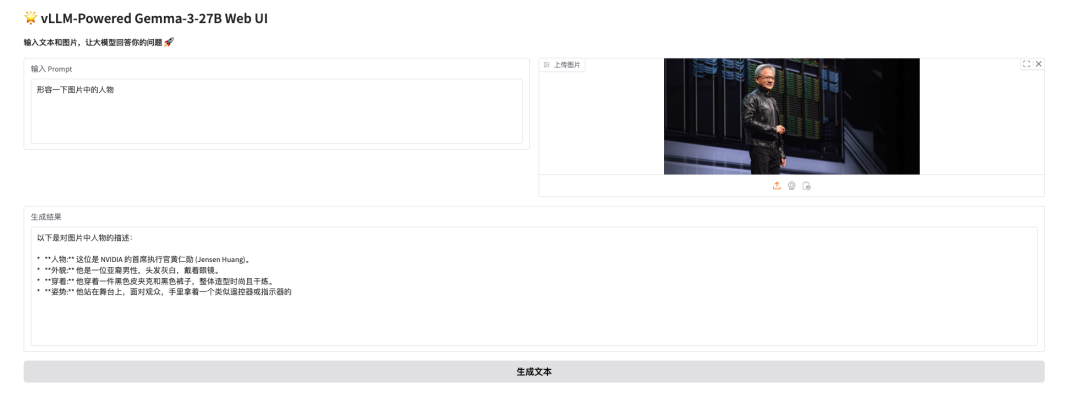
昨天(3 月 19 日)凌晨,「皮衣刀客」黄仁勋在 NVIDIA GTC 2025 带来了主题演讲,小编用他测试了一下 Gemma 3 对于图片的理解,其不仅一眼认出了老黄,还识别出他手握遥控器,正站在舞台上,如下图所示:



戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)