
连续体机器人在近几十年受到了越来越多的关注。它们的柔顺性和灵活性使其在医疗、工业、农业和航空航天等诸多领域具有重要应用价值。充分发挥其能力需要设计有效、高效且可靠的控制系统,而由于其结构复杂性,这一任务仍然具有很大的挑战。
传统的连续体机器人控制方法通常依赖于对机器人物理模型的精确建模。然而,由于其柔性结构和不规则形态,连续体机器人的建模极其困难,且容易受到环境影响,导致模型难以准确反映机器人的实际动态行为。因此,研究人员转向了数据驱动的控制方法,尤其是基于Koopman算子的控制方法,近几年引起广泛关注。
▍提出KILC控制框架:破局连续体机器人控制困境
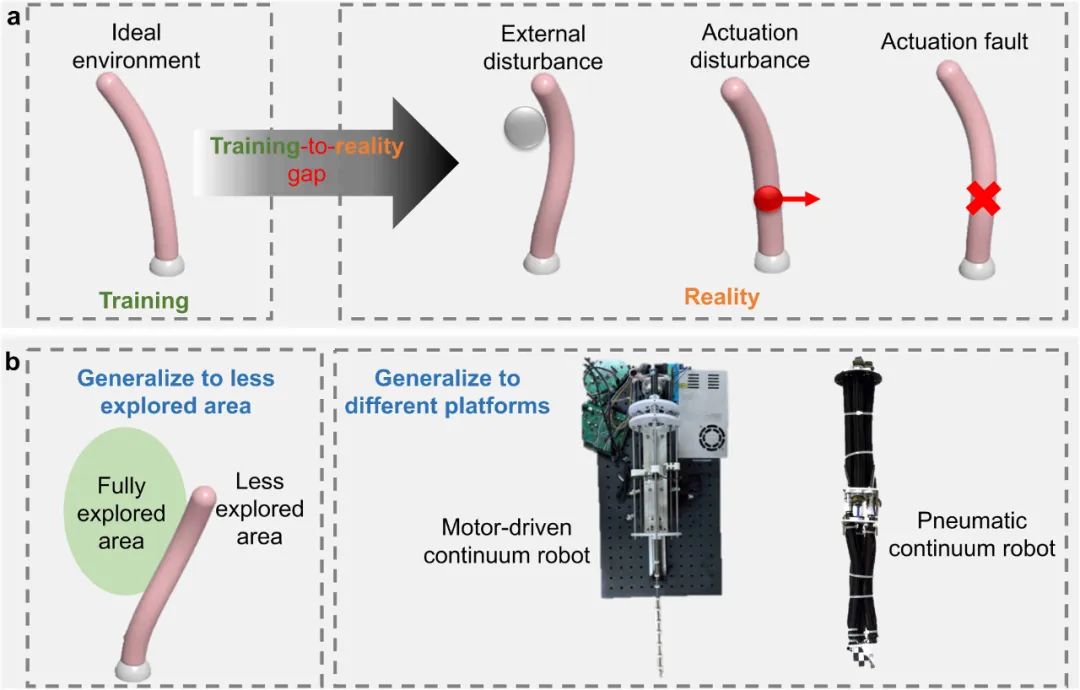
目前已有的基于Koopman算子的方法难以补偿不确定性和干扰,导致训练与现实之间的差距,从而造成性能不佳。由于连续机器人天生的易受干扰性,这一差距很容易在实际场景中削弱其任务空间性能。
连续机器人控制中的鲁棒性与泛化能力
同时,机器人可能需要在训练过程中未覆盖的区域进行操作,而且连续机器人的结构多样性进一步增加了控制的复杂性。此外,现有基于Koopman算子的控制方法的收敛性和鲁棒性尚未从理论或实验角度得到验证。因此,开发一种具有显著增强的鲁棒性、高计算效率、强泛化能力和严谨理论分析的数据驱动控制算法,对于连续机器人而言至关重要。
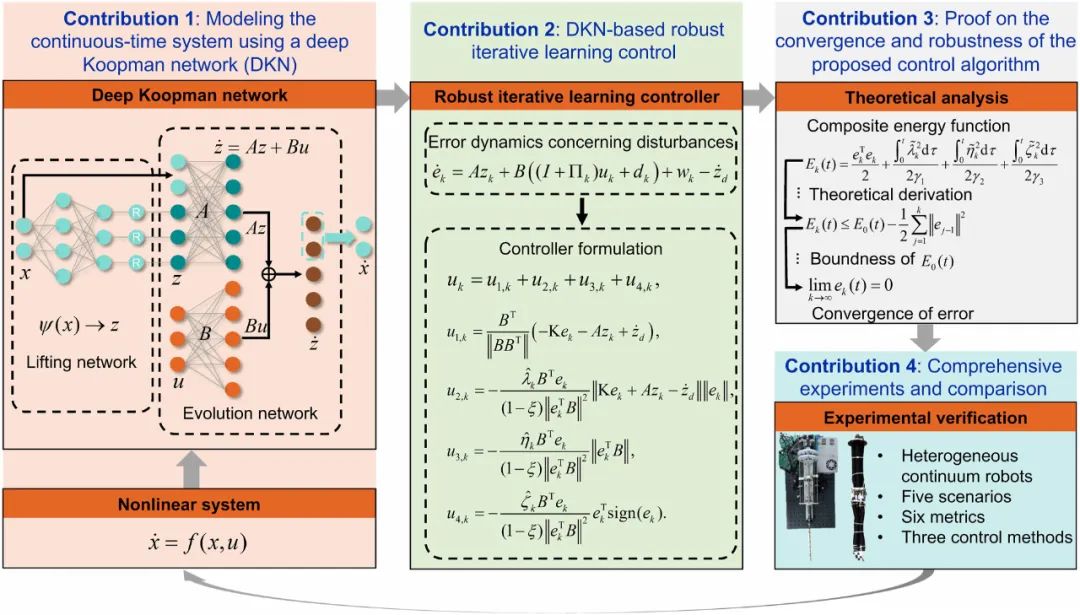
针对以上挑战,中山大学计算机学院谭宁团队进行了深入研究,通过深度Koopman网络学习连续体机器人的连续时间动态模型,并将其与迭代学习控制(ILC)方法结合,研究团队提出一种新的控制框架(KILC)。该方法能够在机器人模型未知的情况下,保证高效、鲁棒的控制性能。
