

今天是2025年3月21日,星期五,北京,天气晴。
今天看两个主题,一个是大模型微调数据生产,一个是知识图谱融合大模型的思路。
也就是Easy Dataset大模型微调数据生成工具的三个问题以及大模型与知识图谱结合框架KBLaM实现分析。
前者是工程化工具,后面是一个结合技术前沿,分打不同的点,根据实际情况做选择,会有更多收获。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、Easy Dataset大模型微调数据生成工具的三个问题
Easy Dataset(https://github.com/ConardLi/easy-dataset),一个专为创建大模型(LLM)微调数据集而设计的项目,提供了直观的界面,用于上传特定领域的文件,智能分割内容,生成问题,并为模型微调生成高质量的训练数据。社区成员有测试过,还不错,具体说明说明文档在:https://rncg5jvpme.feishu.cn/docx/IRuad1eUIo8qLoxxwAGcZvqJnDb?302from=wiki
我们可以关注三个问题。
1、当前微调模型的数据痛点
里面提到的这几个问题说的很中肯,这个工具的远景是很好了,也着实点出了当前大模型微调的一些问题,可以看看,是现实痛点。
目前各行各业都在积极探索微调自己行业的大模型,其实微调的过程不是难事,目前市面上也有比较多成熟的工具,比较难的是前期的数据集准备的环节,数据集的质量直接决定了模型微调后的效果,高质量领域数据集的构建始终面临多重挑战,大家在构建数据集的过程中可能会普遍遇到以下问题:
1)完全不知道怎么做,目前就在纯人工去做,想提高效率;
2)直接将文档丢给AI,但是AI对于大文件生成的QA对效果比较差;
3)AI本身有上下文的限制,一次不能生成太多的问题,分批生成后面又会生成重复的问题;
4)已经有整理出来的数据集了,想有一个批量管理数据集的地方,可以进行标注和验证;
5)对于数据集有细分领域的需求,不知道如何去构建领域标签;
6)想要微调推理模型,但是不知道推理微调数据集中的COT怎么构造;
7)想从一个格式的数据集转换成另一个格式的数据集,不知道怎么转换;
2、如何具体实现?
