
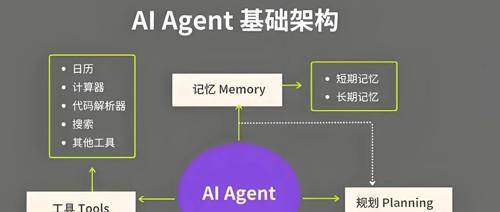
人工智能代理正迅速改变企业运营方式,它们能够自主解决问题、优化工作流程,并具备极强的可扩展性。然而,真正的难题并不是如何构建更强大的 AI 模型。
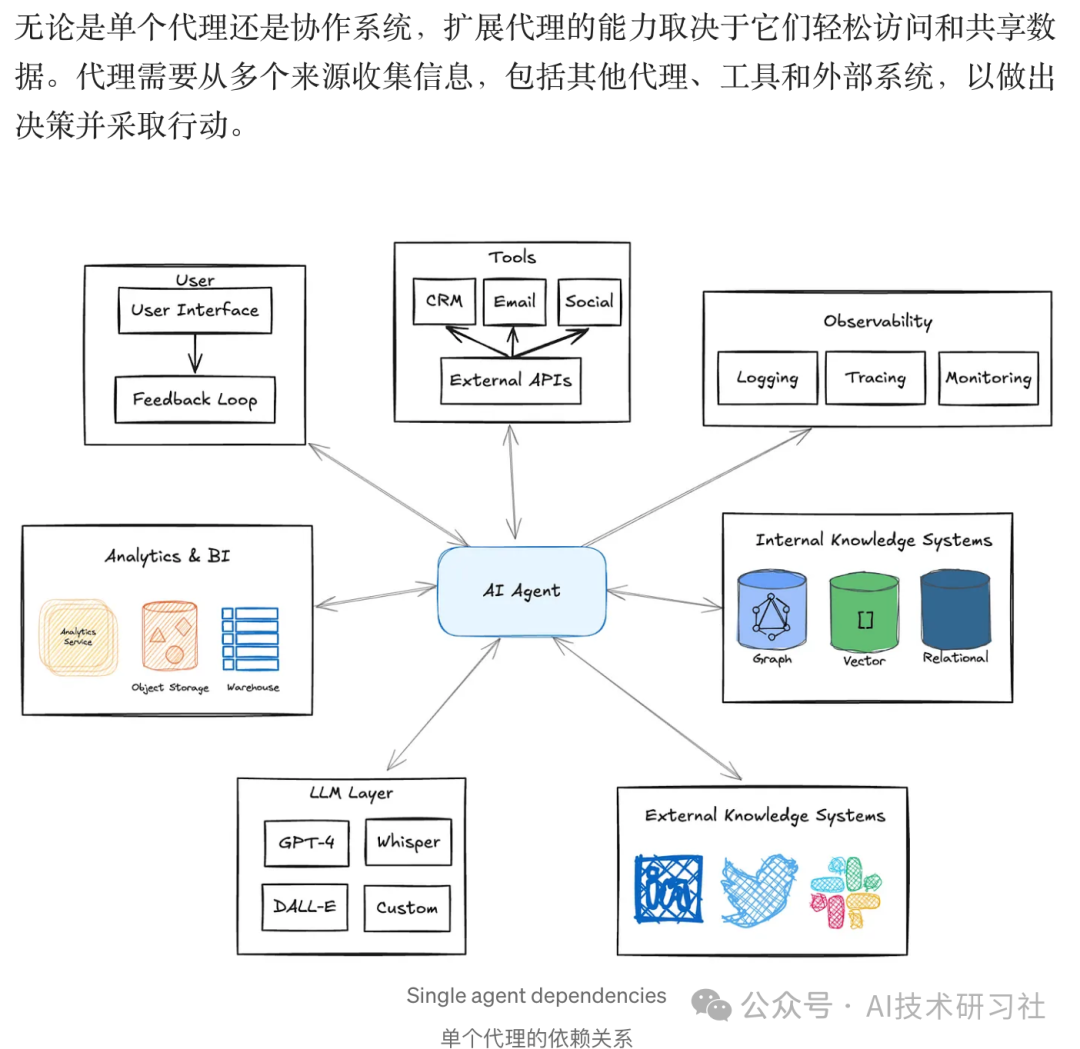
Agent 的核心能力不仅仅是大模型的推理,而在于 数据访问、工具调用,以及跨系统的信息共享。一个孤立的 AI 代理,就像是一座信息孤岛,无法发挥真正的价值。Agent 需要一个强大的基础设施,使其输出能够被多个服务(甚至其他 Agent)无缝调用。