


新智元报道
新智元报道
【新智元导读】视觉+语音=更强的语音识别!BPO-AVASR通过优化音视频输入和输出偏好,提升语音识别在真实场景中的准确性,解决了传统方法在噪声、口语化和视觉信息利用不足的问题。
自动语音识别(ASR)技术正在不断进步,但在真实世界的视频场景中,ASR仍然面临许多挑战,如噪声干扰、口语化表达、以及同音词混淆等问题。
那么,人们能否利用视觉信息来增强语音识别的准确性呢?

最近,来自中国人民大学及卡耐基梅隆大学的学者们在AAAI 2025会议上正式发布了他们最新的研究——BPO-AVASR(Bifocal Preference Optimization for Audiovisual Speech Recognition)。
这是一种全新的双焦点偏好优化方法,能够有效提升多模态语音识别(AV-ASR)系统的性能,使其在真实世界视频场景下的表现更加强大!

代码地址:https://github.com/espnet/espnet
语音识别的「视觉外挂」:为什么要结合视觉?
-
背景噪声问题:咖啡厅、地铁、机场等嘈杂环境会干扰ASR的准确性。
-
口语化表达:自发性语音中包含大量连读、省略等非标准表达,例如「gonna」代替「going to」。
-
同音词歧义:例如,「dark」和「duck」,仅依赖音频可能会导致错误识别。
视觉信息,尤其是视频中物体、背景信息、文本等,能提供额外的线索来帮助ASR模型更精准地理解语音内容。例如,看到屏幕上出现了一瓶「可口可乐」,ASR 识别「cola」而非「caller」的可能性会更高。因此,AV-ASR(音视频语音识别)应运而生,结合视觉与语音信息,提升识别准确性。
双焦点偏好优化(BPO)
-
未充分利用视觉信息:许多AV-ASR模型虽然引入了视觉特征,但并未明确优化模型在视觉线索上的利用能力。
-
难以适应真实世界的视频场景:大多数方法仅在干净的数据集上训练,泛化能力有限。
-
忽略真实环境中的常见错误:例如噪声影响、口语化表达、视觉信息缺失等问题。
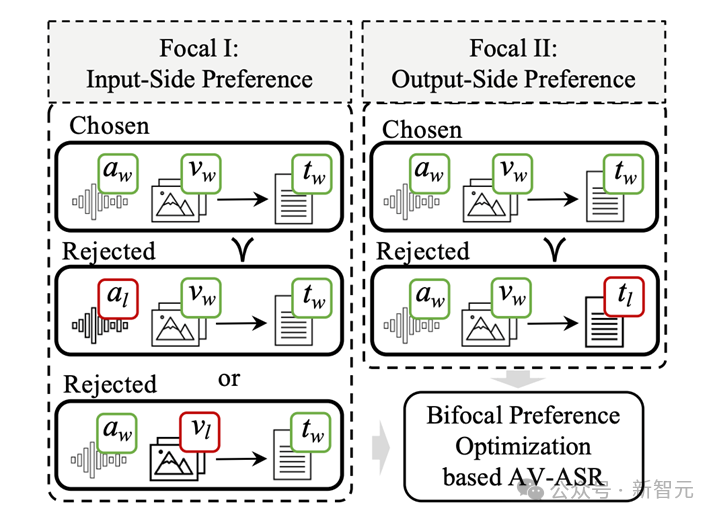
输入端偏好优化(Focal I):通过遮挡音频或扰动视频信息,模拟现实世界中的干扰因素,使模型学会如何在音视频信息缺失时做出更准确的预测。
输出端偏好优化(Focal II):通过引入AI生成的错误文本(如同音词替换、语音模糊重写等),让模型学习如何避免这些常见的识别错误。
