


背景
最近,我和几位小伙伴
https://github.com/sgl-project/sglang/pull/7278
在研发的过程中,我们主要参考了CUTLASS Example 68(https://github.com/NVIDIA/cutlass/blob/main/examples/68_hopper_fp8_warp_specialized_grouped_gemm_with_blockwise_scaling/68_hopper_fp8_warp_specialized_grouped_gemm_with_blockwise_scaling_with_sparse_groups.cu),并在此基础上,进行了一些性能方面的分析和优化工作。我们将我们的发现总结为如下两点:
-
在大多数的场景下,Pingpong调度策略的性能优于Cooperative调度策略的性能。其中的主要原因是Pingpong调度策略通过Ordered Sequence Barrier严格的约束了两个Consumer Warp Group的执行顺序,令两个Consumer Warp Group交错执行Mainloop和Epilogue,有效的Overlap掉了Epilogue的开销。而Cooperative中的两个Consumer Warp Group依赖于同样的数据,在数据到达后以一种“竞争”的模式使用TensorCore计算资源,在“势均力敌”的情况下,Mainloop的执行结束时间相接近,导致Epilogue不能够被有效的Overlap。
-
在K维度较小的场景下,DeepGEMM的性能优于CUTLASS。原因有两点——首先,DeepGEMM会使用算术强度更大的QGMMA指令(例如,CUTLASS 64x128x32 vs. DeepGEMM 64x160x32)。其次,CUTLASS的Epilogue中进行了不必要的LinearCombination,导致执行了大量的不必要的FFMA指令。
因此,我们打算撰写一系列的文章,以记录我们在这项工作中的发现。首先,本篇文章将会介绍上述两点中的第一点。
Cooperative和Pingpong的官方定义
Cooperative和Pingpong都是Warp Specialization Persistent Kernel的调度策略。关于Warp Specialization以及Persistent的概念,大家可以参考CUTLASS的官方文档(https://github.com/NVIDIA/cutlass/blob/main/media/docs/cpp/efficient_gemm.md)。
官方文档中也说明了Cooperative调度策略和Pingpong调度策略的区别,我们简单做个总结,Cooperative调度策略令两个Consumer Warp Group计算同一个Output Tile,一个Warp Group计算Output Tile的上半部分,另一个Warp Group计算Output Tile的下半部分。而对于Pingpong调度策略,两个Consumer Warp Group则是分别计算不同的Output Tile。