那么,具体是什么做的?视频教程在:https://www.bilibili.com
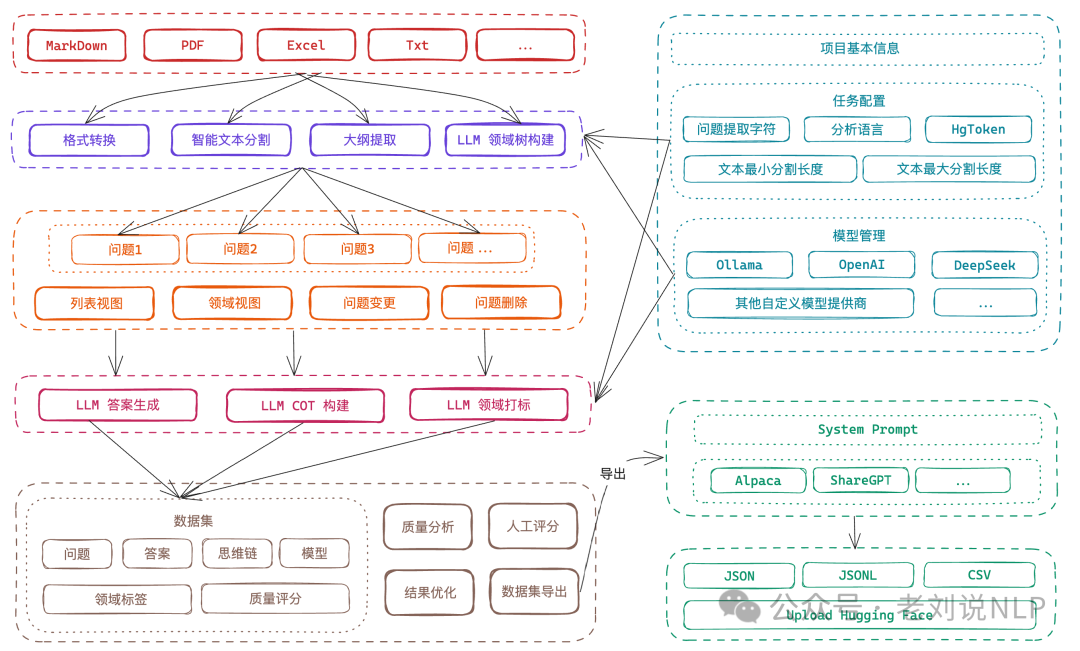
在文档处理环节,上传Markdown文件并自动将其分割为有意义的片段,在”文本分割”部分上传Markdown文件;查看自动分割的文本片段,并根据需要调整分段。
在问题生成环节,从每个文本片段中提取相关问题,导航到”问题”部分;选择要从中生成问题的文本片段;查看并编辑生成的问题;使用标签树组织问题。
在答案生成缓解, 使用LLM API为每个问题生成答案。转到”数据集”部分,选择要包含在数据集中的问题,使用配置的LLM生成答案;查看并编辑生成的答案。
在数据导出环节,以各种格式(Alpaca、ShareGPT)和文件类型(JSON、JSONL)导出数据集,在数据集部分点击”导出”按钮;选择喜欢的格式(Alpaca 或 ShareGPT);选择文件格式(JSON 或 JSONL),根据需要添加自定义系统提示,然后导出最终数据集。
3、实际效果以及大家的实际需求又是什么?
但是?是否真的达到的目的?
关于大家的用户反馈问题可以看:https://github.com/ConardLi/easy-dataset/issues/ 。如:
又如:
总的来说,还很初步,一个知识库只能导入一个文件,不然,需要删除该文件,再导入,弄QA对。整体大面的功能不错,后面支持多文件,并发,就比较适合使用。并且,这个项目是纯JS写的,不好二次开发,/video/BV1y8QpYGE57/**。
所以,也给出了一些未来的规划,这个其实也是真是场景中所需要关注的,其实可以看到大家的刚需,几个方面。
1)文献格式,单项目支持上传多个文件、支持多种类型(PDF、World、Excel)的文献解析;
2)多模态支持,支持图片、视频、音频等多模态数据集生成;
3)质量评估,引入BLEU、ROUGE等指标,自动标注数据置信度,降低人工校验成本;
4)数据标注,支持强化学习偏好数据集的质量标注,完善数据集评估能力;
5)蒸馏数据集,支持不基于领域文献,直接基于大模型生成用于模型蒸馏的数据集;
6)平台联动,支持HuggingFace数据集一键上传,支持从HuggingFace等平台一键拉取数据集,进行二次评估。
