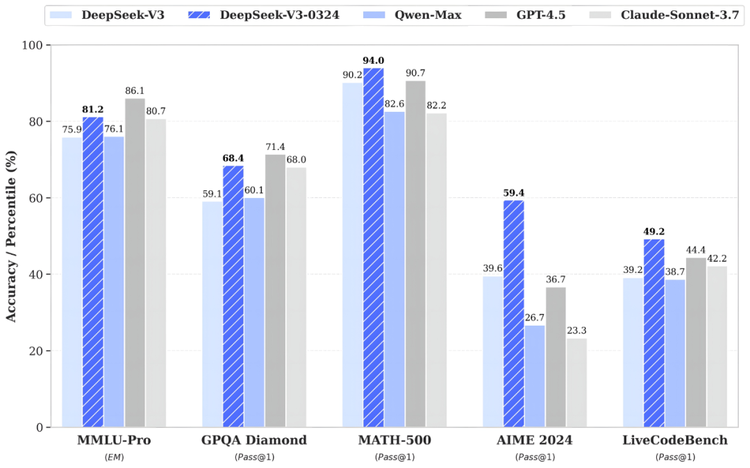
DeepSeek V3“小版本更新”背后,V3和R1正在融合成一个模型 上午11时 2025/03/26 作者 硅星人Pro 作者|summer邮箱|huangxiaoyi@pingwest.com 在R2和V4到来之前,DeepSeek先让我们看到了“V3 Plus”。 3月24日,DeepSeek一声不响的在Huggingface上发布了V3的“小版本”迭代“DeepSeek-V3-0324”。开发者社区再次一片尝鲜与夸赞。 之后3月25日晚,官方发布了该版本的官方报告。在DeepSeek的报告里,给出了四个官方亮点指引,分别是推理能力、前端开发能力、中文写作能力、中文搜索能力的强化。 乍看起来,这些能力提升都聚焦在用户常见任务场景之上。这也的确是一次非常注重实用性的升级,虽名为“小版本”,V3-0324却在多个关键能力上实现了显著突破,尤其是代码生成能力的提升令人印象深刻。用户只需关闭深度思考模式,就能体验这一新版本,而API接口和使用方式保持不变。 而仔细观察这几个提升的领域,会发现一个有意思的点:DeepSeek给V3做的提升,全都落在R1的优势能力范围内了啊。 据报告显示,推理能力的提升主要体现在新版 V3 模型的百科知识(MMLU-Pro, GPQA)、数学(MATH-500, AIME 2024)和代码任务(LiveCodeBench)表现均有提高,特别是在数学、代码类相关评测集上取得了超过 GPT-4.5、Claude-Sonnet-3.7的得分成绩。 过去,在DeepSeek的两个模型中,R1是推理模型,而V3则更适合日常对话。如今V3系列也有了推理能力的强力升级,用户可以更好地根据任务难度选择合适的模型:复杂问题用R1,日常对话用新版V3。这种差异化策略让算力资源与任务需求更匹配,避免了不必要的计算浪费。 在推理能力之上,几项任务场景中,最引人注目的是模型的代码稳定性和准确性。继Claude-Sonnet-3.7在前端开发能力上火爆出圈之后,大模型在这一场景的实用性被额外关注。在V3新版本技术报告出现之前,不少网友们就迫不及待地测出了V3-0324在前端开发场景下的能力飞跃。 有开发者报告生成800行代码,字符蹦到“冒火星”,竟然无一错误。对开发者而言,这种体验在遍地都是爱报错的AI编程工具之下,显得尤为突出。 还有用户进一步测试表明,尽管还有差距,但DeepSeek-V3-0324在前端视觉设计上已经接近了Claude这样的顶级模型。 用户只需提供简单提示,就能生成时尚的数字营销页面,布局合理,视觉效果精美。这种实用性的提升对网页设计师和前端开发者尤为重要,大大缩短了从创意到实现的时间。 与社区测试相呼应,DeepSeek官方在技术报告中也展示了模型的前端代码能力。报告中展示了一个p5.js小球物理运动程序,包含可调整的物理参数和赛博朋克风格界面,不仅功能完整,还具有高度的美观性和交互性。 更重要的是,这个不比Claude差的新版本,可以免费使用,据网友测算,付费API的价格更是便宜了15倍。 除了代码能力,DeepSeek R1的写作能力也一直被津津乐道。其细腻的文风虽然有时会陷入极繁主义的浮夸,但情节连贯性和特定风格下的表达能力很强,有短剧和小说从业者都曾对硅星人提到,已经开始应用DeepSeek创作。 此次,新版本V3在中文能力也有明显增强,特别是中长篇文本创作上质量更高,结构更完整,逻辑更严密,实用性也大大增强。 另外,在联网搜索场景下,报告生成能力也有显著提升。模型能够从网络信息中提取关键内容,生成详实准确的报告,并以清晰美观的排版呈现。 在开源方面,DeepSeek也继续保持了其一贯的透明度和友好性。作为小版本更新,私有化部署只需要更新checkpoint和tokenizer_config.json等少量文件。这意味着现有用户升级成本极低,几乎可以无缝迁移。据报告显示,该模型参数约660B,略低于原先V3的671B,开源版本上下文长度为128K(网页端、App和API提供64K上下文),依然采用MIT许可证,这使得开发者可以在各种场景下自由使用。 这些能力提升其实幅度不小,但DeepSeek没有把它称为V3.5、V3.7,而只是将它定义为一次V3小版本更新。 在行业版本迭代泛滥、概念炒作盛行的当下,通过低调务实的姿态赢得了更多开发者社区的尊重。虽然能力有显著提升,但由于没有大的技术路线突破,仍将其定位为小版本迭代,那么当DeepSeek真正发布R2时,那将是一次名副其实的重大升级,而非行业常见的“通货膨胀式”命名。 这种对技术命名的诚实态度,也是外界格外期待R2的重要理由。 而这次更新最重要的地方还在于,DeepSeek的V3和R1出现后,如Anthropic等对手在尝试用新方法超车,核心在于把推理模型和大语言模型融合,无论是产品上通过AI的自动调配来融合到一起,还是从模型层面就“合二为一”。 现在看来,DeepSeek此次更新也很直白的展示了自己接下来的路线,也是把V系列和R系列融合成一个新模型。 官方报告中明确指出,此次更新与之前的DeepSeek-V3使用同样的base模型,仅改进了后训练方法,并借鉴了DeepSeek-R1模型训练过程中的强化学习技术。 这是纯RL路线的再一次的验证和公示,在对手们继续闭源并使用“唯一混合模型”这样的概念来吸引人的时候,它继续通过开源为行业提供公开的高效迭代思路。DeepSeek这开源的仗还会继续打下去,好戏还在后面。 点个“爱心”,再走吧 (文:硅星人Pro)