因此,如果我们为这两种调度策略设置同样大小的TileShape,Pingpong调度策略的Register Pressure一定更大,因为它需要单个Consumer Warp Group为整个Output Tile分配寄存器资源用于存储运算结果,而对于Cooperative,单个Consumer Warp Group仅需为一半Output Tile分配寄存器,因此在许多CUTLASS Examples中,Pingpong的TileShape通常都是Cooperative的一半,例如,在CUTLASS Example 57(https://github.com/NVIDIA/cutlass/blob/main/examples/57_hopper_grouped_gemm/57_hopper_grouped_gemm.cu)中,我们可以看到如下代码:
// Different configs for pingpong/cooperativestruct CooperativeConfig {using KernelSchedule = cutlass::gemm::KernelPtrArrayTmaWarpSpecializedCooperativeFP8FastAccum;using EpilogueSchedule = cutlass::epilogue::PtrArrayTmaWarpSpecializedCooperative;using TileShape = Shape<_256,_128,_128>;using ClusterShape = Shape<_1,_2,_1>;};struct PingpongConfig {using KernelSchedule = cutlass::gemm::KernelPtrArrayTmaWarpSpecializedPingpongFP8FastAccum;using EpilogueSchedule = cutlass::epilogue::PtrArrayTmaWarpSpecializedPingpong;using TileShape = Shape<_128,_128,_128>;using ClusterShape = Shape<_2,_1,_1>;};
显然,Pingpong调度策略的Output Tile仅有Cooperative调度策略的一半大小。
关于Pingpong调度策略的性能优势
CUTLASS官方文档并未详细的描述这两种调度策略的性能以及各自的适用场景。笔者曾经搜集并学习过一些相关资料,因此,在本节当中,笔者先将这些资料推荐给各位读者,然后再谈一谈笔者自己的理解。
首先,第一份资料是NVIDIA AI技术开放日的视频学习资料,链接如下:
https://space.bilibili.com/1320140761/lists/3446369?type=season
NV的刘冰老师建议尽可能多的使用Pingpong调度策略,因为它通常具有更好的性能。
第二份资料是Pytorch官方的博客:https://pytorch.org/blog/cutlass-ping-pong-gemm-kernel/
