


刚刚腾讯正式推出了推理模型 混元-T1 !它基于3月初发布的业界首个超大规模 Hybrid-Transformer-Mamba MoE 大模型 TurboS 快思考基座打造!
简单来说,基于TurboS的T1就是为了解决大模型推理的痛点而生的:
-
• 长文理解能力: TurboS 能有效捕捉长文本信息,告别“上下文丢失”的尴尬,长距离依赖问题也轻松搞定! -
• Mamba架构加持,速度起飞: Mamba 架构专门优化了长序列处理,计算效率超高!相同条件下,解码速度直接快2倍
96.7%算力All in 强化学习
据腾讯官方公告后训练阶段,96.7%的算力都砸在了强化学习上!目标只有一个:极致提升模型的推理能力!对齐人类偏好!
为了练好T1的“脑子🧠”, 混元团队也是下了血本:
世界级理科难题喂饱: 数学、逻辑推理、科学、代码…各种硬核难题,从基础到复杂,应有尽有!还结合真实反馈,确保模型“真材实料”
“课程学习”+“上下文长度阶梯式扩展”: 就像给学生上课一样,难度循序渐进,同时逐步提升模型的“阅读理解”能力,让模型更高效地利用tokens进行推理
经典RL策略加持,训练更稳: 数据回放、阶段性策略重置… 这些经典RL“秘籍”让模型训练稳定性提升 50%以上!稳扎稳打,才能步步为营!
Self-rewarding + Reward Model 双管齐下,更懂人类心意: 用早期版本的T1-preview 给模型打分,再结合 reward model 反馈,引导模型自我提升!结果就是:回复内容更丰富,信息更高效!更贴心,更懂你!
🏆 性能:对标R1,部分能力还略胜一筹
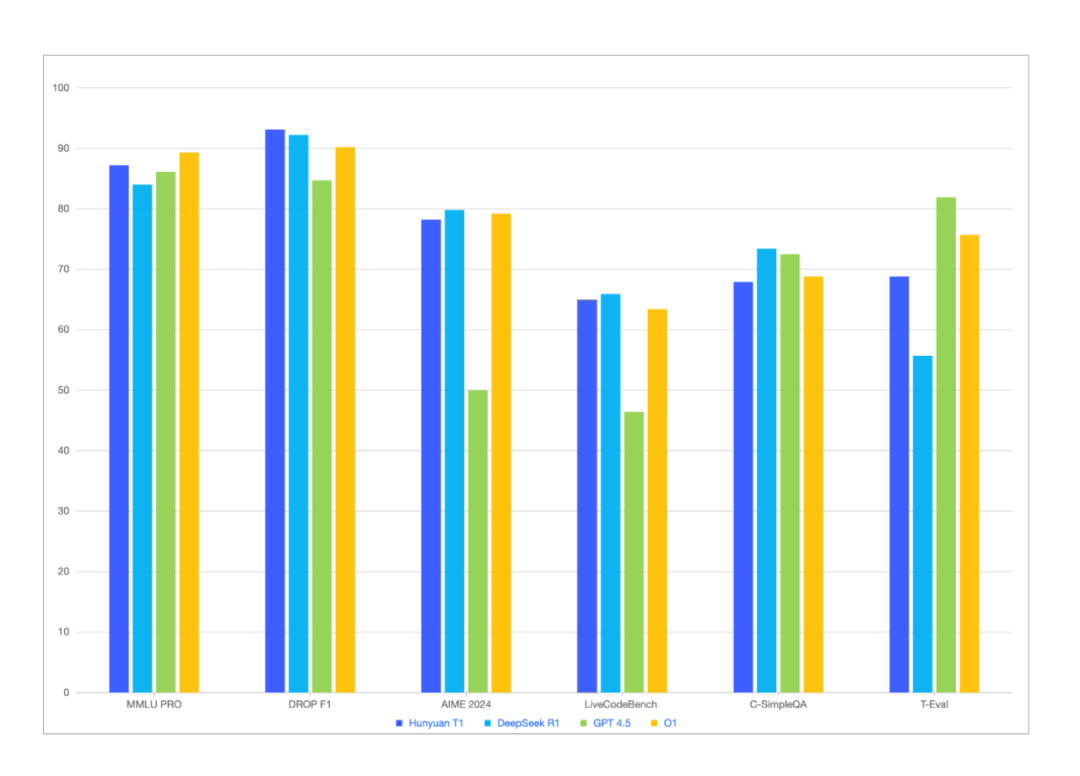
混元-T1 在各种权威benchmark 上,例如 MMLU-pro、CEval、AIME、Zebra Logic 等等,中英文知识和竞赛级数理逻辑推理指标,基本持平甚至略超 DeepSeek R1!