二、大模型与知识图谱结合框架KBLaM实现分析
如何有效地将大规模知识库(Knowledge Base, KB)中的知识增强到大模型(Large Language Model, LLM)中,而不需要修改LLM的权重或进行微调。
一般来说,如果不微调,那么就有两种方式,检索增强生成(RAG)和上下文学习。RAG通过检索模块从外部文档中提取相关知识片段,并将其与输入问题一起输入到LLM中。

上下文学习则将整个外部语料库放入LLM的上下文中,消除了对检索模块的需求。

然而,RAG需要额外的检索模块,而上下文学习的计算复杂度随上下文长度的增加而呈二次增长。
所以,那就soft融合一下。

关于知识图谱与大模型结合进展,微软的工作《KBLaM – Knowledge Base Augmented Language Models》(https://arxiv.org/pdf/2410.10450),最近有人在讲,但这个其实很早起了,去年的工作,主要是官放在https://www.microsoft.com/en-us/research/blog/introducing-kblam-bringing-plug-and-play-external-knowledge-to-llms/特意写了个blog。
这个东西究竟是什么,我们可以看看,代码在:https://github.com/microsoft/KBLaM,核心点就是通过结构化知识库整合提升模型效率,将知识库编码为连续键值对向量,使用矩形注意力机制直接融入模型注意力层。
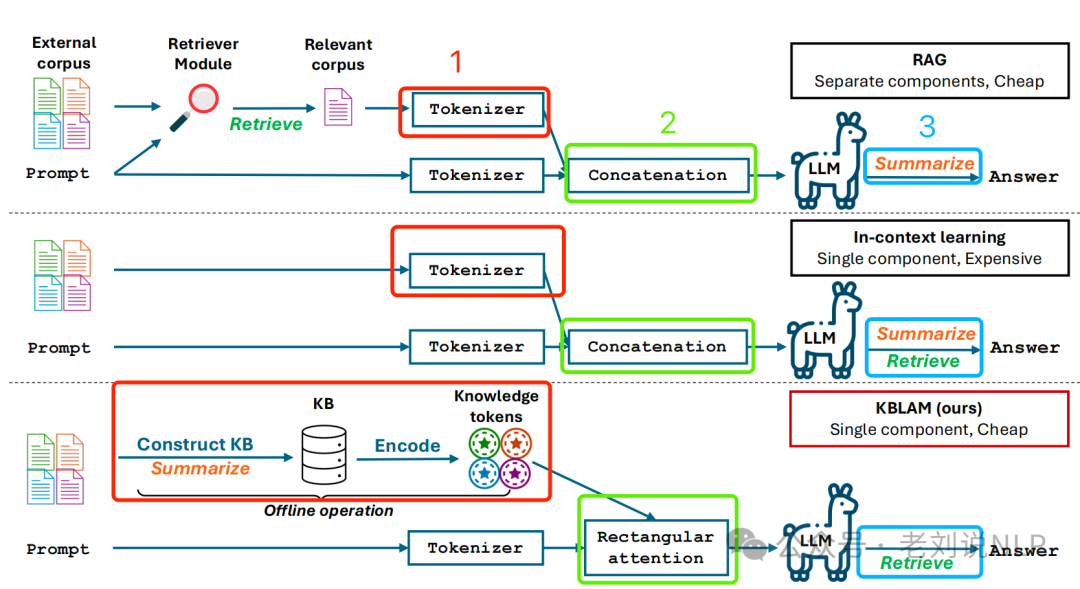
对比这个图,有三个不一样:
1、不走tokenizer,而是走encoding,这里就得用到向量化模型以及怎么做KB的向量化;
2、不走concate,因为前两个还是属于同一个编码器,没法做到,所以就做一个rectangular attention进行投影映射;
3、生成阶段,不是走的sumamrize,而是走的retrive检索。
因此,就可以看看实现了,
1、知识库转换
三元组形式化为如下:
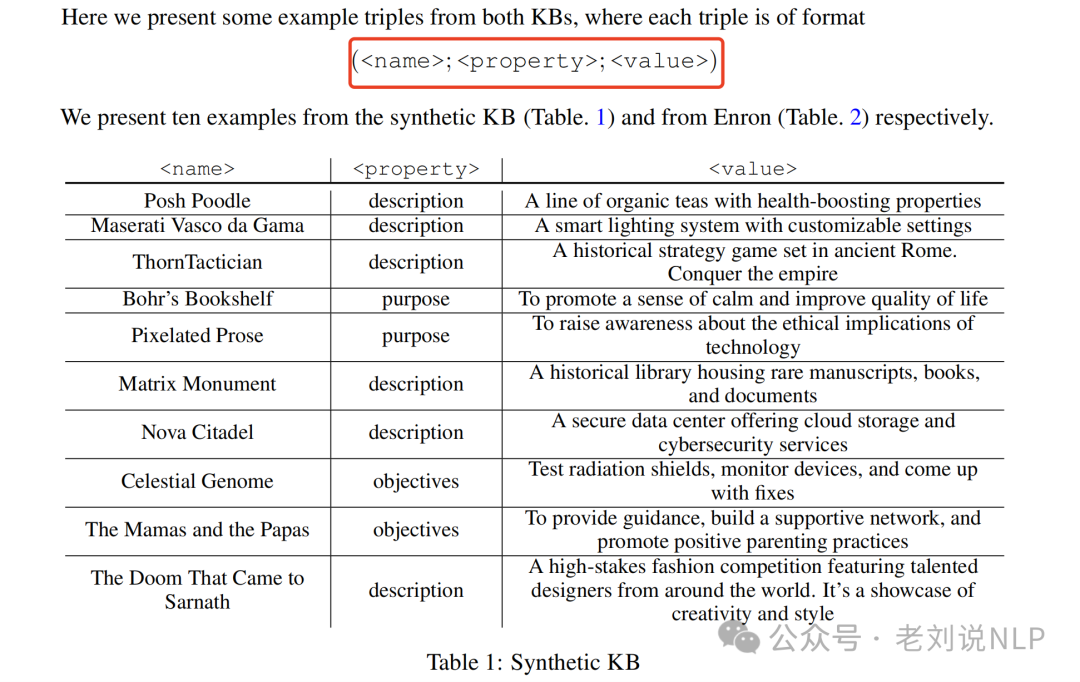