在NVIDIA GPU上,对于GEMM类的Compute-bound算子,性能优化的目标通常是持续的,饱和的利用所有SM Core上的TensorCore运算单元。在CUTLASS GEMM Kernel中,Mainloop阶段主要利用的是TensorCore运算单元,而Epilogue阶段则是完成一些额外的计算操作(例如实施激活函数)并将结果写回Global Memory,这些操作并不依赖于TensorCore。因此,结合性能优化的目标,我们希望在整个Kernel的生命周期中尽可能的使用Mainloop掩盖Epilogue的开销,避免将Epilogue直接暴露在Timeline上,以最大化TensorCore的利用率。
第一份视频教程中关于Cooperative调度策略的示意图如下:
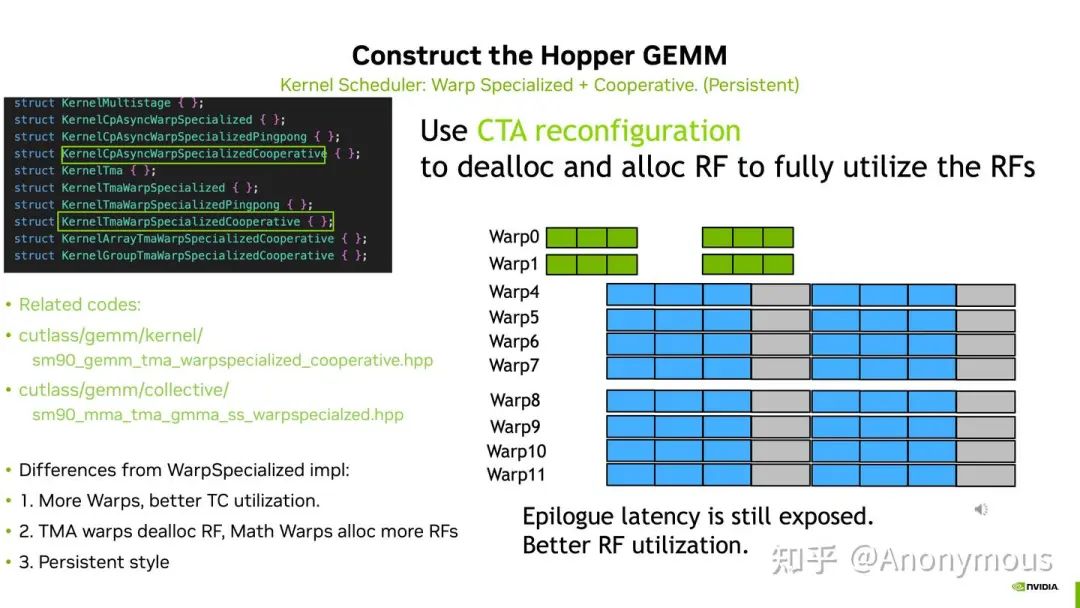
可以看到使用Cooperative调度策略时,Epilogue部分是暴露在Timeline上的。
相比之下,使用Pingpong调度策略时,Epilogue部分则是完全被Mainloop部分Overlap掉了,如下图所示:
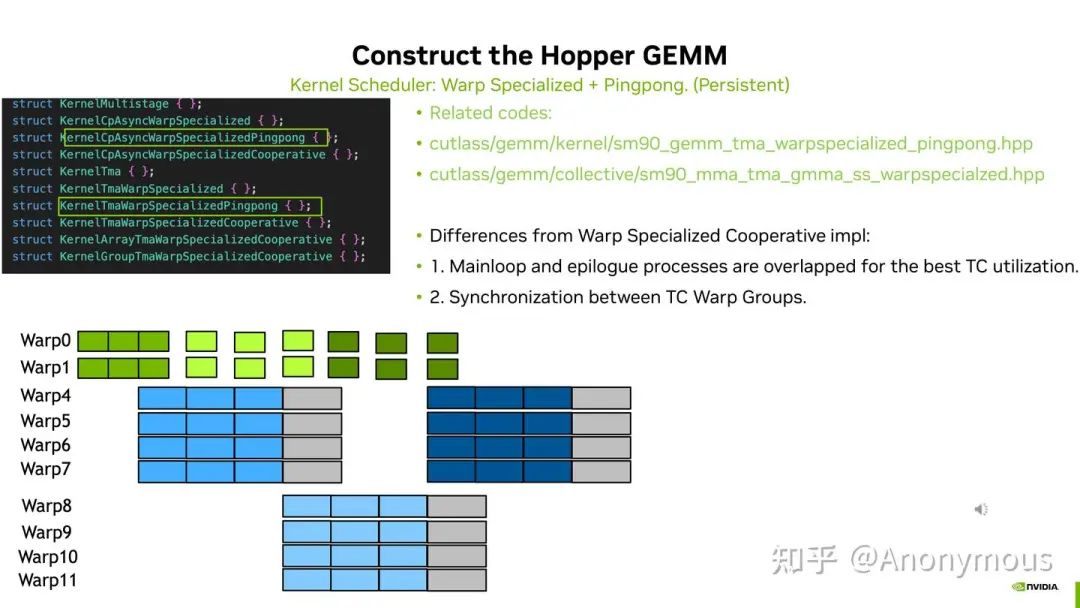
当然,上面的两张图片只是理想情况下的简单示例。接下来我们来看一看真实Kernel的Timeline是否和上图具有一致的现象,此时我们需要利用ncu的一个新特性——PM Sampling(https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html#pm-sampling)。
我们按照如下配置分别运行使用Cooperative调度策略和Pingpong调度策略的FP8 Blockwise Scaling Grouped GEMM:
-
num_groups=256
-
M=128
-
N=512
-
K=7168
首先,我们来观察Cooperative Kernel的PM Sampling Timeline:
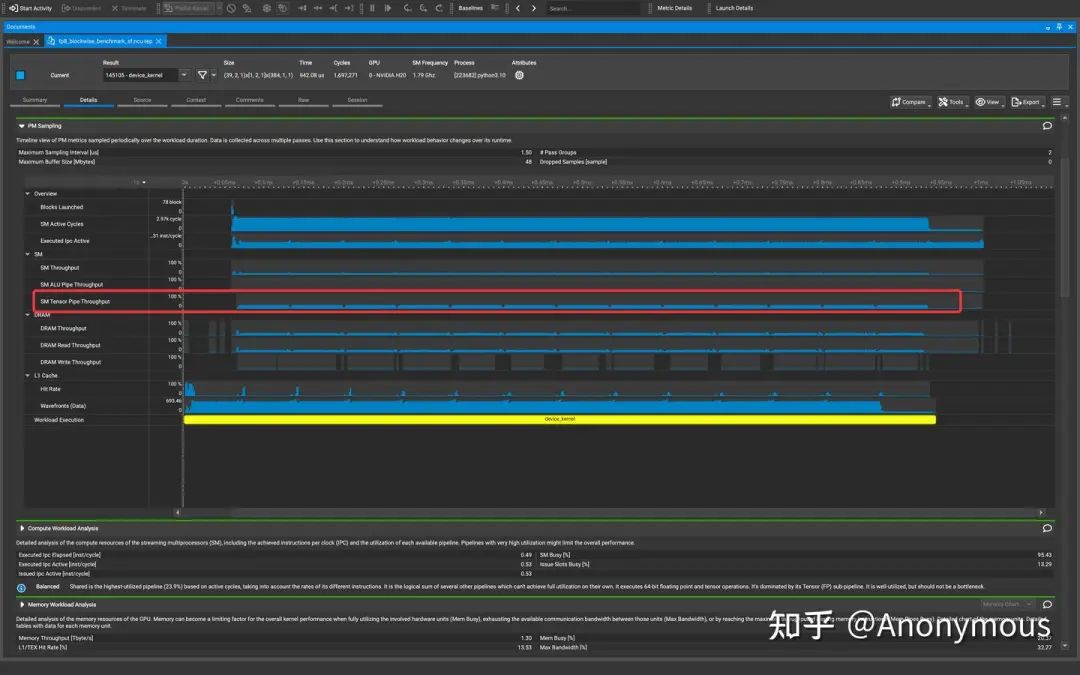
可以看到,Tensor Pipe Throughput出现了非常明显的周期性下降的现象,在Timeline上形成了一些“缺口”。如果我们仔细的去数一数这些“缺口”的数量,可以发现这些“缺口”共有12个。由于我们使用的是H20 GPU(具有78个SM Core),并且Cooperative调度策略使用的TileShape为(128, 128, 128),因此我们可以推算每个CTA需要计算的Output Tile的数量:
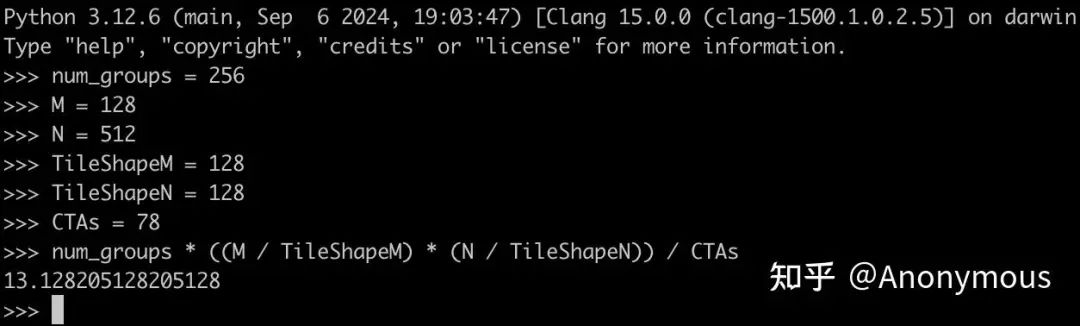
显然,多数CTA需要计算13个Output Tile,在Warp Specialization Persistent Kernel中,每个SM Core只调度一个CTA,因此SM Core上的运行状况就是单个CTA的运行状况。12个缺口恰好对应了前12个Output Tile的Epilogue阶段。相比之下,Pingpong调度策略的PM Sampling Timeline显示Tensor Pipe Throughput始终处于一个相对稳定的水平,不会出现明显的“缺口”现象:
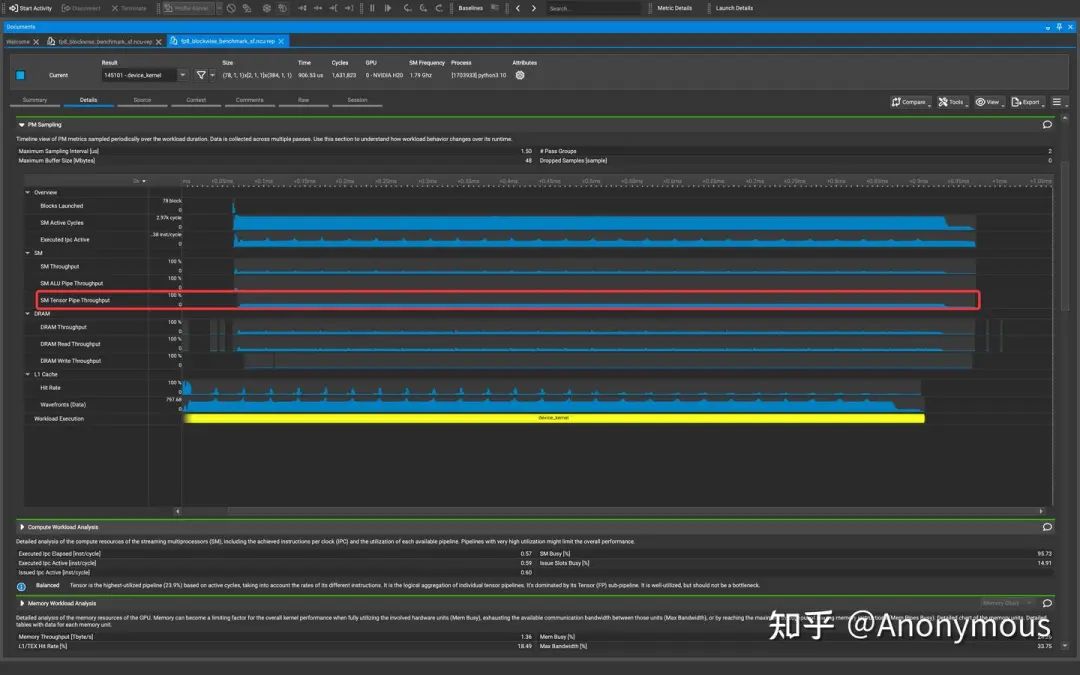
