

凭借独特的适应性和灵活性,四足机器人等腿式机器人一直被视为是在高难度环境中实现复杂任务的理想平台。随着技术的进步,从日常生活协助到复杂任务执行,四足机器人等腿式机器人在越来越多场景被广泛应用。
然而,在执行如滑板运动、拳击等具有高度动态性和不确定性的接触任务时,腿式机器人的控制仍面临诸多挑战。
▍提出DHAL框架,结合双重优势
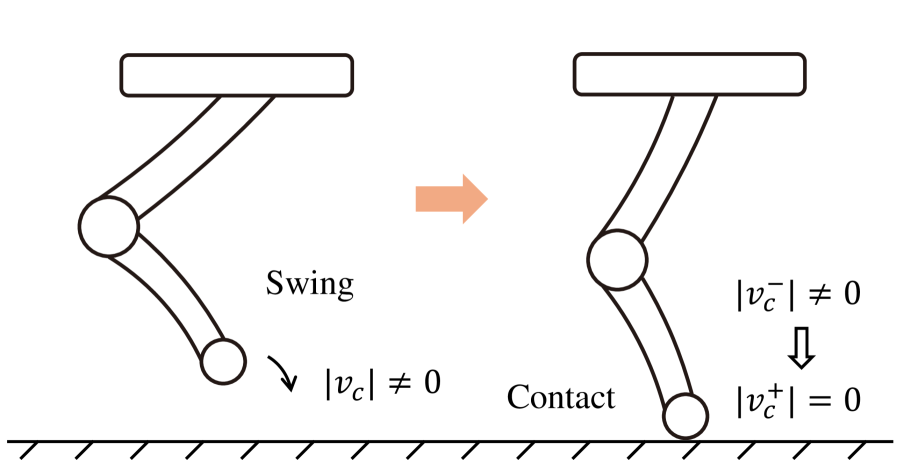
在基于模型的控制领域,混合自动机框架作为一种强大的工具,被广泛应用于建模具有离散与连续动态的系统,为腿式机器人行为规划和足式行走提供了有效解决方案。然而,由于混合动力系统的组合性质,通过基于模型的优化找到最优策略在计算上极具挑战性,特别是对于具有高维状态和动作空间的任务。
相比之下,无模型的强化学习(RL)在解决机器人最优控制问题方面展现出了巨大潜力。RL将过渡动态建模为马尔可夫决策过程(MDP),并通过最大化累积奖励来求解。然而,RL策略通常由深度神经网络表示,缺乏可解释性,且无法显式建模混合动力系统。此外,接触引导任务由于接触事件的稀疏性,对RL提出了额外的挑战。RL中的采样效率低下往往导致次优学习,而现有的连续映射策略难以处理混合动力系统特有的突变特性。
面对这些挑战,来自密歇根大学安娜堡分校和南方科技大学的研究人员携手合作进行了深入研究,并提出了一种解决接触引导任务创新策略——离散时间混合自动机学习(DHAL)框架,为四足机器人滑板等接触任务提供了全新解决方案。
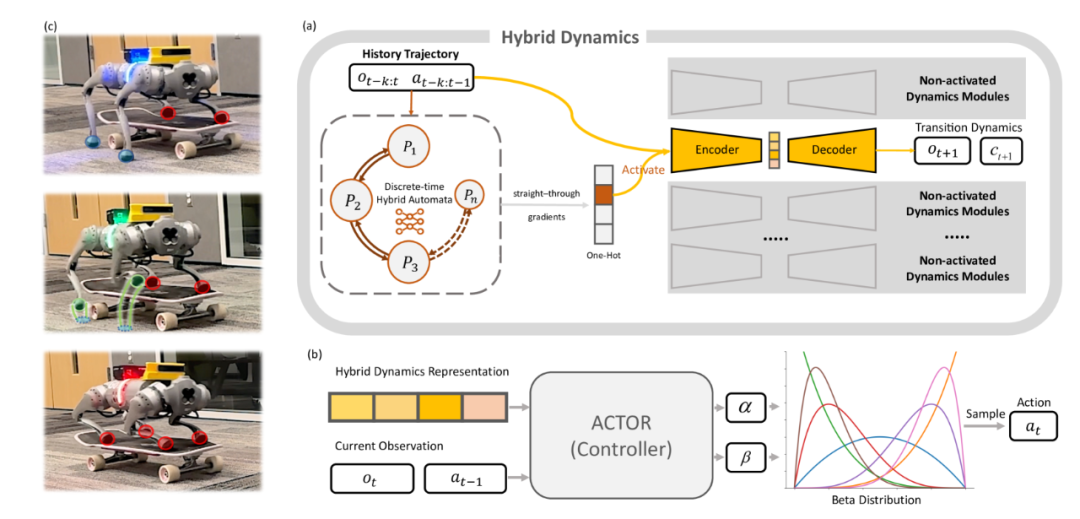