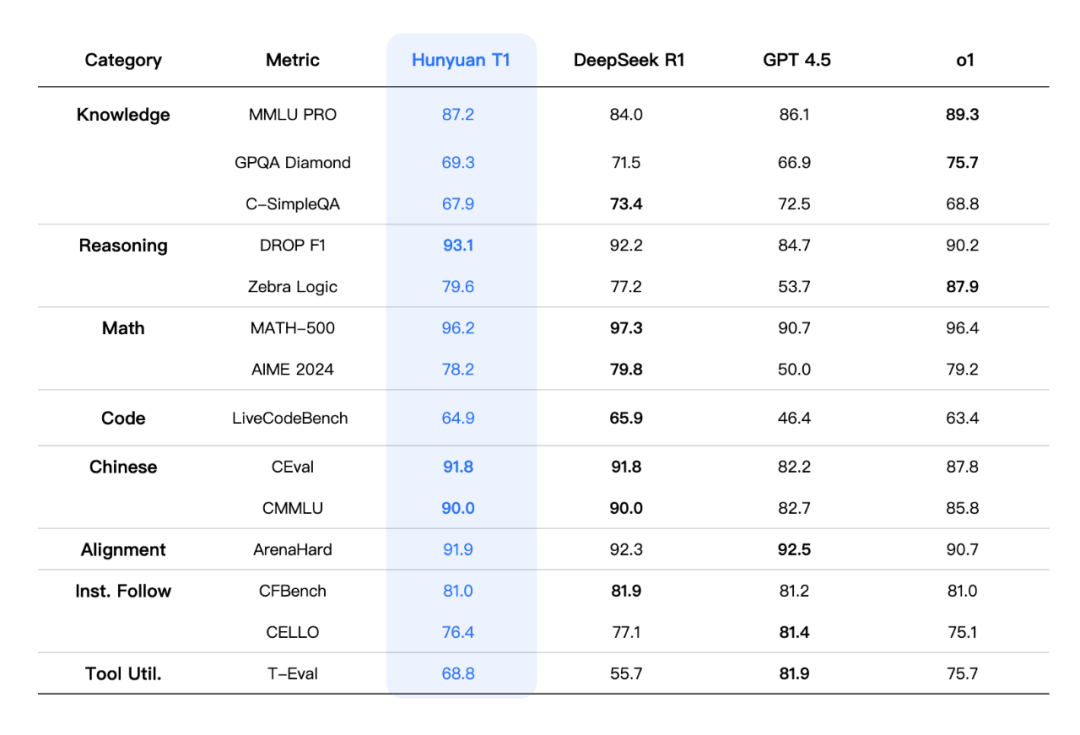
在内部人工体验集评估中,中文文案创作、文本摘要、Agent 能力等方面,T1 还略有优势!
实测
我用制作赛朋克贪吃蛇游戏来测试了一下T1,表现一般(顺便说一句,制作赛朋克贪吃蛇游戏是我测试所有推理模型比如DeepSeek R1,Grok 3,Claude 3.7,o1,o3 mini,Gemini 2.0 thinking 最常用一个测试题)
测试地址:
https://llm.hunyuan.tencent.com/#/chat/hy-t1
大家看看实测效果

这是测试结果:
⭐
(文:AI寒武纪)