

大家好!就在今天早上
我刚翻开社交媒体
就瞅见一条震撼科技圈的消息:
有开发者用区区8块GPU,就训练出
一个完全不用Transformer注意力的
72B大模型,性能竟超越GPT 3.5?!
往下瞅,发现这是PicoCreator团队
宣布发布的Qwerky-72B模型

他们不仅训练了72B版,还有32B版
这可不是小打小闹玩儿过家家
而是动了真格的
直接向「注意力是万能的」宗派宣战
还被开发者称为
「迄今为止最大的非Transformer注意力架构模型」
两个大模型在多项评测中不仅
完全不输同尺寸transformer
在某些测试中甚至胜出一筹!
先来看看他们的战绩到底咋样:
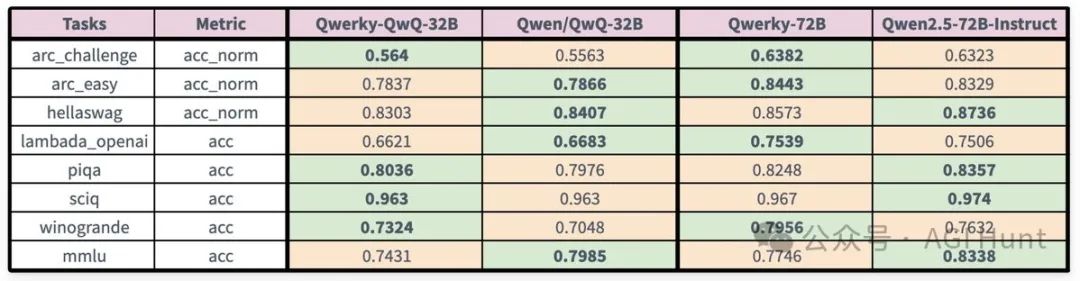
在ARC挑战赛上,Qwerky-72B达到63.82%
比Qwen2.5-72B-Instruct的63.23%还高
在Winogrande上,差距更明显:
Qwerky拿下79.56%,而Qwen只有76.32%
这分数可不是随便挑个软柿子来捏的
可都是AI理解力和推理能力的硬指标啊
这是怎么一回事呢?
他们到底用了什么黑科技?
原来,这个模型用了RWKV架构
不同于目前AI界的主流架构Transformer
它的计算复杂度不是平方级增长的
而是线性增长,也就是说
模型处理长文本时不像传统模型
又费算力又吃显存,效率高多了!
我寻思,这发现可不得了啊
来瞧瞧他们是咋做到的
(文:AGI Hunt)