DHAL框架巧妙地结合了离散时间混合自动机和强化学习的优势,实现了对混合动力系统的显式建模和在线学习。无需显式的轨迹分割或事件标记,该框架就能够在线学习混合动力系统的模式切换。这不仅提高了算法的灵活性和适应性,还大大降低了对先验知识的依赖。此外,通过引入Beta策略分布和多评论家架构,DHAL框架进一步提升了策略的样本效率和稳定性,使其在面对稀疏奖励和复杂环境时仍能表现出色。
为了验证方法的有效性,研究团队进行了四足机器人滑板等具有挑战性实验。通过模拟和实际测试,研究团队验证了DHAL框架的有效性,并展示了其在混合动力系统中的稳健性能。
那么,该研究成果具体是如何实现的呢?接下来,和机器人大讲堂一起来深入了解!
▍三大核心部件,实现精确控制
DHAL框架主要由三个核心部分组成:离散时间混合自动机(DHA)、Beta分布策略以及控制器。这三个部分相互协作,共同实现了对混合动力系统的精确控制和模式识别。
-
离散时间混合自动机(DHA)
作为DHAL框架的核心组件之一,DHA负责在每一步确定系统的一个独热编码潜在模式。研究团队采用β-VAE(变分自编码器)来建模状态转移,以更好地与强化学习的随机性质对齐。DHA的设计旨在输出一个独热编码,从而将其视为分类问题。
状态转移建模:DHA使用β-VAE来学习状态转移的动态特性。β-VAE是一种生成模型,能够通过学习数据的潜在表示来捕捉数据的复杂分布。在这里,它被用来建模系统在不同模式之间的状态转移。
独热编码输出:DHA的输出是一个独热编码的潜在模式向量,这个向量指示了当前激活的动力学模块。独热编码的方式使得每个模式都对应一个唯一的编码,便于后续的处理和识别。
训练与优化:DHA通过最小化预测误差来训练,同时最小化模式概率的信息熵,以确保模式之间的区分度。这样,DHA就能更准确地识别系统的当前模式,并为后续的动态学编码和解码提供基础。
-
Beta分布策略
