

 关注我,记得标星⭐️不迷路哦~
关注我,记得标星⭐️不迷路哦~
✨ 1: Desktop Commander MCP
Desktop Commander MCP:通过Claude执行终端命令,管理进程,并提供文件读写、搜索、编辑等功能。
Desktop Commander MCP 是一个 Claude 桌面应用的扩展工具,它通过 Model Context Protocol (MCP) 协议,让 Claude 能够在你电脑上执行终端命令、管理进程,以及进行文件操作和代码编辑。
- 终端命令执行:
允许 Claude 运行终端命令,并实时获取输出,支持超时控制和后台运行。 - 进程管理:
可以列出和结束系统进程。 - 文件系统操作:
提供文件的读写、创建/列出目录、移动文件/目录、搜索文件、获取文件元数据等功能。 - 代码编辑:
支持对代码进行精确的文本替换(适合小修改),以及完整的重写文件(适合大修改)。编辑操作可以基于模式匹配,并支持多个文件。
Desktop Commander MCP 扩展了 Claude 桌面应用的能力,让它不仅仅是一个聊天机器人,更成为一个强大的自动化工具,可以协助你完成各种开发和运维任务。
地址:https://github.com/wonderwhy-er/ClaudeDesktopCommander
✨ 2: mcp-hfspace MCP Server
mcp-hfspace是连接Hugging Face Spaces的MCP服务器,简化配置,支持图像生成、语音转录等多种功能。
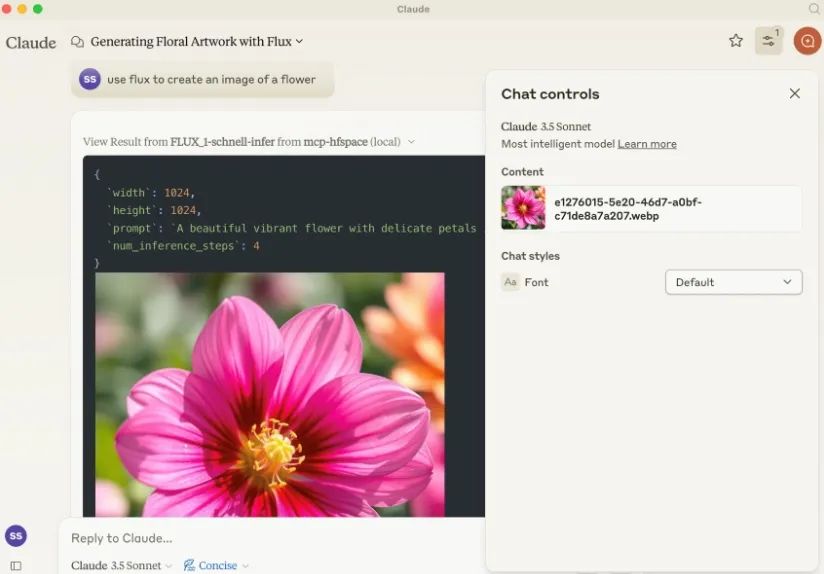
mcp-hfspace MCP Server 是一个连接 Claude Desktop 和 Hugging Face Spaces 的桥梁。它旨在简化与 Hugging Face Spaces 的集成过程,让用户能够在 Claude Desktop 中轻松使用各种 Hugging Face Spaces 提供的模型和服务,例如图像生成、文本转语音、语音转文本、视觉模型等。
- 连接 Hugging Face Spaces:
允许 Claude Desktop 通过简单的配置连接并使用 Hugging Face Spaces 中的模型和服务。 - 自动配置:
能够自动找到合适的 API 端点并进行配置。 - 文件处理:
支持文件上传和下载,可以处理图像、音频等文件。 - Claude Desktop 模式:
专门为 Claude Desktop 设计的模式,图像直接返回到 Claude 的上下文窗口,其他文件保存到工作目录并返回文件路径。 - 支持私有 Spaces:
可以使用 Hugging Face Token 访问和使用私有 Spaces。 - 灵活的配置:
允许用户自定义工作目录、API 端点等。
mcp-hfspace MCP Server 提供了一个便捷的方式,将 Claude Desktop 和 Hugging Face Spaces 的强大功能结合起来,扩展了 Claude Desktop 的能力,并让用户能够更轻松地使用各种 AI 模型和服务。