换句话说,这不是一个 AI 模型的问题,而是 基础设施与数据互操作性 的问题。
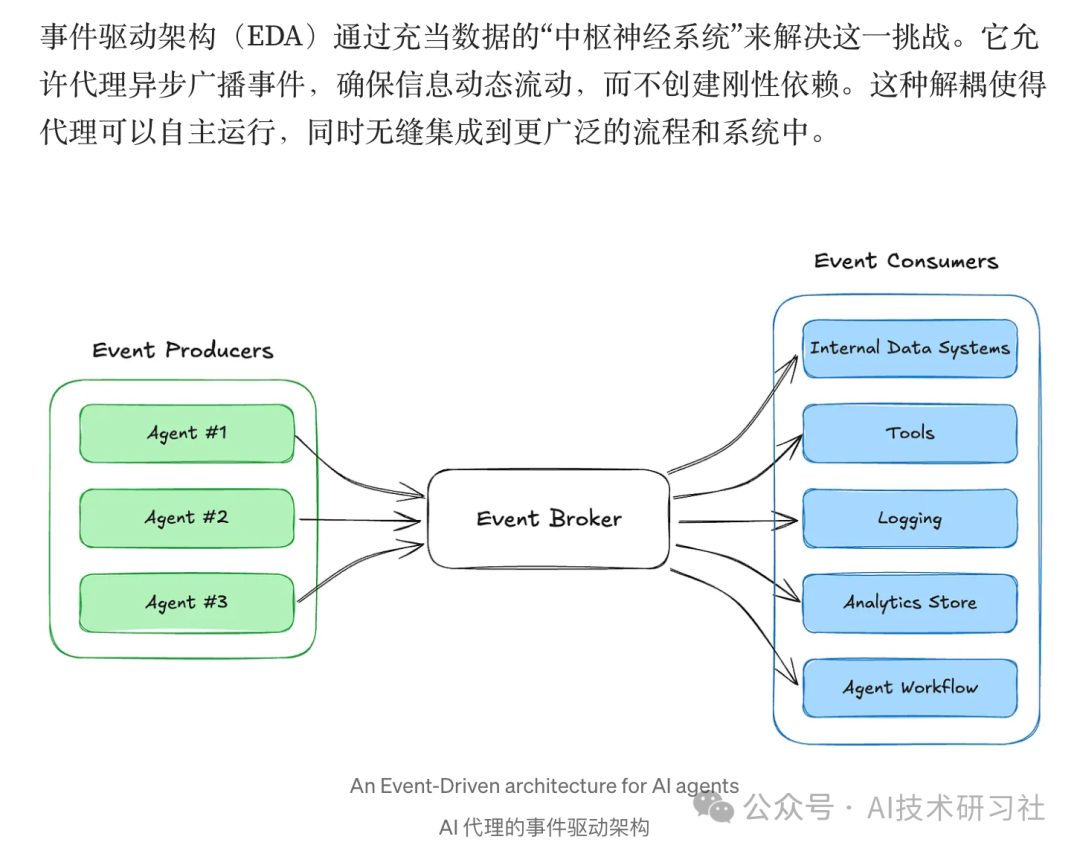
要让 Agent 真正发挥作用,我们不能只是拼接复杂的命令链,而是需要一个由数据流驱动的基于事件的架构(EDA)。如 HubSpot CTO Dharmesh Shah 所言:“Agent 是新的应用程序。”
本文将深入探讨 AI 代理的演变、EDA 如何赋能 Agent 生态,以及如何利用这一架构突破当前 AI 应用的局限,让 AI 代理真正成为企业级生产力工具。