换句话说,不仅要让模型学会「看」和「听」,更让它学会如何在信息不完整或错误的情况下做出更好的决策,从而更好地在多模态的场景下同时利用视觉和听觉信息识别出准确的文本。
如何构造偏好数据?
BPO-AVASR架构概览
BPO-AVASR通过构造偏好数据来优化ASR,主要涉及输入端优化和输出端优化。
输入端偏好数据构造(Focal I)
目标:让模型学会如何处理不完整的音视频信息,提升对噪声、模糊信息的适应能力。
-
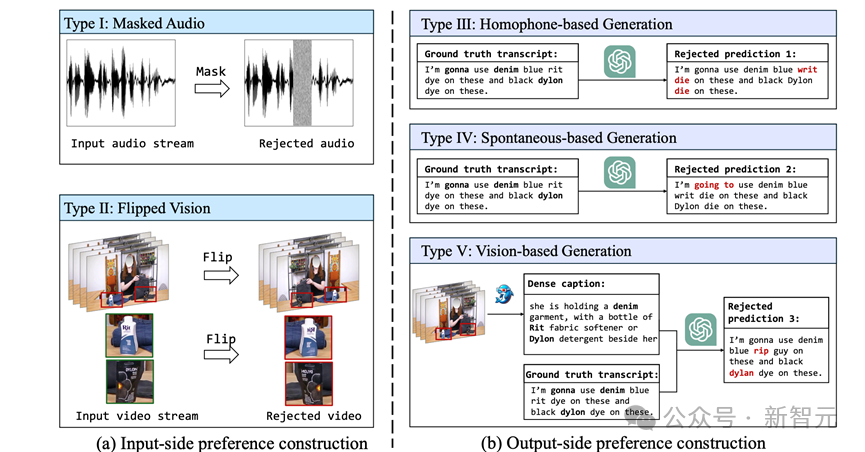
掩蔽音频(Masked Audio):随机遮挡部分音频帧,模拟噪声环境。
-
翻转视觉(Flipped Vision):对视频帧进行翻转,使视觉信息变得更难解析,以模拟视角变化的影响。
输出端偏好数据构造(Focal II)
目标:让模型学习如何避免常见的识别错误,优化ASR预测文本的准确性。
-
同音词替换(Homophone-based Generation):生成同音词错误,如「die」→「dye」。
-
口语化改写(Spontaneous-based Generation):生成口语化改写错误,如「gonna」→「goingto」。
-
视觉信息忽略(Vision-based Generation):让ChatGPT生成忽略视觉信息的错误文本,例如视频中的「dylon」被误识别为「dylan」。
偏好数据构造方法
实验结果与结论:BPO-AVASR让ASR更强大!
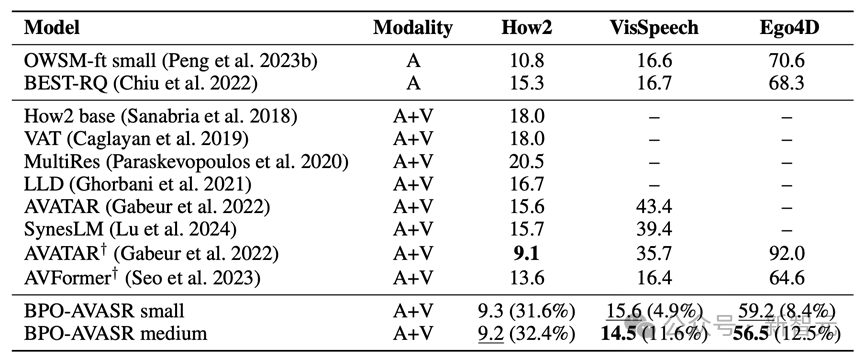
实验结果表明,BPO-AVASR在大部分测试数据集上取得了SOTA(State-of-the-Art,最优)性能,尤其在嘈杂环境和复杂视频场景下表现出色。例如:
-
在Ego4D数据集上,相比于现有的AV-ASR模型,BPO-AVASR的识别错误率(WER)降低了12.5%!
-
在How2数据集上,BPO-AVASR仅使用300小时的数据,就超越了使用131K小时数据训练的SOTA模型AVFormer!

未来展望:让 AI 更懂「看」与「听」
-
构建更大规模的开放域 AV-ASR 数据集,提升模型在各种场景下的泛化能力。
-
探索更复杂的音视频理解,以多模态语音识别为基础,在更多的跨模态交互任务上提升复杂场景理解的能力。
(文:新智元)