在足式行走任务中,主流框架通常假设策略分布为高斯分布。然而,当动作空间有严格界限时(如防止碰撞的关节位置限制),高斯分布可能产生超出界限的动作,导致策略优化中的偏差。为此,研究团队引入了Beta分布作为DHAL框架的策略分布。
Beta分布的优势:Beta分布是一种在有限区间上的连续概率分布,它能够有效地利用动作空间,特别是在稀疏奖励条件下。与高斯分布相比,Beta分布更能适应具有严格界限的动作空间,从而避免产生超出界限的动作。
策略优化:通过引入Beta分布,DHAL框架能够更准确地优化策略,提高样本效率和稳定性。Beta分布策略能够在面对稀疏奖励和复杂环境时仍能保持出色的性能。
-
控制器
控制器是 DHAL 框架的执行部分,它根据当前的观测和动力学模块的输出,计算并输出机器人的动作指令。控制器结合了强化学习的策略优化方法和动力学模型的预测能力,实现了对机器人动作的精确控制。
观测与输出:控制器接收来自环境的观测信息(如机器人的姿态、速度等)和动力学模块的输出(如当前模式、预测状态等),并根据这些信息计算出机器人的动作指令。
策略优化与动力学预测:控制器结合了强化学习的策略优化方法和动力学模型的预测能力。通过不断地试错和学习,控制器能够逐渐优化策略,提高机器人的运动性能。同时,动力学模型的预测能力也使得控制器能够更准确地预测机器人的未来状态,从而做出更合理的决策。
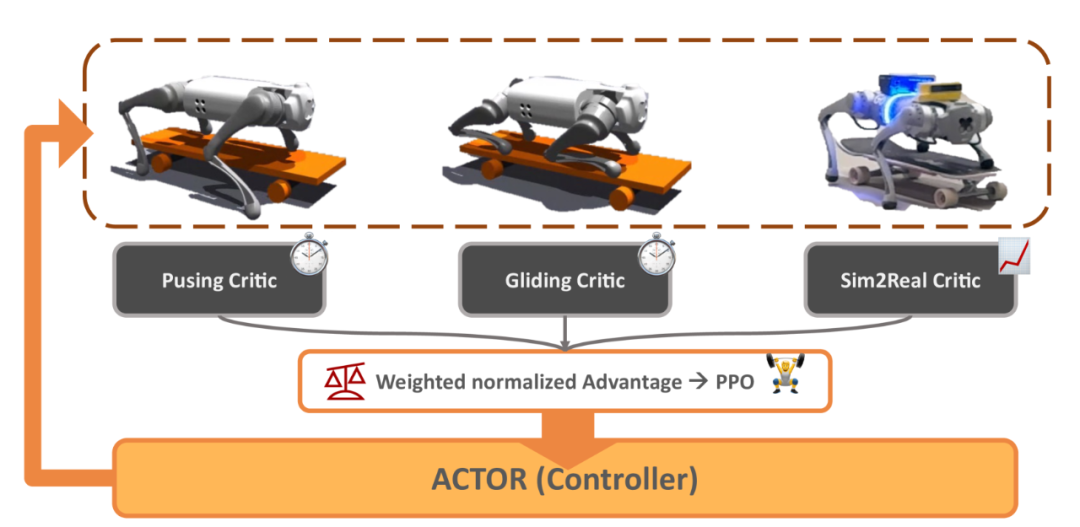
▍多重实验测试,验证框架有效
为了验证DHAL框架的有效性,研究团队进行了一系列精心设计的实验,包括混合动力学系统优势验证、滑板模式识别验证以及现实世界滑板运动验证。
-
混合动力学系统优势验证
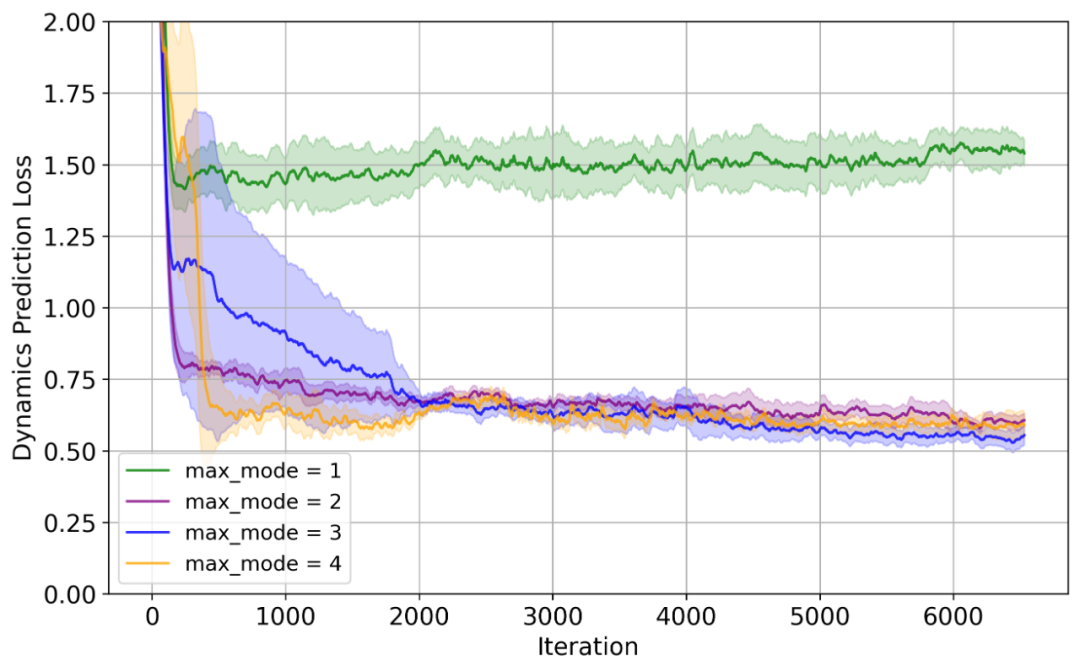