地址:https://github.com/evalstate/mcp-hfspace
✨ 3: Code Runner MCP Server
Code Runner MCP Server是一个用于运行代码片段并显示结果的MCP服务器,支持多种编程语言。
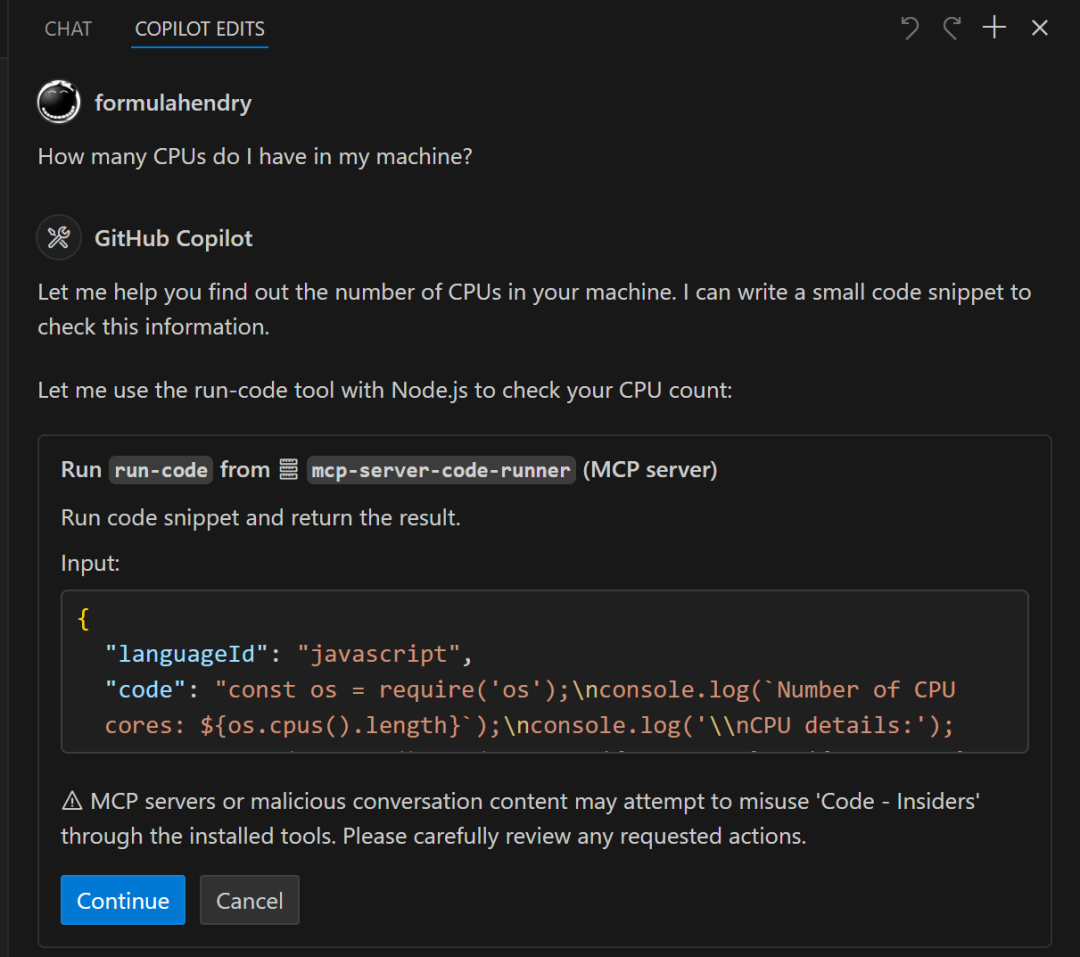
Code Runner MCP Server 是一个允许你运行代码片段并显示结果的微服务。 它支持多种编程语言,包括 JavaScript, PHP, Python 等等。
- 代码片段执行:
可以在支持 MCP 协议的应用程序(如 VS Code, Claude Desktop)中直接运行代码片段,例如简单的数学运算或输出系统信息。 - 调试和测试:
快速验证代码逻辑或测试某个功能,而无需搭建完整的开发环境。 - 系统信息获取:
通过运行代码获取操作系统相关信息,比如临时文件夹位置或 CPU 数量。 - 与 AI 助手结合:
使 AI 助手能够执行代码并提供更准确的答案,例如运行代码来解决数学问题或获取当前时间。
地址:https://github.com/formulahendry/mcp-server-code-runner
✨ 4: 4o-image-generation
OpenAI于2025年3月25日推出了其最新的图像生成能力,该功能集成于 GPT-4o 模型中。OpenAI长期以来认为图像生成应该是其语言模型的主要能力之一,而GPT-4o代表了他们迄今为止最先进的图像生成器,其目标是生成 不仅美观而且实用 的图像。
与以往侧重于超现实或令人惊叹的场景的生成模型不同,GPT-4o的图像生成更侧重于实用性,能够生成人们在分享和创建信息时使用的“主力”图像。这包括从徽标到图表的各种图像,这些图像在与共享语言和经验相关的符号结合时,可以传达精确的含义。
GPT-4o的图像生成在多个方面进行了改进,使其在实用性和功能性上都更上一层楼:
- 文本渲染
:GPT-4o能够准确地渲染文本,并能精确地遵循提示。它具备将精确的符号与图像融合的能力,将图像生成转变为视觉交流的工具。例如,它可以生成带有清晰可读文字的街道路牌、菜单和邀请函。 - 多轮生成
:由于图像生成现在是GPT-4o的原生能力,因此可以通过自然对话来改进图像。GPT-4o可以基于聊天上下文中的图像和文本进行迭代,确保整个过程的一致性。例如,在设计视频游戏角色时,即使经过多次修改和实验,角色的外观也能保持连贯. - 指令遵循
:GPT-4o的图像生成能够遵循详细的提示,并注重细节。与其他系统在处理5-8个对象时可能遇到困难不同,GPT-4o可以处理多达10-20个不同的对象。对象与其特征和关系之间更紧密的结合使得控制更加精细。 - 上下文学习
