

72B的VLM(视觉语言模型)太大?7B的又不够强?32B刚刚好!
-
模型输出更符合人类偏好:调整输出样式,提供更详细、格式更规范、更符合人类偏好的答案。
-
数学推理:解决复杂数学问题的准确率显著提升。
-
细粒度图像理解与推理:在图像解析、内容识别、视觉逻辑推理等任务中提升准确率和细化分析能力。
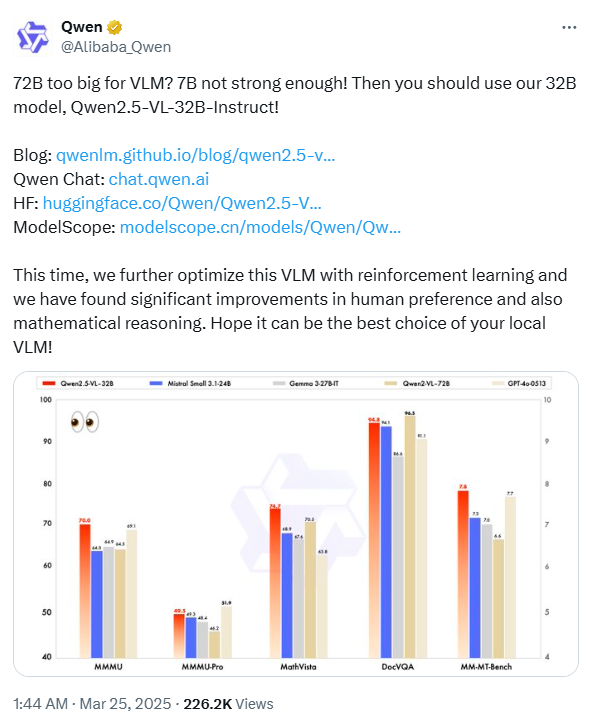
经过与规模相当的最先进的 (SoTA) 模型进行广泛的基准测试,Qwen2.5-VL-32B-Instruct 已证明优于 Mistral-Small-3.1-24B 和 Gemma-3-27B-IT 等基准模型,甚至超过了更大的 Qwen2-VL-72B-Instruct。值得注意的是,它在 MMMU、MMMU-Pro 和 MathVista 等多模态任务中取得了显著优势,这些任务侧重于复杂的多步骤推理。在 MM-MT-Bench(一种强调主观用户体验评估的基准)上,Qwen2.5-VL-32B-Instruct 的表现远胜于其前身 Qwen2-VL-72B-Instruct。
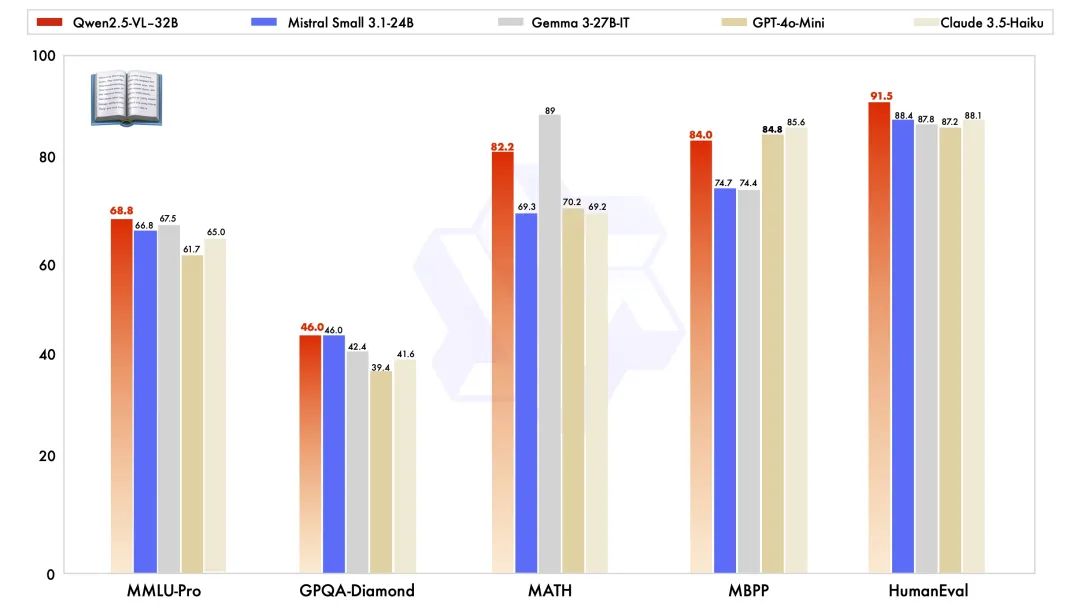
Qwen2.5-VL-32B-Instruct 除了在视觉能力上表现出色外,在同规模的纯文本能力上也取得了顶级表现。

DeepSeek-V3-0324 更新带来了:
-
推理性能大幅提升
-
更强大的前端开发技能
-
更智能的工具使用能力
-
对于非复杂推理任务,建议使用 V3(关闭“深度思考”)
-
API 使用保持不变
-
模型现在根据 MIT 许可证发布
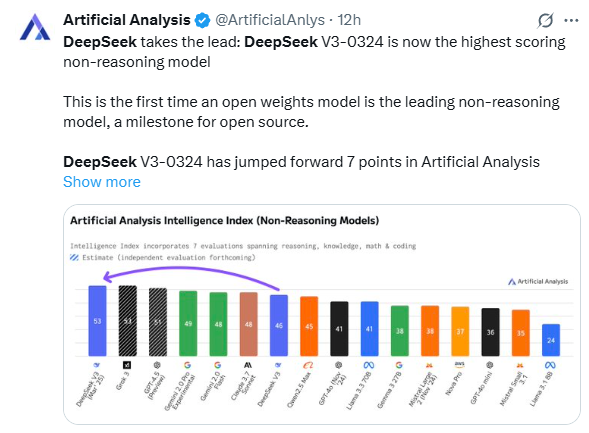
DeepSeek 再次说明了什么是“出道即巅峰”:DeepSeek V3-0324 在人工智能分析智能指数中跃升了 7 分,现在领先于所有其他非推理大模型。
编者注:
“视觉语言模型(VLM)是一种能够同时接受视觉(图像)和语言(文本)两种模态信息输入的大语言模型。 基于视觉语言模型,可以传入图像及文本信息,模型能够理解同时理解图像及上下文中的信息并跟随指令做出响应。”
Qwen2.5-VL-32B-Instruct下载地址:
https://huggingface.co/collections/Qwen/qwen25-vl-6795ffac22b334a837c0f9a5
https://modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
DeepSeek-V3-0324下载地址:
https://huggingface.co/deepseek-ai/DeepSeek-V3-0324
文章来源:PyTorch研习社
(文:PyTorch研习社)