通过比较不同最大模式间的动态预测损失,研究团队发现当最大模式数为1(即用一个网络模拟整个动态)时损失最高;加入混合动力学思想后,通过切换模式引导流体动力学转换和突变,重建损失较小,且从最大模式数2开始,预测精度提升趋于平稳。这表明在具有突变等特性的系统中,构建混合动力学系统更合理。考虑到滑板两个主要状态,确定模式数为3是本系统合理值,对应三种运动模式。
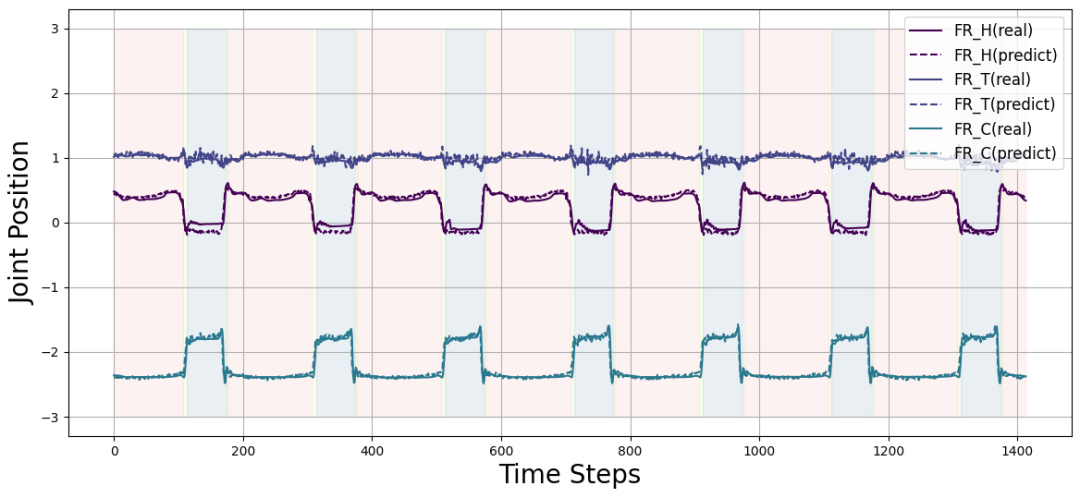
-
滑板模式识别验证
为验证方法能否识别滑板模式,研究团收集了机器人滑板真实轨迹及控制器选择模式进行可视化,用不同RGBLED颜色表示混合自动机选择的动态模块。结果显示,模式选择和转换顺序流畅,与滑板运动分解一致,且与物理直觉高度相符。此外,研究团队通过应用t-SNE降低控制器神经网络隐藏层输出维数,发现潜在空间在不同模式下分布清晰,这表明控制器能有效处理跨模式运动控制任务,DHAL模块能准确区分各种模式。

-
现实世界滑板运动验证
为评估DHAL框架在有干扰的现实世界中实现滑板运动的能力,研究团队在光滑陶瓷地板、柔软地毯地板、扰动、斜坡地形、单台阶地形、不平坦地形等多种真实场景中进行了实验测试,并就成功率进行了统计。

结果表明,DHAL框架在训练奖励、模式识别和抗干扰能力方面均表现出色,明显优于其他对比方法。尤为值得一提的是,在滑板公园的极端地形测试中,DHAL框架同样展现出了惊人的稳定性和适应性。尽管机器人偶尔会因为地形干扰而偏离滑板,但它总能迅速调整姿态并恢复稳定的滑行状态,这一结果有力证明了DHAL框架的鲁棒性。
参考文章:
https://arxiv.org/html/2503.01842v1#abstract
(文:机器人大讲堂)