总体思路与贡献示意图
该研究在理论方法与实践验证层面均取得了创新性突破,具体贡献如下:
1.连续时间机器人模型的学习:传统的Koopman算子方法主要依赖于离散时间模型,这在处理机器人系统时会带来许多限制,该工作提出了一种利用深度Koopman网络学习连续时间动态系统模型的方法。该方法通过原始非线性系统的输入-输出数据进行训练,使深度Koopman网络能够同时学习升维函数以及升维空间中的连续时间线性演化模型。
2.数据驱动的迭代学习控制(KILC)方法:通过结合深度Koopman网络学习到的连续时间模型,该工作设计了一种新的控制框架——基于Koopman算子的迭代学习控制(KILC)。该方法通过学习多次迭代的反馈,能够有效应对连续体机器人在任务过程中遇到的各种扰动和不确定性,确保机器人能够在不依赖精确物理模型的情况下,依然实现高精度的轨迹跟踪。
3.收敛性和鲁棒性理论分析:通过严格的理论分析,该工作证明了所提出的KILC方法在存在各种不确定性和干扰的情况下,依然能够在迭代次数增加时保证轨迹跟踪误差的收敛性。这一分析为控制方法的有效性和后续的实际应用提供了理论保障。
4.综合实验验证与多方法对比:为了验证所提出方法的有效性,该工作在两种异构连续体机器人(电机驱动和空气驱动)上进行了大量实验,并与现有的基于Koopman算子控制方法(KMPC和KLQR)进行了详细对比。实验结果表明,KILC方法在大多数指标上(如准确性、鲁棒性、泛化能力和计算效率)显著优于现有方法。

研究成果相关发表信息
