
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
今天凌晨1点,OpenAI进行了技术直播发布了三款全新语音模型,专用于开发语音AI Agent。
两个是语音转文本模型GPT-40 Transcribe和GPT-4 Mini Transcribe;一个是文本转语音模型GPT-40 Mini TTS。OpenAI还特意开发了一个新网站来展示新功能。
值得一提的是,开发者可以控制GPT-40 Mini TTS模型的语音情绪和风格,包括兴奋、平静、鼓励、严肃、热闹等,这对于搭建不同业务场景的智能体非常有用。
例如,在教育场景中,Agent可以用鼓励的语气激励学生;在客服场景中,Agent可以用温和、耐心的语气解答用户问题。
API地址:https://platform.openai.com/docs/guides/audio
展示地址:https://www.openai.fm/
完整技术直播视频
三款语音模型简单介绍
GPT-40
Transcribe是高性能版本,基于最新的语音模型架构,经过海量音频数据的训练,能够处理复杂的语音信号并将其准确地转换为文本。其训练数据量达到了前所未有的规模,涵盖了多种语言和方言,使得它在不同语言环境下的转录任务中表现出色。
GPT-4
Mini Transcribe则是在保持较高转录性能的同时,通过模型压缩技术,将模型大小大幅减小,从而提高了运行速度并降低了资源消耗。这种设计使得它更适合在资源受限的设备上运行,例如,移动设备或嵌入式系统,同时也能满足实时性要求较高的应用场景。
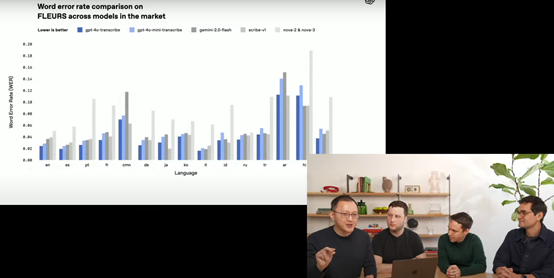
在性能方面,这两款语音模型相比上一代OpenAI的Whisper模型有了明显提升,能够更精准地捕捉语音中的细微差别,减少转录错误。测试结果显示,最新语音模型的词错误率大幅降低,也比同类的模型更好。
GPT-40
Mini TTS模型不仅能够将文本内容转换为自然流畅的语音,还允许开发者通过指令控制语音的语调、情感和风格。使得语音Agent能够根据不同的情境和用户需求,调整语音的表达方式,从而更好地传达信息和情感。
GPT-40
Mini TTS模型采用了先进的语音合成技术,能够生成高质量的语音输出。它通过模拟人类的发声机制和语音特征,使合成语音听起来更加自然、逼真。
这使得语音Agent在与用户交流时,能够提供更加亲切、生动的语音体验,增强用户的参与感和满意度。该模型也支持多种语言,并且能够生成不同性别、年龄和口音的语音,能够适应不同地区、不同文化背景的用户需求,提供更加个性化的语音服务。
API、SDK重大更新
OpenAI为语音转文本API增添了强大的streaming模式,允许开发者将连续的音频流实时输入模型,模型也能实时返回连续的文本和响应,这种实时交互的特性对于需要即时反馈的应用场景,例如,实时语音对话系统、语音会议转写等,帮助非常大。
而API 集成的噪声消除技术和语义语音活动检测器进一步优化了语音转文本的体验。噪声消除技术能有效过滤掉背景噪音,使模型专注于用户的语音内容;
语义语音活动检测器则可根据模型对用户说话结束的判断,对音频进行合理分块处理,避免处理不完整的语音信息,让开发者无需再为处理复杂的语音数据而烦恼,能够更专注于上层应用的开发。

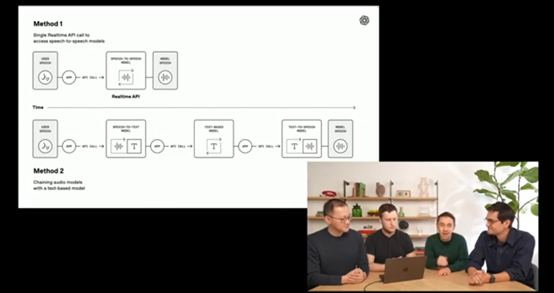
为了帮助开发者更轻松地构建语音Agent,OpenAI对其SDK进行了重大更新。新的Agents SDK采用了模块化设计,将语音转文本、文本处理和文本转语音等功能模块化,开发者可以根据自己的需求灵活组合这些模块,构建出符合特定应用场景的语音Agent系统。模块化的设计方式不仅提高了开发效率,还增强了系统的可扩展性和可维护性,使得开发者能够更容易地对Agent系统进行升级和优化。
通过Agents SDK,开发者可以利用已有的文本Agent基础,只需添加少量代码,即可实现语音交互功能。SDK提供了丰富的接口和工具,帮助开发者处理语音输入、文本处理和语音输出等各个环节,减少了开发工作量和复杂性。
例如,开发者可以轻松地将语音转文本模型集成到Agent系统中,实现语音指令的实时转录和处理;

同时,也可以方便地将文本转语音模型应用于输出环节,为用户提供语音反馈。新的SDK在性能和可靠性方面进行了优化,确保语音Agent系统能够稳定、高效地运行。支持实时音频流处理,能够快速响应用户的语音指令,提供流畅的语音交互体验。
此外,SDK还集成了噪声消除、语音活动检测等功能,能够有效提高语音识别的准确性和系统的稳定性,即使在嘈杂的环境中,也能够准确地捕捉用户的语音输入并进行处理。
目前,这些语音模型已经可以在API和SDK中使用。
(文:AIGC开放社区)