

随着传统的人工智能基准测试技术显得力不从心,AI 构建者正转向更具创意的方法来评估生成式 AI 模型的能力。
对一群开发者而言,这个新舞台便是微软旗下的沙盒建造游戏——Minecraft。
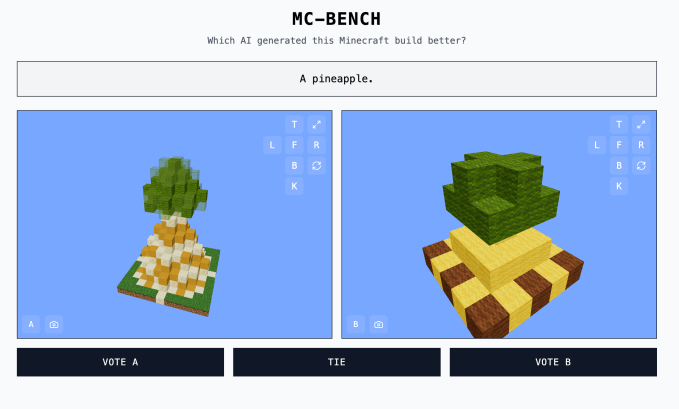
网站 Minecraft Benchmark(或 MC-Bench)是合作开发的,旨在让 AI 模型在直接挑战中相互竞争,以响应提示并创建 Minecraft 作品。用户可以投票决定哪个模型做得更好,只有在投票后才能看到每个 Minecraft 作品是由哪个 AI 制作的。
图片来源:Minecraft
对于发起 MC-Bench 的 12 年级学生 Adi Singh 来说,Minecraft 的价值并不在于游戏本身,而在于人们对它的熟悉程度。毕竟,它是有史以来最畅销的视频游戏。
即使是没有玩过游戏的人,仍然可以评估哪个方块化的菠萝表现得更出色。
“Minecraft 让人们更容易看到 AI 发展的进展,”Singh 告诉 TechCrunch。“人们已经习惯了 Minecraft,习惯了它的外观和氛围。”
MC-Bench 目前列出了八名志愿者贡献者。根据 MC-Bench 的网站,Anthropic、Google、OpenAI 和阿里巴巴已资助该项目,使用他们的产品来运行基准测试提示,但这些公司并无其他关联。
“目前我们只是在做一些简单的构建,以反思我们从 GPT-3 时代以来所取得的进展,但我们可能会看到自己扩展到这些更长的计划和目标导向的任务,”辛格说。
“游戏可能只是一个测试代理推理的媒介,它比现实生活中更安全,并且更可控,用于测试目的,在我看来更理想。”
其他游戏如《精灵宝可梦红》、《街头霸王》和《你画我猜》已被用作人工智能的实验基准,部分原因是人工智能基准测试非常棘手。
研究人员经常在标准化评估中测试人工智能模型,但许多这些测试为人工智能提供了主场优势。
由于它们的训练方式,模型天生擅长某些狭窄类型的问题解决,特别是需要死记硬背或基本外推的问题解决。
简而言之,很难理解 OpenAI 的 GPT-4 在 LSAT 考试中能排在第 88 百分位,却无法分辨“strawberry”这个词中有多少个 R。Anthropic 的 Claude 3.7 Sonnet 在标准化软件工程基准测试中达到了 62.3%的准确率,但在玩《宝可梦》方面却不如大多数五岁儿童。
图片来源:Minecraft
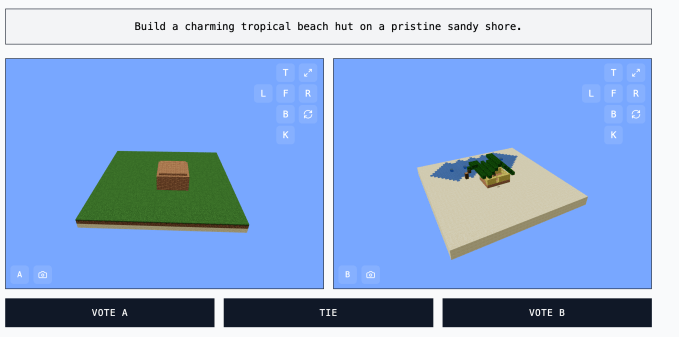
MC-Bench 在技术上是一个编程基准测试,因为模型被要求编写代码来创建提示的构建,比如“Frosty the Snowman”或“在原始沙滩上的一座迷人的热带海滩小屋”。
但对于大多数 MC-Bench 用户来说,评估一个雪人是否看起来更好比深入代码更容易,这使得该项目具有更广泛的吸引力——从而有可能收集更多关于哪些模型始终表现更好的数据。
当然,这些分数在多大程度上能反映 AI 的实用性还有待讨论。不过,辛格坚称它们是一个强有力的信号。
“当前的排行榜与我使用这些模型的体验非常接近,这与许多纯文本基准测试不同,”辛格说。“也许MC-Bench对公司来说是有用的,可以帮助他们了解是否走在正确的方向上。”
本文翻译自:https://techcrunch.com/2025/03/20/a-high-schooler-built-a-website-that-lets-you-challenge-ai-models-to-a-minecraft-build-off/
编译:ChatGPT
(文:Z Potentials)