跳至内容
就在刚刚,OpenAI 宣布在 GPT-4o 模型中集成了迄今为止最先进的图像生成器。
OpenAI CEO Sam Altman 在 X 平台继续夸夸群主上线,表示初次见到模型生成的图片时,难以相信是 AI 所为,并期待用户能发挥创意。
最新版本的系统卡写到,与作为扩散模型的 DALL·E 不同,4o 图像生成是一个自回归模型,原生嵌入在 ChatGPT 中。
具体来说,比起其他图像生成模型,GPT-4o 能处理多达 10-20 个不同物体的复杂指令,远超竞争对手 5-8 个的限制,差距不是一般大。
一句话 P 图也行,该模型同样支持多轮图像生成,聊着天就能优化图像,确保角色等元素在多次迭代中保持一致性。
比如设计个游戏角色,改来改去外观都能稳住,还能分析用户上传的图像、细节抓得准,并指导后续图像生成。
目前,新功能已向 Plus、Pro、Team 和免费用户开放,Enterprise 和 Edu 用户即将获得访问权限。别急,开发者们几周后也能通过 API 用上这功能。
附体验链接:https://chatgpt.com/
使用 GPT-4o 创建和自定义图像非常简单,只需描述需求,包括纵横比、精确颜色或透明背景等规格。不过要是细节多,渲染可能得等上一分钟,毕竟慢工出细活嘛。
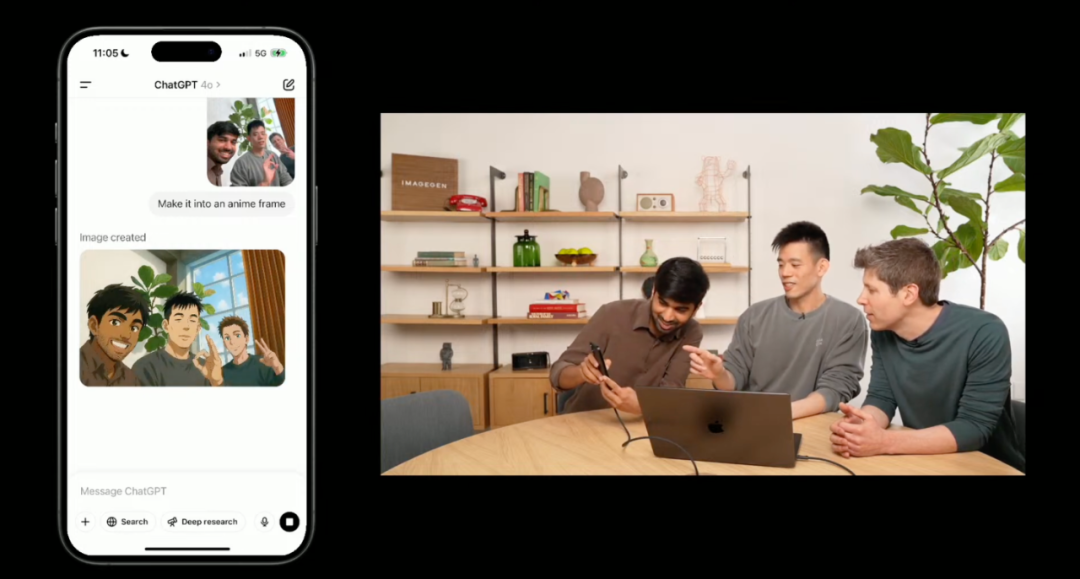
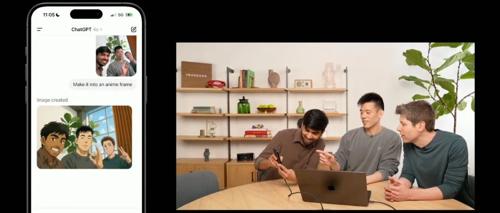
