

鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
首个基于混合Mamba架构的超大型推理模型来了!
就在刚刚,腾讯宣布推出自研深度思考模型混元T1正式版,并同步在腾讯云官网上线。
对标o1、DeepSeek R1之外,值得关注的是,混元T1正式版采用的是Hybrid-Mamba-Transformer融合模式——
这是工业界首次将混合Mamba架构应用于超大型推理模型。

根据腾讯官方介绍,通过大规模强化学习,并结合数学、逻辑推理、科学和代码等理科难题的专项优化,混元T1正式版进一步提升了推理能力,与此前已上线腾讯元宝的混元T1-preview相比,综合效果明显提升。
在MMLU-pro、CEval、AIME、Zebra Logic等中英文知识、竞赛级数学,以及逻辑推理公开基准测试中,混元T1均有比肩DeepSeek R1和OpenAI o1的分数。
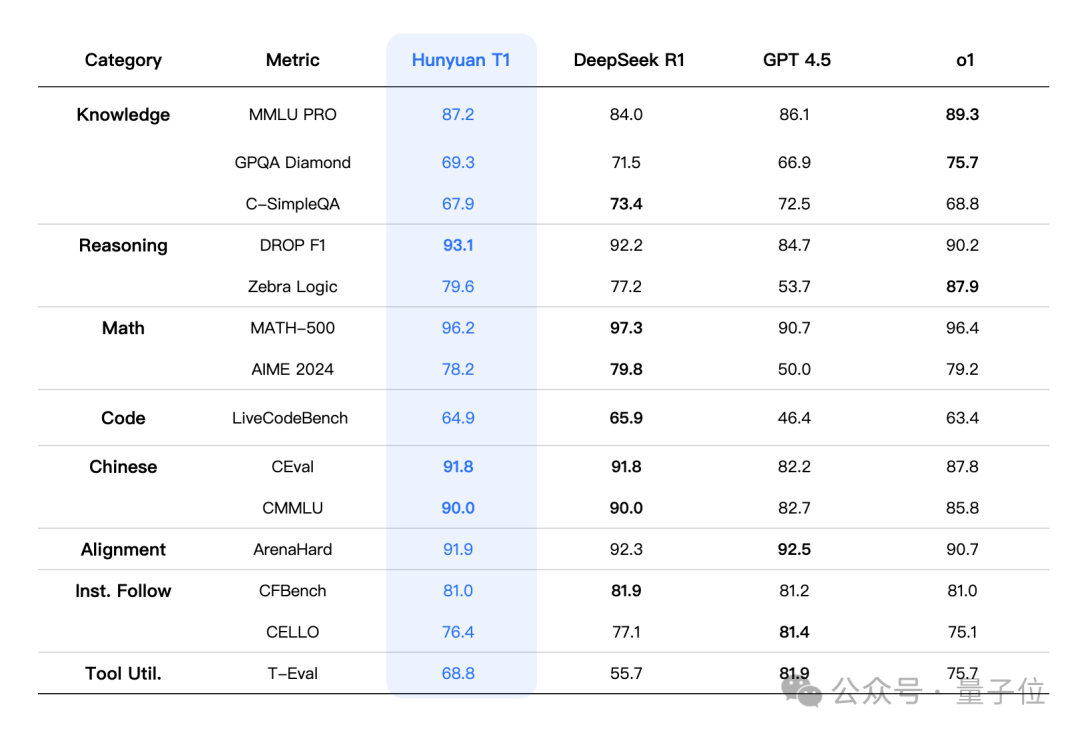
(表格中,其它模型评测指标来自官方评测结果,官方评测结果中没有的部分来自混元内部评测平台结果)
另外,在最新大模型竞技场中,混元T1正式版的基础模型Turbo S已经跻身全球TOP 15。这意味着在其基础上的推理版本T1正式版理论上会有更强大的表现。
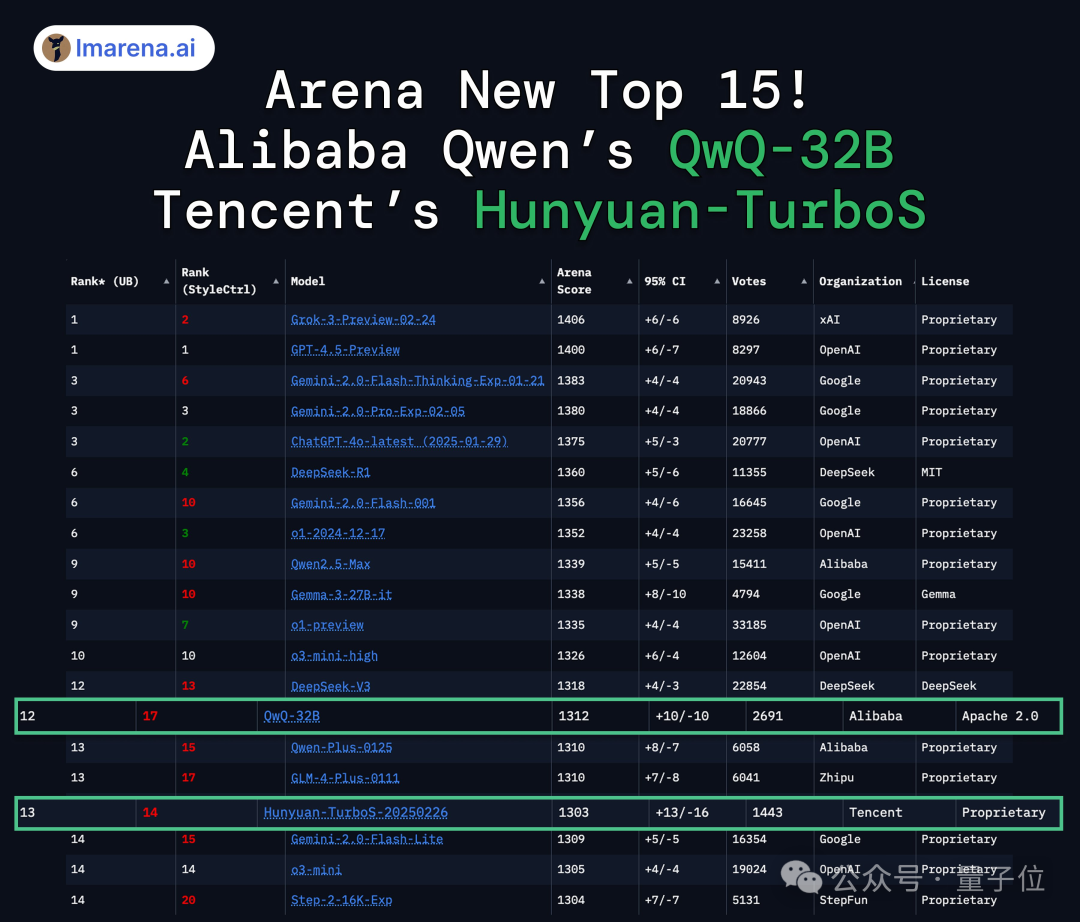
首个基于混合Mamba架构的超大型推理模型
具体来说,混元T1正式版沿用了混元Turbo S的模型架构,采用的是Hybrid-Mamba-Transformer融合模式。
混元Turbo S是腾讯自研的快思考模型——
区别于DeepSeek R1等慢思考模型,Turbo S更强调“秒回”,即吐字速度更快,首字时延更低。
非传统Transformer架构的好处在于,能有效降低Transformer架构的计算复杂度,减少KV-Cache缓存占用,实现训练和推理成本的下降。