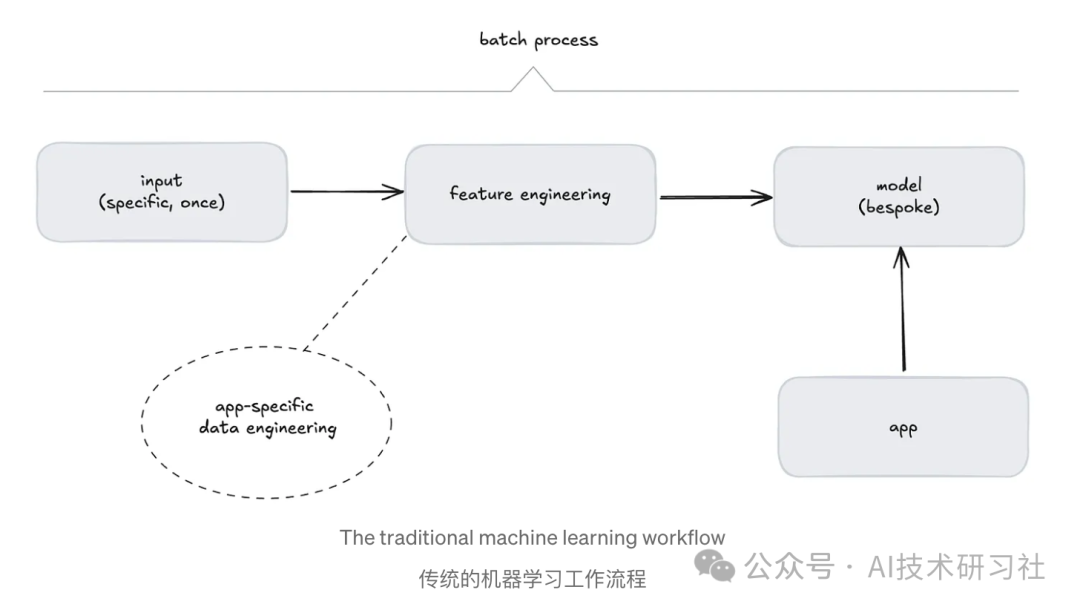
第二次浪潮:生成式 AI——智能的跃迁,但仍存局限。深度学习推动了生成式 AI(Generative AI)的崛起,使人工智能进入了全新的发展阶段。
不同于以往专注于特定任务的预测模型,生成式 AI 依托 大规模、多样化数据 训练,具备了跨领域的泛化能力。它可以生成文本、图像、代码甚至视频,为内容创作、编程辅助和自动化交互带来了革命性的突破。
然而,这一波浪潮也暴露了 生成模型的核心局限:
-
时间冻结 —— 生成模型的知识固定在训练数据的时间点上,无法主动获取和整合最新信息。