使用预训练的句子编码器将知识库中的每个三元组(实体名、属性、值)(entity name (<name>), a property (<property>), and a value (<value>).)转换为固定长度的键值向量对,称为知识token,也就是连续的嵌入向量,这些token的大小与单个token的键值嵌入相同。
其中,通过编码器,将每个三元组转换为一个基础键嵌入和一个基础值嵌入,示意图如下:

对于知识库(等式(1))中的M个三元组中的每个三元组,首先构建一个键和值字符串(最左边的白色方框),然后,这两个字符串通过一个预训练的句子编码器处理,接着是一个学到的线性适配器(中间的两个蓝色方框)。
2、做特征投影
然后,引入线性键和线性值适配器,将知识token增强到注意力机制中,对于第L层,给定一个来自提示的ND维嵌入序列 (例如关于知识库的一个问题),通过增加M个知识令牌作为上下文),最终将预训练句子编码器的空间映射到LLM的键值嵌入空间**。
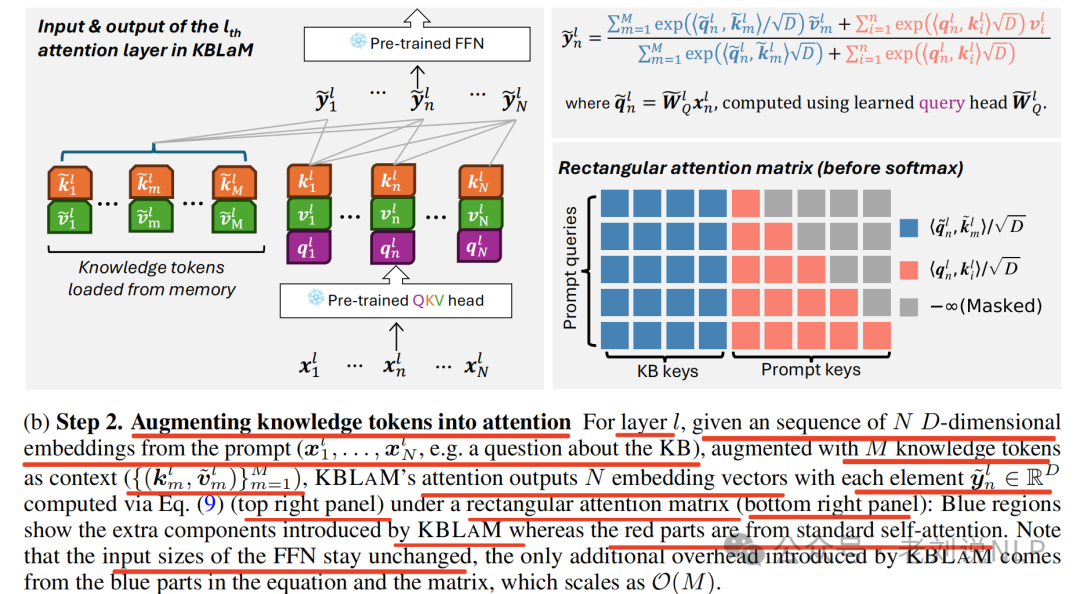
那么,怎么去微调呢?
核心还是微调数据的合成,这个思路可以看看:

首先使用GPT基于30种对象类型(例如餐厅名称、软件工具)和30种想法类型(例如自然现象、著名地标)的组合来生成50个<名称>。然后对于每个名称,提示GPT在相同的对话情境中生成该名称的三个<属性>的<值>:“描述”、“目标”和“目的”,这个至关重要的是,提示指导GPT生成与名称无关的<值>,确保信息来源于知识库而不是LLM的预测能力。这产生了45K个名称和一个大约包含135K个三元组的知识库。
然后,使用指令微调的Llama 38B作为骨干大模型,并使用OpenAI的ada-002句子嵌入模型(P=1536)作为预训练的编码器来计算基础键和值嵌入。
其中每个训练样本包括一个知识库、一个问题和一个答案。为了构建每个训练样本,从合成知识库中随机选择10到100个三元组的一个子集,形成一个特定于样本的知识库,根据指令类型(简单、多实体、开放式或无法回答的问答),指定一个、多个或没有三元组作为相关三元组,其余的作为干扰项,基于指令模板和相关三元组生成一个问题。
最后,效果如何?