近日,该研究成果的相关论文已以“On the learning-based control of continuum robots with provable robustness, efficiency, and generalizability”为题发表在《International Journal of Robotics Research》上。论文第一作者为中山大学计算机学院博士研究生余鹏,中山大学计算机学院谭宁副教授为论文的共同第一作者和通讯作者。该项研究成果获得了国家自然科学基金的资助。
▍多维协同创新:实现连续体机器人控制协同创新
为优化连续体机器人的控制与性能,本研究从模型学习、控制方法融合及理论验证多维度展开探索。通过创新技术路线突破传统局限,并以实验验证其有效性,具体如下:
1. 连续时间Koopman算子模型的学习
连续体机器人通常可以用一个非线性动态系统模型表示,利用Koopman算子和输入输出数据,可以在高维空间中学习到与该非线性模型近似等价的线性模型,从而便于控制。传统的基于Koopman算子的控制方法通常依赖于离散时间模型,这些离散时间模型采用固定的时间步长构建,在需要变化或不同时间步长的场景中会导致预测性能下降。为了解决这一问题,往往需要重新采集数据并重新训练模型。此外,固定时间步长的离散模型还会限制控制器的运行频率。因此,能够学习连续时间模型的方法是不可或缺的。
研究团队提出利用深度Koopman网络学习连续体机器人系统的连续时间动态系统模型,使得系统能够适应变化的时间步长,避免了传统方法中固定时间步长带来的局限性。