-
动态适应性差 —— 由于无法实时访问外部数据或更新知识,生成式 AI 在面对个性化需求或实时变化的环境时,响应往往 过于通用,甚至错误。
-
微调成本高昂 —— 针对特定领域进行微调(Fine-tuning)虽然可以改善表现,但 需要大量数据、计算资源和专业技术,并且容易引入偏差,成本极高。
例如,假设你希望 AI 基于用户的健康历史、所在地和财务目标 推荐最适合的保险方案。如果仅靠大语言模型(LLM),它只能基于训练时的数据生成一个 “大概率正确” 的答案,而无法访问用户的实际信息,从而导致建议要么 过于笼统,要么完全不准确。
为了克服这些限制,复合人工智能系统将生成模型与其他组件(如程序逻辑、数据检索机制和验证层)集成。这种模块化设计使人工智能能够结合工具、获取相关数据,并调整输出方式,这是静态模型无法做到的。
据报道,尽管 Google 的 Gemini 经过更大规模数据集的训练,但仍未达到内部预期。而 OpenAI 的下一代模型 Orion 也遭遇了类似的挑战。
Salesforce 首席执行官马克·贝尼奥夫在《华尔街日报》的 “Future of Everything” 播客中表示,LLM 可能已经接近能力上限。他认为,未来的突破点并不在于更强的大模型,而是能够自主思考、适应变化并独立执行任务的智能体(Agent)。