还是要看对比实验,有零样本学习和上下文学习两种方式。
上下文学习方式,将知识库中的所有三元组展平为字符串,并附加在提示语的前面。上下文学习的内存开销随着三元组数量的增加呈二次方增长。
零样本学习方式,直接向大模型提出特定问题,不提供额外上下文,而是利用大型语言模型内部的知识回答问题。
3、检索推理
KAML在推理时,像大模型提出特定问题,然后KAML自动地内部检索相应知识三元组,然后回答问题。
这个就很有趣,研究发现,因为对于任何查询,具有最高关注度的Top-K个三元组构成了支持性证据,这种行为表明KBLAM的注意力机制隐式地充当了检索器,真实三元组要么获得了最高关注度分数,要么位于前五名高分之中。
最终看下效果:
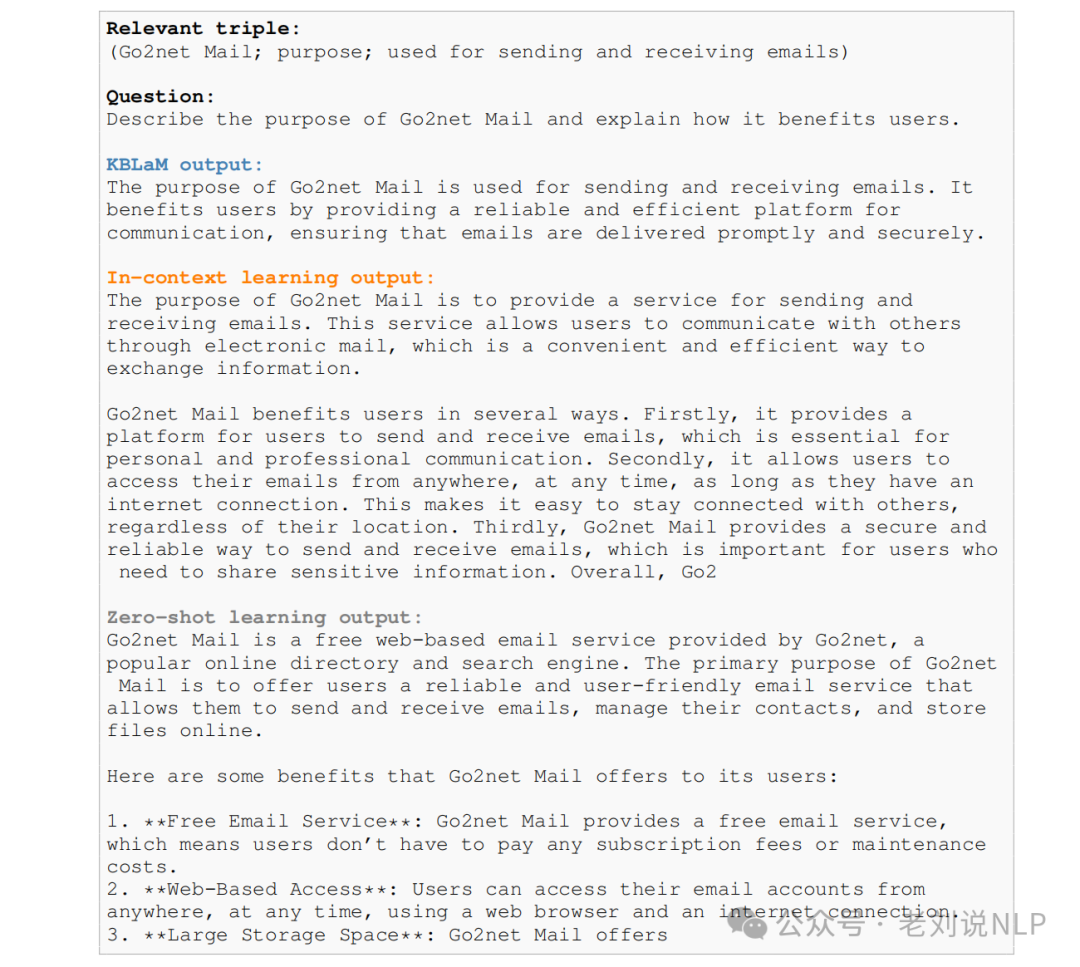
此外,还有个有趣的点,当知识库中没有相关信息时,KBLAM能够拒绝回答。
4、从实际场景出发,比如我有一个领域知识库,有1w个三元组,如果使用kblam,该怎么用?
