
今天是2025年3月25日,星期二,北京,天气晴。
今天我们回到文档解析这个话题,看两个,一个是文档版式分析模型PP-DocLayout,一个是基于版式分析的PDF文档翻译的两个项目。
项目之余,看看技术实现,会有更多收获。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、文档版式分析模型PP-DocLayout
文档版式分析,百度paddle团队写了个论文《PP-DocLayout: A Unified Document Layout Detection Model to Accelerate Large-Scale Data Construction》,(https://arxiv.org/pdf/2503.17213),为了满足不同的需求,提供了三种不同比例的模型,涉及文档的23个标签。
论文里面有几个论述写的很好,现有的版面检测模型面临三个关键限制。
(1) 不同文档类型的泛化能力差。当前的方法主要集中在学术论文上,在其他类型的文档(如杂志、报纸和财务报告)上的表现不佳。
(2) 对复杂布局处理不足。缺乏全面的类别定义。例如,缺少内联和行间数学公式的单独标签,需要辅助模型,这增加了复杂性并降低了效率。
(3) 实时应用的处理速度不足。这些挑战阻碍了版面检测在实际场景中的有效使用,特别是在需要高效获取大量高质量数据以训练大型模型的领域中。
首先,大多数现有方法专注于特定类型的文档,例如学术论文,并缺乏对杂志、报纸和手写笔记等多样化文档类别的泛化能力。
其次,对细粒度元素(如公式、脚注和页眉)的检测仍缺乏深入研究。
最后,版面检测方法的计算效率仍然是一个重大挑战,因为许多最先进的模型在计算上昂贵且速度慢,限制了它们在实时或大规模文档处理场景中的应用