Cooperative无法Overlap掉Epilogue的原因
虽然我们已经明确了Pingpong调度策略具有性能优势的原因,但是我们也需要想一想这个问题的对立面——为什么Cooperative调度策略不能Overlap掉Epilogue呢?
起初,笔者猜测,问题的原因可能在于复杂多变的Epilogue需求,比如,我们需要在Epilogue中对整个Output Tile进行Reduce操作,又或者是我们想要在Epilogue中使用TMA写回整个Output Tile,可想而知,此时只有在两个Consumer Warp Group都完成了Mainloop后,才可以安全的发起Epilogue操作,这一定需要同步两个Consumer Warp Group。这里的同步操作,会导致Epilogue无法被Overlap。
基于以上想法,笔者认为一定可以在CUTLASS的代码中找到这个Consumer Warp Group之间的同步,但是事与愿违,我们并未在代码中找到相关的同步操作,代码逻辑非常直观,运行完Mainloop后,就开始执行Epilogue,这之间并不需要任何同步操作:
collective_mainloop.mma(mainloop_pipeline,mainloop_pipe_consumer_state,accumulators,work_k_tile_count,mma_thread_idx,shared_storage.tensors.mainloop,params.mainloop);// Make sure the math instructions are done and free buffers before entering the epiloguecollective_mainloop.mma_tail(mainloop_pipeline,mainloop_pipe_consumer_state,work_k_tile_count);// Update starting mainloop pipeline state for the next tilemainloop_pipe_consumer_state.advance(work_k_tile_count);// Index of warp group within consumer warp groupsint consumer_warp_group_idx = canonical_warp_group_idx() - NumLoadWarpGroups;// Perform reduction across splits, if neededTileScheduler::fixup(params.scheduler, work_tile_info, accumulators, NumMmaWarpGroups, consumer_warp_group_idx);if (TileScheduler::compute_epilogue(work_tile_info, params.scheduler)) {// Epilogue and write to gDauto [epi_load_pipe_consumer_state_next, epi_store_pipe_producer_state_next] =collective_epilogue.store(epi_load_pipeline,epi_load_pipe_consumer_state,epi_store_pipeline,epi_store_pipe_producer_state,problem_shape_MNKL,blk_shape,blk_coord,accumulators,tiled_mma,mma_thread_idx,shared_storage.tensors.epilogue);epi_load_pipe_consumer_state = epi_load_pipe_consumer_state_next;epi_store_pipe_producer_state = epi_store_pipe_producer_state_next;do_store_tail = true;}// Get next work tileauto [next_work_tile_info, increment_pipe] = scheduler.fetch_next_work(work_tile_info);work_tile_info = next_work_tile_info;
显然,前面的说法站不住脚。笔者在搜索了大量的资料后,找到了CUTLASS的一个Issue:
这个Issue讲明了其中的原因:对于Cooperative Kernel来说,Producer Warp Group每次进行数据拷贝的时候,是利用单个TMA请求为两个Consumer Warp Group拷贝一整块的数据,只要数据一到达,两个Warp Group就会同时开始工作,在Cooperative Kernel中,并未对这两个Warp Group的执行顺序进行任何限制,而是放任他们以一种“竞争”的姿态争抢TensorCore资源完成计算,通常,对于两个Warp Group来说,这种竞争都是一种“势均力敌”的状态,一般不会出现一个Warp Group的执行进度显著的领先于另一个Warp Group的情况。
更何况,有限的StageCount也会将Warp Group执行进度的差异控制在StageCount以内,因为两个Warp Group依赖于相同的数据,即使一个Warp Group早早的完成了自己的StageCount个计算任务,也必须要等待另一个Warp Group也完成StageCount个计算任务,才可以释放Shared Memory Buffer允许Producer Warp Group填充新的数据。因此,两个Warp Group在Mainloop阶段的执行进度不会有太大的差异,即使有差异,最大也不会超过流水线级数StageCount,结束Mainloop执行的时刻也是相近的,显然,这样肯定是无法有效的Overlap掉Epilogue的。前文的图1中也表明,两个Warp Group几乎是同时开始执行Mainloop和Epilogue的。
在此基础上,我们可以和Pingpong调度策略进行对比,在Pingpong调度策略中,由于两个Consumer Warp Group负责计算不同的Output Tile,因此它们的输入数据也是完全独立的,对于任意一个Consumer Warp Group,只要它的输入数据消费完毕,Shared Memory Buffer就可以立即释放,并不会受到另一个Consumer Warp Group的影响。