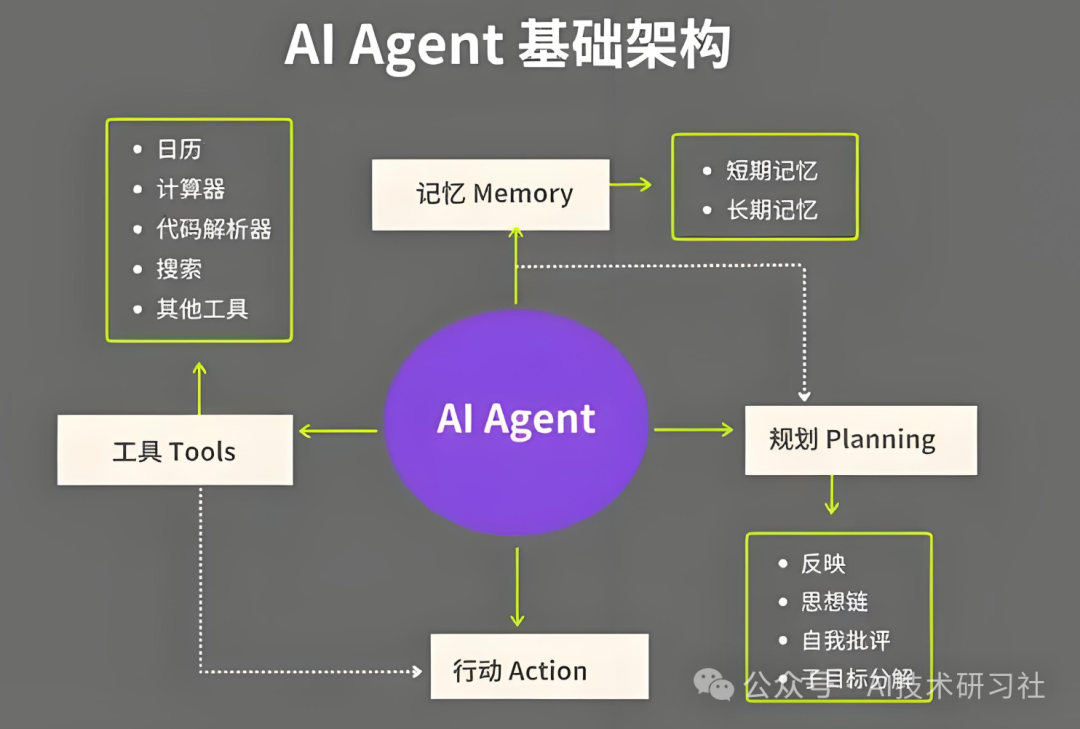
与传统 LLM 依赖固定路径不同,Agent 具备动态、上下文驱动的工作流。它们可以根据实时信息调整决策流程,灵活应对复杂且不可预测的问题。这使得它们在现代企业环境下,比静态的生成式 AI 更具竞争力。
换句话说,未来的 AI 进化方向,可能不再是“更大的模型”,而是“更智能的系统”。
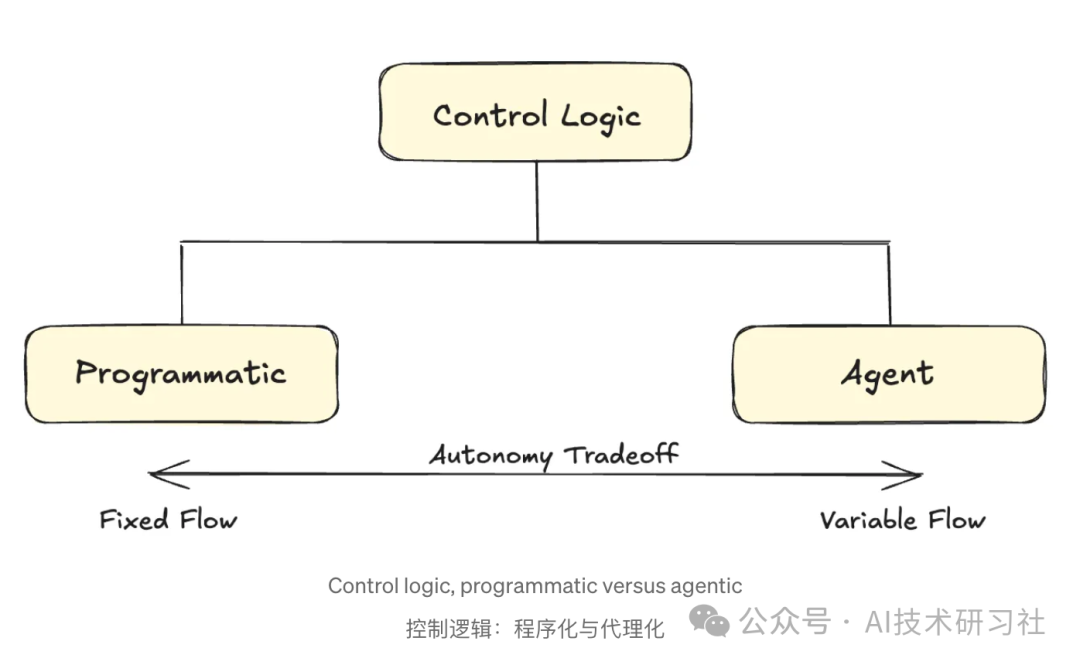
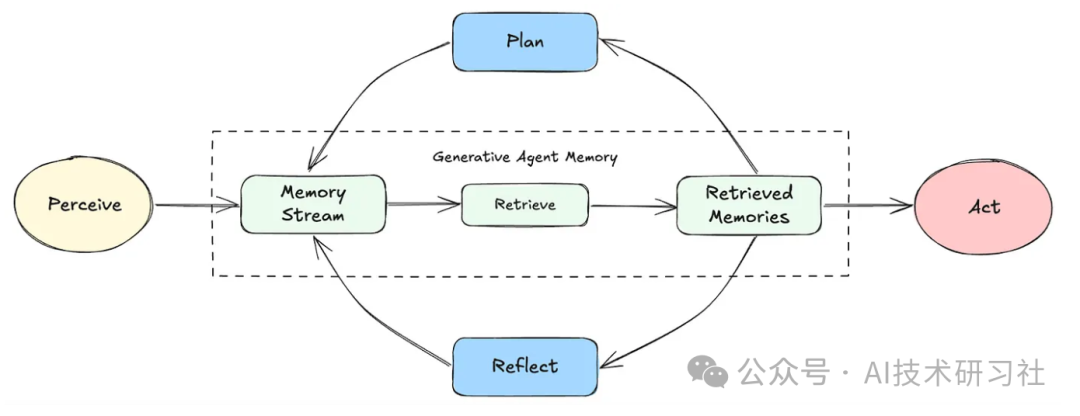