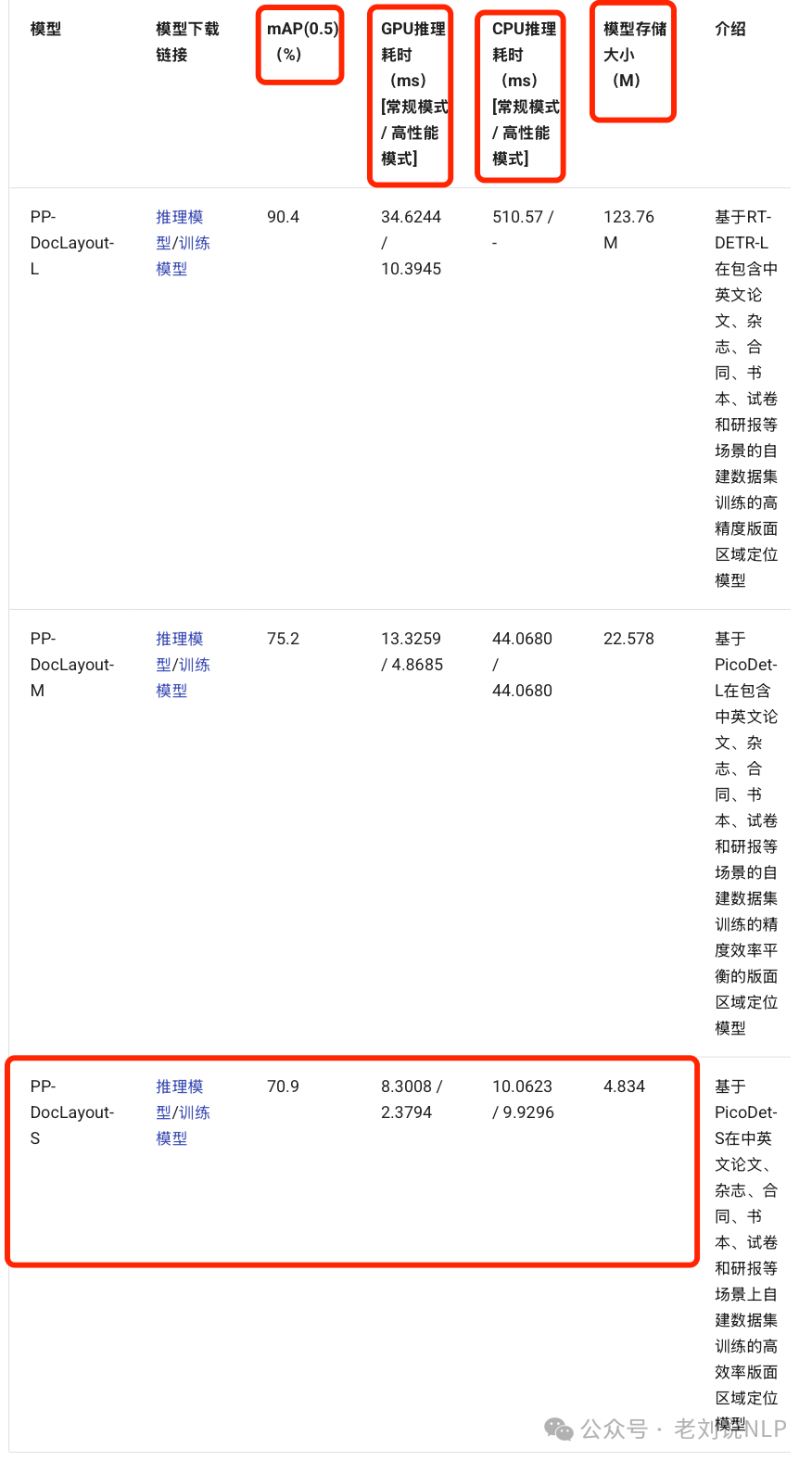
PP-Doclayout-L是基于RT-DETR-L检测器的高精度模型,指标90.4%mAP@0.5,在T4 GPU上,每页13.4毫秒;PP-Doclayout-M是一个平衡模型,指标75.2%mAP@0.5,在T4 GPU上,每页的推理时间为12.7ms;PP-Doclayout-S是一个高效模型,专为资源受限的环境和实时应用而设计。
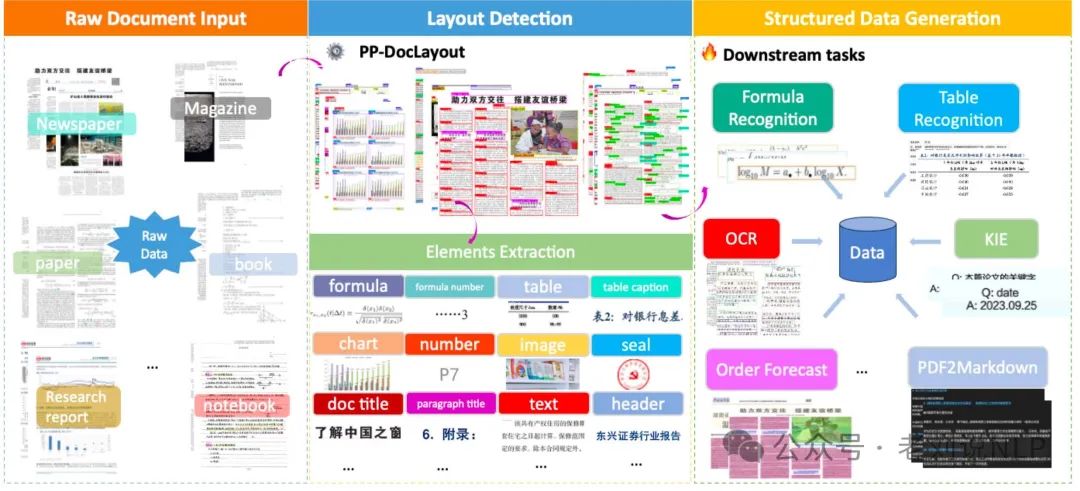
T4 GPU每页的推理时间为8.1毫秒,CPU每页的推理时间为14.5毫秒,https://github.com/PaddlePaddle/PaddleX。
核心思想是视觉编码部分特征蒸馏GOT2.0的VIT部分+伪标注半监督学习,23个细分标签,3w个训练样本。
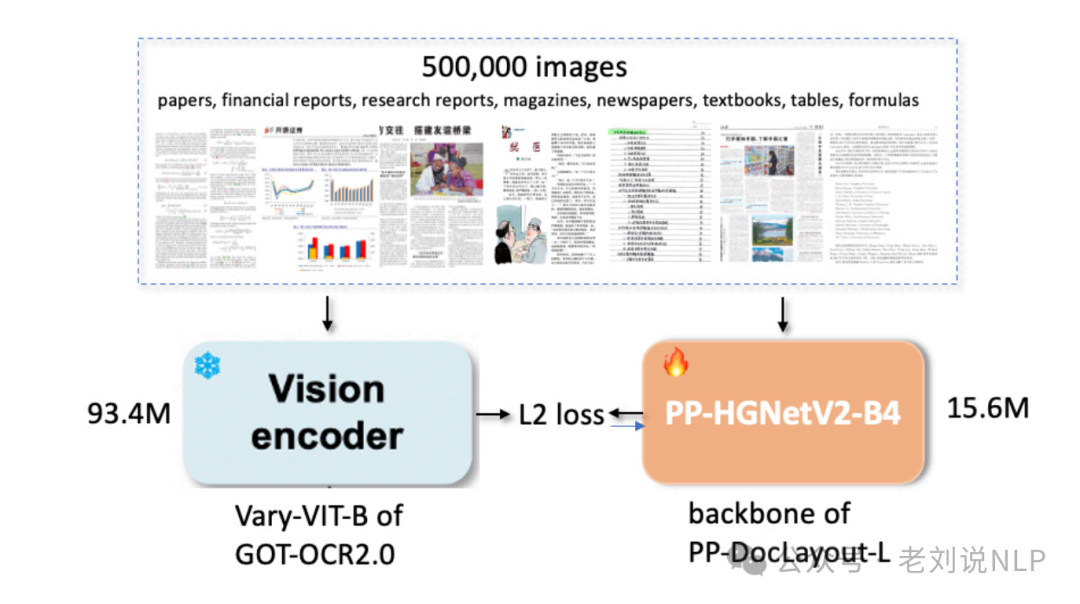
其中,PP-DocLayout-L采用知识蒸馏范式来提升文档布局理解的性能,在这个框架中,GOTOCR2.0中的视觉编码器Vary-VIT-B模型作为教师模型,学生模型使用PPDocLayout-L的PP-HGNetV2-B4主干网络,其设计目的是从教师模型学习,用的是特征蒸馏;
训练数据方面,蒸馏框架在包含五个领域的500,000份文档样本的多样化语料库上进行了训练,包括数学公式(包括方程推导和符号表示);财务文件(报告和资产负债表);科学文献(STEM领域的arXiv论文);学术论文(具有复杂布局结构的);表格数据(统计报告和电子表格)训练在768×768分辨率下进行,共50个轮次;
但是,落地价值不大,版式分析一般标签越多,漏检概率会大,泛化性会更差。三个版本中,L太慢,S精度不行。
当然,目前的模型包括doclayout以及360layoutanalysis等。