首先,要确保领域知识库是以三元组的形式组织的,每个三元组包含一个实体名称(<name>)、一个属性(<property>)和一个值(<value>)。例如:(实体名称; 属性; 值)。
然后,选择预训练模型和编码器,选择一个适合任务的预训练语言模型(LLM),例如Llama3或其他类似的模型,选择一个预训练的句子编码器,如OpenAI的ada-002,用于将三元组转换为连续的向量表示。
接着,使用预训练的句子编码器和线性适配器将每个三元组转换为一个知识token, 将实体名称和属性编码为键向量,将值编码为值向量,然后使用KBLAM的方法将知识token注入到LLM的自注意力机制中。通过修改注意力结构,使知识token能够被有效地整合到模型的上下文中。
最后,使用指令微调来训练线性适配器,以便模型能够正确地使用知识库中的信息,这可以通过生成问题和答案对来实现,然后优化适配器的参数。如果你的知识库需要更新,只需重新生成或更新相应的知识token,而不需要对整个模型进行微调或重新训练。
在推理阶段,准备问题或输入文本,这个输入将作为模型的提示(prompt),然后加载经过指令微调的KBLAM模型,在模型的自注意力机制中注入知识token,然后在注意力层中,模型的查询向量将与知识令牌的键向量进行比较,计算注意力权重,然后模型将加权平均知识令牌的值向量,并将其与输入文本的隐藏状态相结合,生成最终的输出。
具体想使用的,可以看:https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct,里面开放出来一些训练好的模型。
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
messages,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][-1])
5、那么,怎么评价这种方案?
优点方面,KBLAM通过将知识库中的信息转换为连续的向量表示,并将其直接注入到LLM的自注意力机制中,这种方法避免了复杂的检索模块,简化了整体流程,允许知识库的大小线性扩展,而不会像传统的上下文学习那样导致计算复杂度呈二次增长。这使得KBLAM能够处理较大大的知识库(超过10K个三元组,其实也并不大);支持动态更新知识库,无需重新训练或微调模型,只需更新相应的知识token即可,这使得模型能够快速适应新的知识变化;通过使用指令微调,KBLAM可以学会在知识库中没有相关信息时拒绝回答问题,从而减少模型产生幻觉的风险;注意力机制提供了高度的可解释性,可以通过检查注意力分数来了解模型如何使用知识库中的信息。
缺点也很明显,需要进行一次性的训练来微调线性适配器,这可能需要较长的时间和计算资源,虽然这是单次成本,但对于频繁更新知识库的场景可能不太适用;将多个词的信息压缩到一个固定长度的向量中,可能会导致信息的丢失,这对于需要精确匹配或数值信息的任务可能不适用;依赖于预训练的句子编码器和知识库构建工具。这些工具的质量和可用性可能会影响最终的性能;知识库的质量直接影响模型的性能,如果知识库中的信息不准确或不完整,模型可能会产生错误的答案;在大规模知识库的情况下,仍然可能面临较高的计算开销。
总结
本文主要介绍了Easy Dataset大模型微调数据生成工具的三个问题以及大模型与知识图谱结合框架KBLaM实现分析,前者是工程化工具,后面是一个结合技术前沿,分打不同的点。
多思考,多分析。
参考文献
1、https://rncg5jvpme.feishu.cn/docx/IRuad1eUIo8qLoxxwAGcZvqJnDb?302from=wiki
2、https://arxiv.org/pdf/2410.10450
(文:老刘说NLP)