新的融合模式一方面发挥了Mamba高效处理长序列的能力,另一方面保留了Transformer擅长捕捉复杂上下文的优势,突破的传统Transformer架构在长文训练和推理成本方面面临的难题。
腾讯官方没有透露更多技术细节,但可以参考Mamba-2论文做一个简单的理解:
在Mamba-2中,研究团队发现,Transformer中的注意力机制与SSM(结构化状态空间模型)存在紧密的数学联系,两者都可以表示为可半分离矩阵(Semiseparable Matrices)的变换。
基于这个发现,Mamba-2的作者提出了SSD(结构化状态空间二元性)理论,把Transformer和Mamba给打通了:
SSD可以将Transformer架构多年积累起来的优化方法引入SSM。比如引入张量并行和序列并行,扩展到更大的模型和更长的序列;或是引入可变序列,以实现更快的微调和推理。
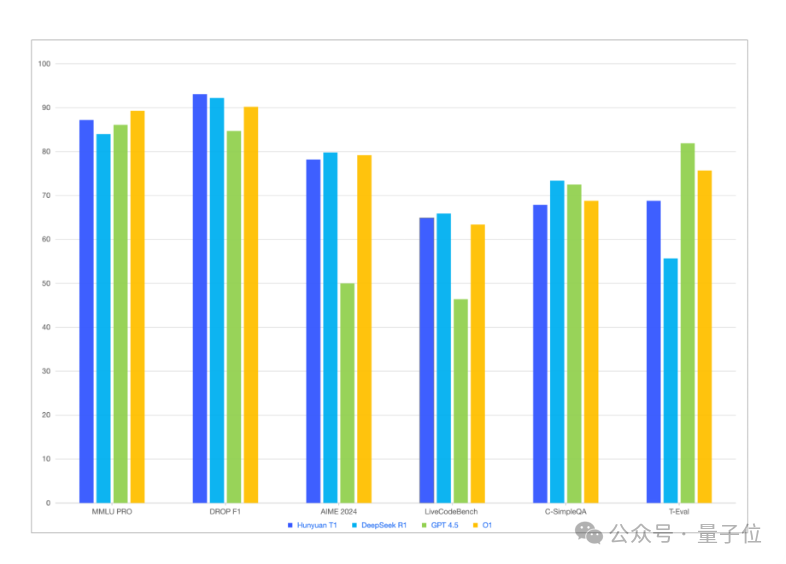
△混元T1正式版测评结果
目前,混元T1正式版已面向API用户,在腾讯云上线。
定价方面,输入价格为1元/百万tokens,输出价格为4元/百万tokens。
相较之下,DeepSeek R1在标准时段(北京时间8:30-00:30)的定价为4元/百万tokens输入,16元/百万tokens输出。
文心大模型X1的定价则是2元/百万tokens输入,8元/百万tokens输出。
也就是说,混元T1的价格仅为DeepSeek R1的四分之一,是文心大模型X1的一半。
体验入口也已释出:
https://llm.hunyuan.tencent.com/#/chat/hy-t1
此前,混元深度思考模型T1 Preview和快思考模型Turbo S,都很快在腾讯自家C端应用上线,包括腾讯元宝、腾讯文档、搜狗输入法、QQ浏览器等等。
那么T1正式版什么时候能和普通用户见面?
腾讯方面给量子位的回应是:C端未来可能更多通过元宝以及腾讯其他业务来服务。
感兴趣的话可以蹲一蹲了 。
。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
—
(文:量子位)