大家的差异点不大,都是标签设计以及数据标注上的差别。
二、基于版式分析的PDF文档翻译的两个项目
关于PDF文档翻译的开源项目,目前其实有一些开源实现了,现在来看两个,都是基于mineru方案做的。
1、fast_pdf_trans
基于MinerU实现pdf转markdown的功能,接着对markdown进行分割,送给大模型翻译,最后组装翻译结果并由pypandoc生成结果pdf。
特点在于:支持由pdf书签生成markdown标题(分级),魔改MinerU实现;支持移除markdown代码块的非标题#号,魔改MinerU实现;支持由大模型对MinerU生成的标题进行分级和过滤(无书签的场景;支持由大模型移除误识别的公式,魔改MinerU实现。
地址:https://github.com/kv1830/fast_pdf_trans
2、PDFMathTranslate
PDF scientific paper translation with preserved formats-基于AI完整保留排版的PDF文档全文双语翻译,保留公式、图表、目录和注释。
使用Pdfminer.six等库解析PDF文档,提取文本、公式和图表。布局分析基于DocLayout-YOLO等技术进行布局分析,识别文档中的不同元素(如文本块、公式、图表)及其位置。
核心解析地址在:https://github.com/Byaidu/PDFMathTranslate/blob/main/pdf2zh/converter.py

地址:https://github.com/Byaidu/PDFMathTranslate
当然,社区有成员利用给定arxiv pdf,从原arxic.org网页中获取latex,而后写入pdf,保真度较高,思路不错。
(文:老刘说NLP)