让我们来看看一些使Agent有效的一些常见设计模式。
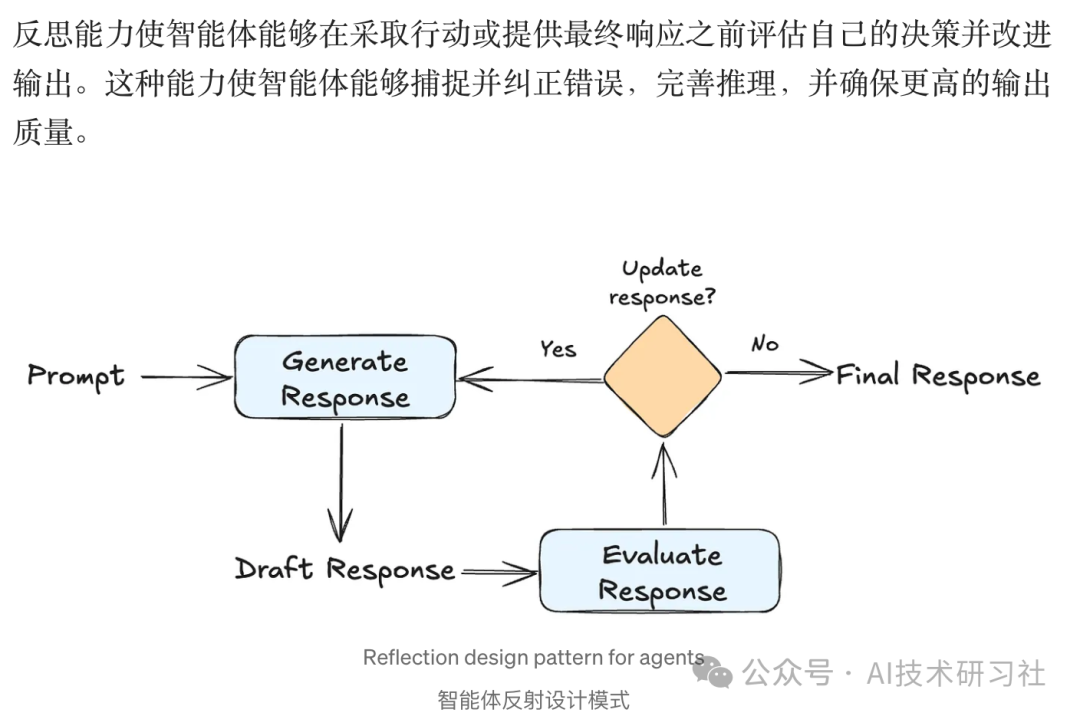
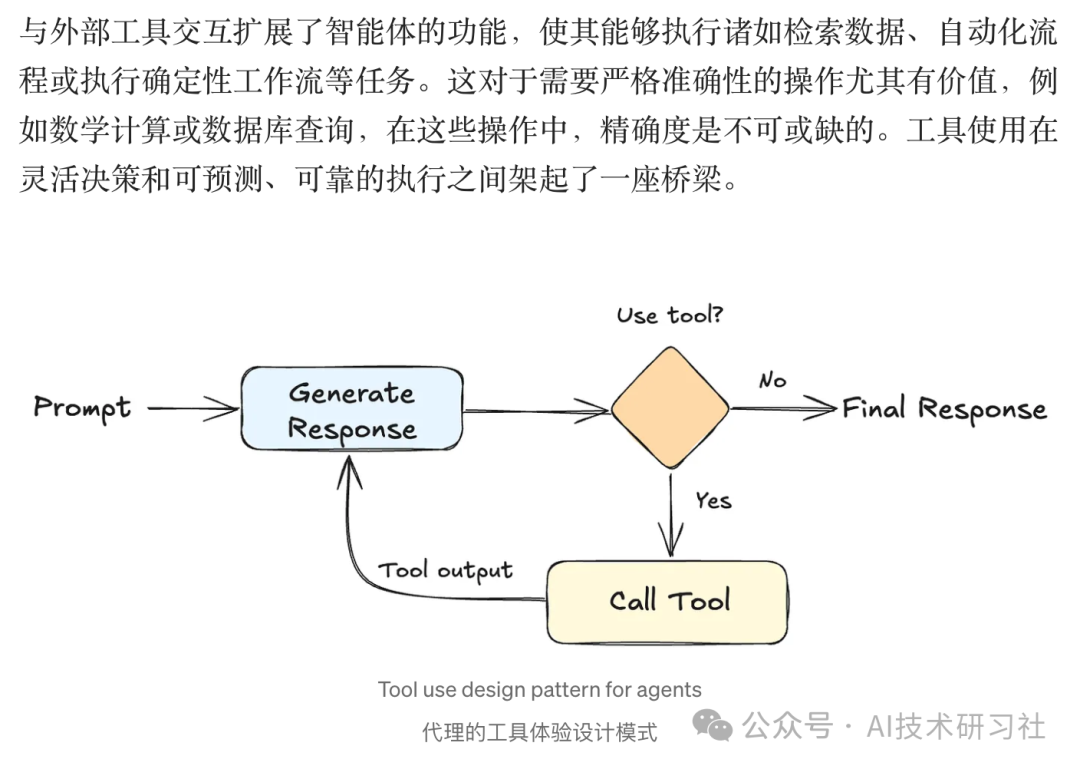
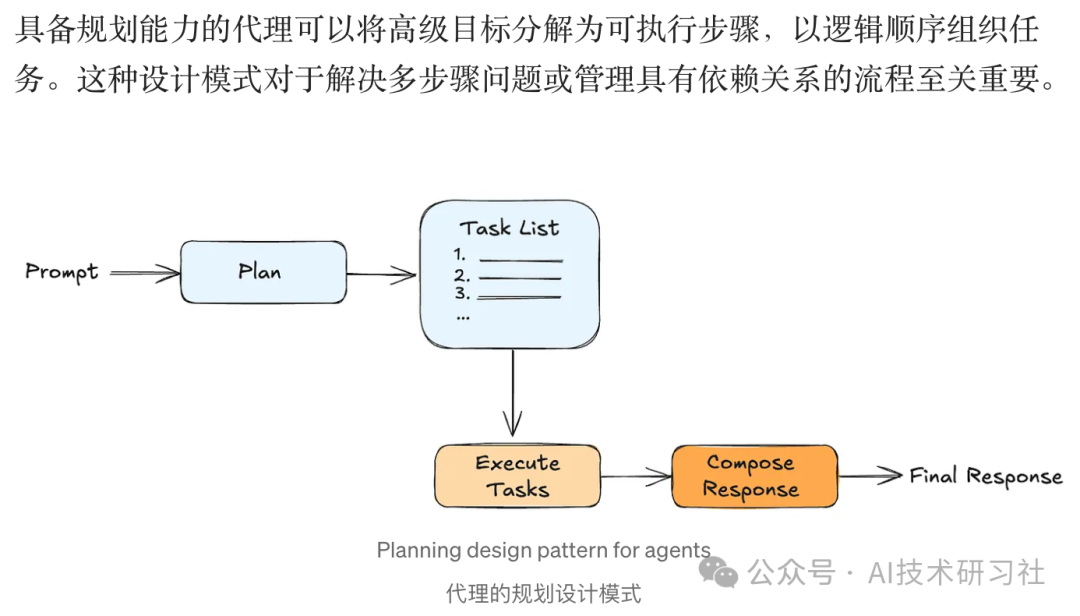
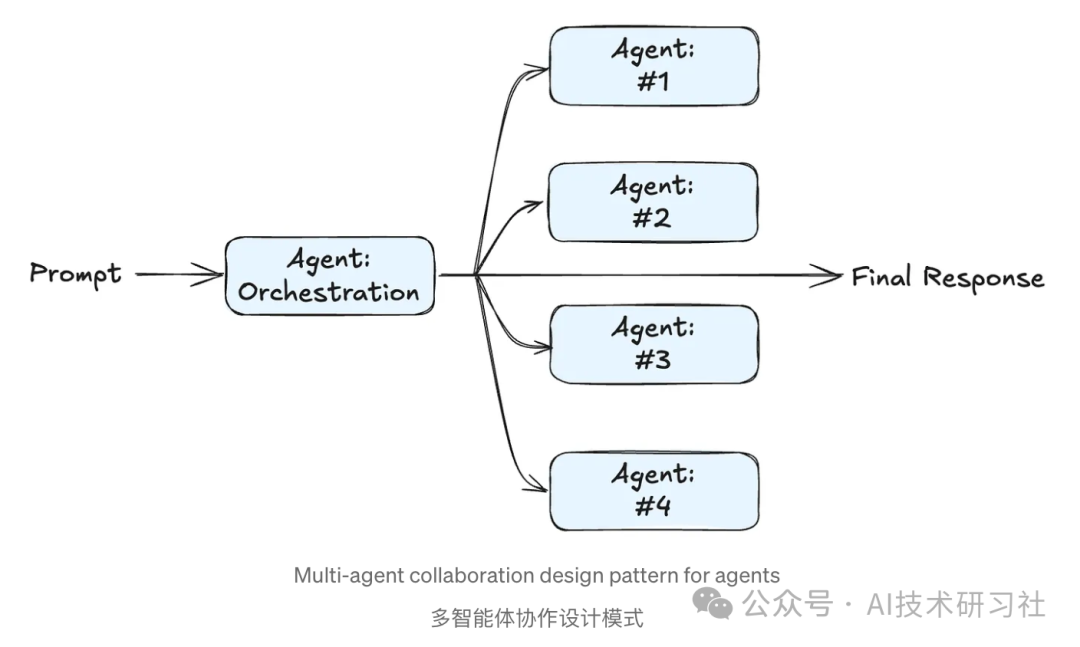
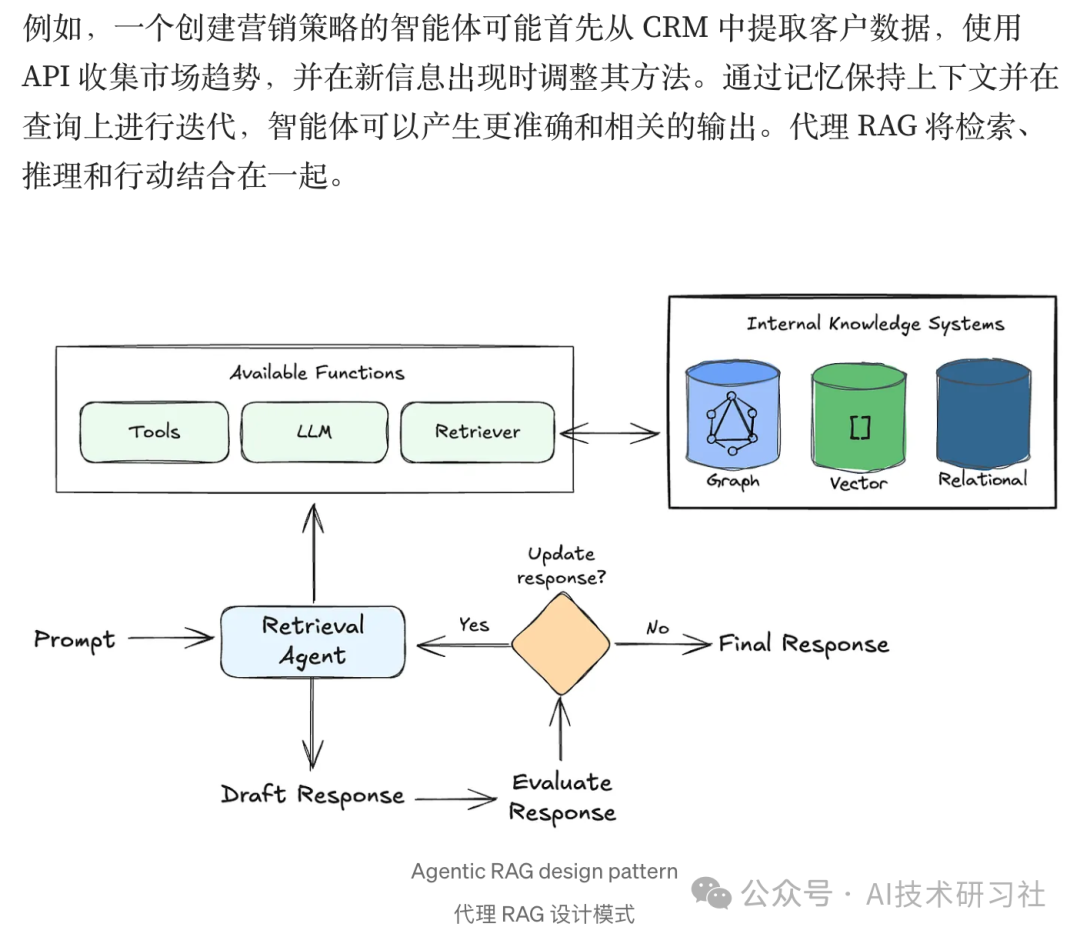
Agent 与 LLM 的对比:
-
LLM(大语言模型) 是基于历史数据生成输出,通常无法接入最新的数据或实时信息,适用于静态任务。
-
Agent 则能够访问外部数据、动态调整任务,适应不断变化的工作环境,特别适合应对复杂和多变的任务,如客户支持、流程优化和决策制定。
为何 Agent 是未来的方向:
-
解决不可预测问题:Agent 系统能够处理动态且复杂的任务,是应对现代企业挑战的关键。
-
提高生产力:通过自动化、智能化的工作流程,Agent 能够提高企业的效率和响应能力。
总的来说,Agent 是人工智能的未来方向,它不仅代表着更智能的系统,还为企业带来了更高效、更灵活的运营能力。
(文:AI技术研习社)