今天凌晨召开的发布会也向我们展示了几个具体的案例。比如说,演示者拍了张仨人的合影,让 ChatGPT 改成动漫风。
结果模型不仅保留了三人的特征(如胡须、表情等),还能理解并融合「动漫」这一视觉风格。
接着他又让它改成互联网梗图,加上了「I FEEL THE AGI」的文字,果然,OpenAI 的发布会少了 AGI 总感觉差点意思,属实是传统艺能了。
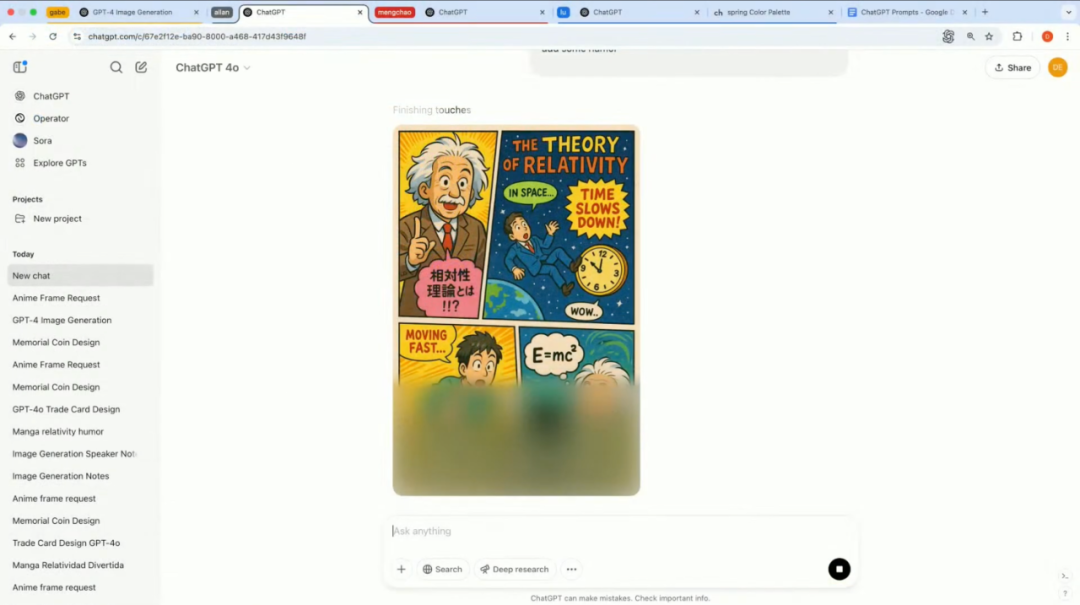
又或者,演示者要求模型创建一个「描述相对论的彩色漫画页面,并添加幽默元素」。
模型生成一个结构完整的漫画页面,包含了相对论相关概念的解释,融合了不同语言的文字,并通过视觉表现形式呈现出幽默效果。
换句话说,能够将抽象科学概念可视化,有望利好教育领域。
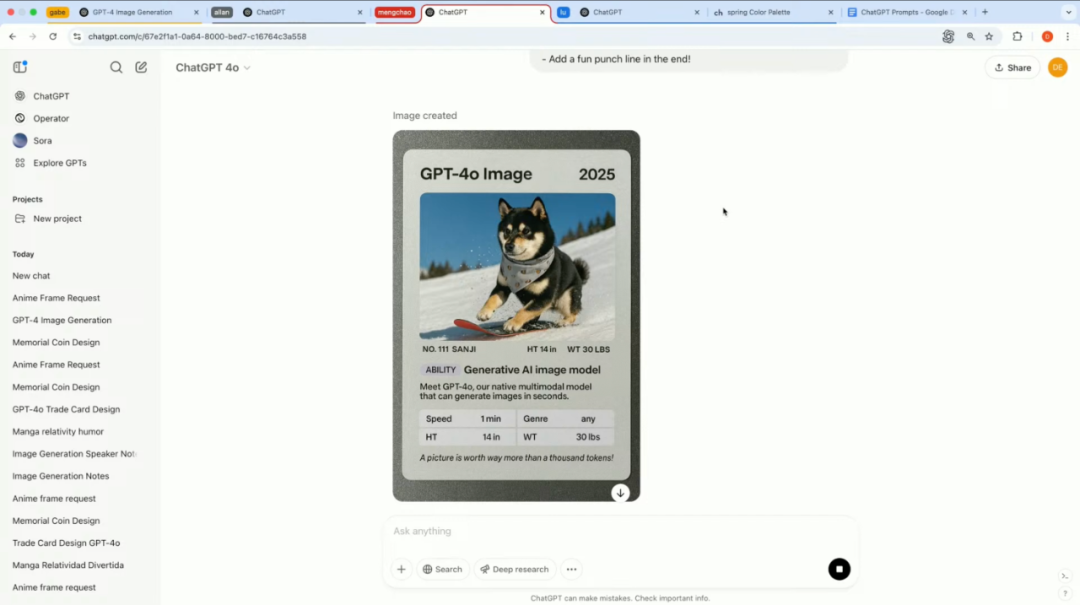
还有演示者先上传了一张 Sora 发布会的交易卡片照片作为参考,然后上传了自己宠物狗的照片,并提供了卡片上应包含的具体信息(名称、年份、能力、体重身高等)。
模型很快整出一张风格统一的卡片。卡片里,狗狗站在滑雪板上帅气出场,文字排版清晰准确。
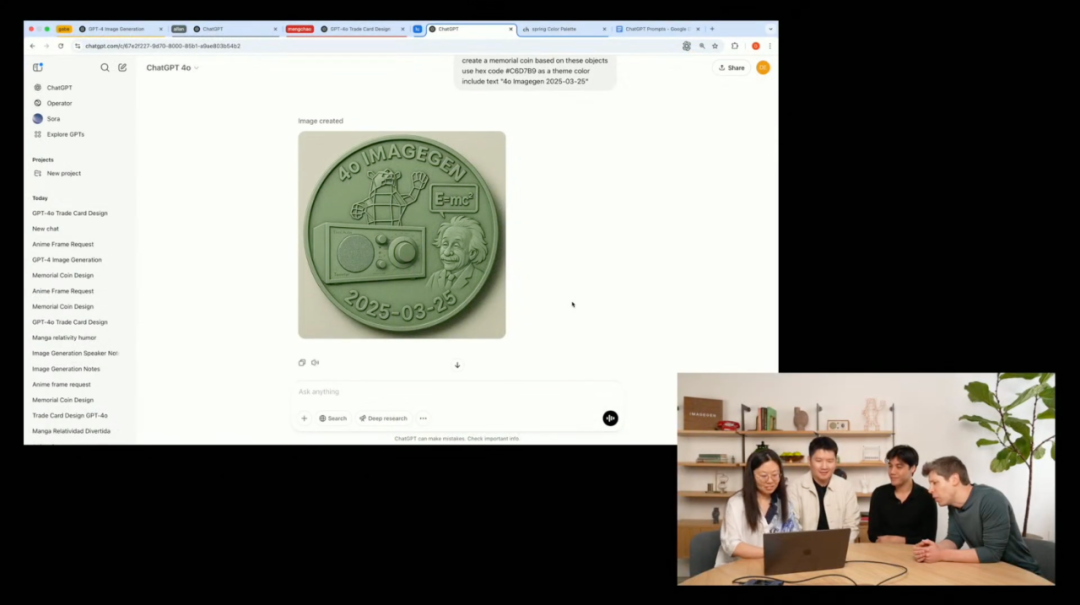
继续上强度,演示人员拿前两个演示的图加上背景两张图,让模型设计一枚纪念币,并指定了特定的颜色代码(春季色彩)和文字要求。
模型成功将四张不同图像以和谐方式融合到一个币面设计中。他随后还要求将背景改为透明,以便实际打印,模型稳稳改好,设计也没走样。