:GPT-4o可以分析和学习用户上传的图像,并将其细节无缝集成到上下文中,从而为图像生成提供信息。这意味着您可以上传一张图片作为参考,并要求GPT-4o生成具有相似风格或特征的新图像。 - 世界知识
:原生的图像生成能力使GPT-4o能够连接其文本和图像之间的知识,从而使其感觉更智能、更高效。这使得它可以根据代码生成图像,创建带有食谱标签的鸡尾酒专业照片级图表,生成旧金山雾天原因的可视化信息图,以及制作不同类型鲸鱼的教育海报等.
GPT-4o在大量不同图像风格的数据上进行了训练,使其能够令人信服地创建或转换图像。这包括生成各种风格的图像,例如模仿抓拍的狗仔队照片、宝丽来风格的照片、老式胶片照片,以及高度逼真的场景和物体。
OpenAI也承认其模型并非完美,目前存在一些局限性,他们将在发布后通过模型改进来解决这些问题:
- 裁剪
:GPT-4o有时可能会过度裁剪较长的图像,尤其是在底部附近。 - 幻觉
:与其他文本模型类似,图像生成也可能编造信息,尤其是在上下文信息较少的提示下。 - 高绑定问题
:在生成依赖其知识库的图像时,模型可能难以一次准确渲染超过10-20个不同的概念,例如完整的元素周期表。 - 精确绘图
:模型在生成精确的图表时可能存在困难。 - 多语种文本渲染
:模型有时难以渲染非拉丁语言,字符可能不准确或出现幻觉,尤其是在更复杂的情况下。 - 编辑精度
:对图像生成的特定部分(例如错别字)进行编辑的请求有时效果不佳,并且可能以非请求的方式更改图像的其他部分或引入更多错误。模型在保持用户上传面部编辑的一致性方面存在一个已知bug,但预计在一周内修复。 - 小文本中的密集信息
:当要求以非常小的尺寸渲染详细信息时,模型已知会遇到困难。
地址:https://openai.com/index/introducing-4o-image-generation/
✨ 5: Gemini 2.5
Gemini 2.5 是 Google 最新的智能 AI 模型,具有更强的推理和代码能力,可以解决复杂问题。
Gemini 2.5 是谷歌最新推出的,也是目前最智能的AI模型。它着重于“思考”能力,即在给出答案之前进行推理思考,从而提高性能和准确性。
- 思考模型 (Thinking Model):
强调了Gemini 2.5 在回答问题之前进行推理和分析的能力,而不仅仅是分类和预测。 - 2.5 Pro Experimental版本:
这是首个发布的版本,在多个基准测试中表现优异,在LMArena排行榜上名列前茅。 - 强大的推理和编码能力:
在数学、科学、编码等领域表现出色。 - 可用性:
已经在Google AI Studio和Gemini Advanced app中提供,并将很快登陆Vertex AI。 - 更大的上下文窗口:
拥有1百万个token的上下文窗口(即将增加到2百万),能处理更复杂的任务和更大的数据集。 - 多模态能力:
支持文本、音频、图像、视频等多种信息来源。
地址:https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025/
(文:每日AI新工具)