显然,此时两个Warp Group可以以任意的顺序执行,但是为了避免出现Cooperative中那种“势均力敌”的情况导致Epilogue无法被有效的Overlap,Pingpong调度策略引入了Ordered Sequence Barrier(https://github.com/NVIDIA/cutlass/blob/main/include/cutlass/pipeline/pipeline.hpp)用于强制约束两个Warp Group的执行顺序:
// Order two Math WG's MMA one after the other, helps hide Epiloguemath_wg_order_barrier.wait();collective_mainloop.mma(mainloop_pipeline,mainloop_pipe_consumer_state,accumulators,k_tile_count,warp_group_thread_idx,shared_storage.tensors.mainloop,params.mainloop);// Cue for next Math WG's MMA to startmath_wg_order_barrier.arrive();
从代码中我们可以观察到,Ordered Sequence Barrier的wait和arrive强制一个Warp Group完成自己的Mainloop后,另一个Warp Group才可以执行自己的Mainloop。两个Warp Group的Mainloop执行阶段是完全错开的,因此可以用一个Warp Group的Mainloop执行阶段Overlap另一个Warp Group的Epilogue。
总结
本文通过现象和代码两个角度,分析了Pingpong调度策略在多数场景下性能优于Cooperative调度策略的原因。
当然,Pingpong调度策略也并不是万能的,在Mainloop本身执行时间就很短的情况下(K维度很小),单个Mainloop难以Overlap Epilogue,此时我们通过实验发现Cooperative调度策略的性能可能会更好,关于其原因,我们正在分析,后续会进一步以文章的形式进行发布,感兴趣的读者可以持续关注。
下集预告
在本文开头我们已经说明,在K维度较小的情况下,DeepGEMM的性能优于CUTLASS,原因有两点:
-
DeepGEMM会使用算术强度更大的QGMMA指令
-
CUTLASS的Epilogue中进行了不必要的LinearCombination
在接下来的文章中,我们将会介绍上述两点原因的分析过程,另外,对于第二点原因,我们已经在SGLang中进行了优化,感兴趣的读者可以参考这个PR:
同时,也欢迎各位大佬在评论区展开讨论,批评指正。
– The End –

长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!
(文:GiantPandaCV)