AI 生成图像造成的危害已经不是什么新鲜的话题了。为了安全,所有生成图像都带有 C2PA 元数据标识,OpenAI 还构建了内部搜索工具,验证内容来源,以及阻止违反内容政策的图像请求。
当要求生成真人图像时,OpenAI 则管得更严。包括 Altman 也表示,OpenAI 希望工具默认不生成冒犯性内容,除非用户明确要求,并在合理范围内实现。
那新功能也存在比较明显的短板。比如偶尔裁剪不恰当、低上下文提示下可能产生幻觉、渲染非拉丁语言文本困难、局部调整不够细等。OpenAI 说了,这些小问题会在发布后慢慢优化。
此外,Google 于今天凌晨也发布了旗下迄今为止最强大的 AI 模型。
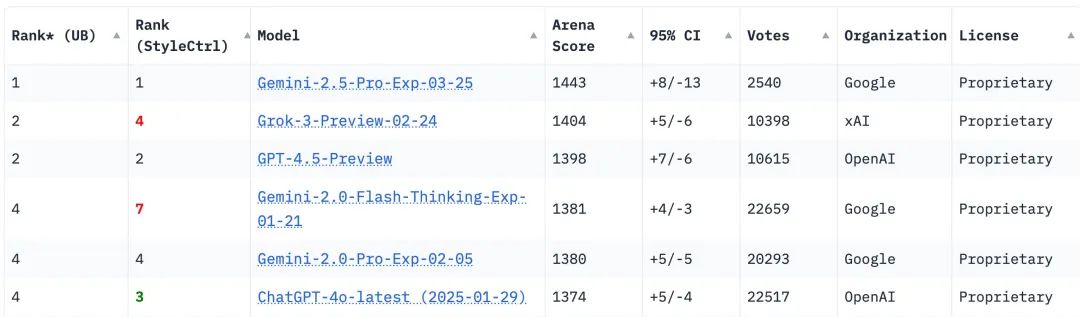
Google CEO Sundar Pichai 在线打 Call,称 Gemini 2.5 Pro Experimental 是一款最先进的「思维」模型,在多个基准测试中领先,特别是在推理和编程能力上有了显著的提升。
在大模型竞技场 Chatbot Arena 中,新模型力的排名压 Gork 3,再次遥遥领先。
按照 OpenAI 过往的「狙击」作风,新模型的发布一方面是对上周 Google 发布的图像模型进行回击,另一方面同样是狙击 Gemini 2.5 Pro Experimental。
你方唱罢我登场,AI 巨头们针锋相对的戏码只会越演越烈,消停?看来是想都别想了。

我们正在招募伙伴
✉️ 邮件标题
「姓名+岗位名称」(请随简历附上项目/作品或相关链接)
(文:APPSO)