在该网络中,使用了“提升网络”和“演化网络”两个核心模块。提升网络负责将原始机器人状态映射到高维空间,而演化网络则学习该高维空间中动态系统的线性演化规律。通过这种方式,同时解决了Koopman算子中的维度提升问题和状态预测问题。
2.迭代学习控制(ILC)方法与深度Koopman网络结合
传统的迭代学习控制方法通常需要部分已知的系统模型,而在连续体机器人中,系统模型往往是未知的,因此,在连续机器人的原始任务空间中直接应用ILC方法具有一定挑战性。
该研究结合深度Koopman网络和ILC方法,基于所学习的连续时间模型改进ILC控制器,提出在升维空间中执行迭代学习控制,设计了一种新的数据驱动的控制框架。
在每一轮控制迭代中,通过计算当前误差来调整控制输入,并不断更新控制器中的参数,以实现更精确的轨迹跟踪。通过这种方法,KILC能够有效地应对不确定性、外部扰动以及系统故障等复杂情况。
3.收敛性和鲁棒性的理论分析
为了确保所提出的KILC方法能够在面对不确定性和扰动时依然表现出优异的性能,研究团队进行了严谨的理论分析。通过构造复合能量函数,分析了KILC方法的误差动态,证明了在不确定扰动的情况下,跟踪误差会随着迭代次数的增加而收敛至零。即使在存在外部扰动和不确定性的条件下,该方法也能保持良好的收敛性。
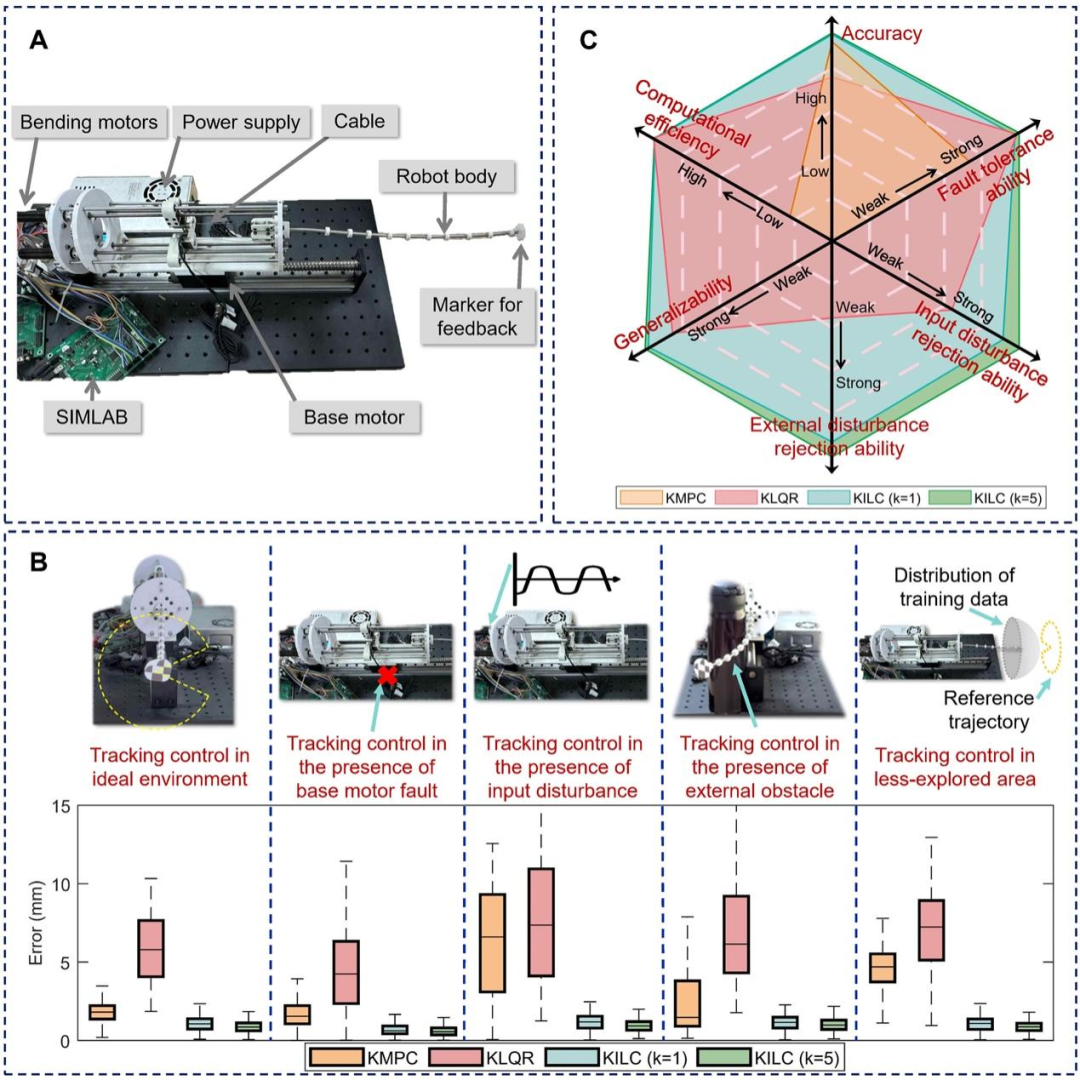
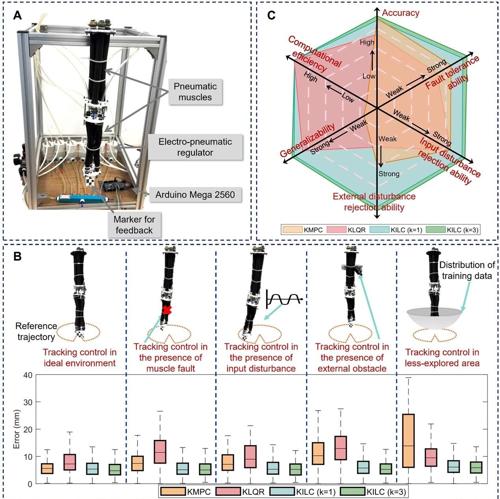
电机驱动连续体机器人实验结果总览及对比
▍两大实验平台:全面验证评估KILC框架有效性
为了全面评估各种控制方法的性能,验证KILC方法的有效性,研究团队在两种异构连续体机器人(电机驱动和气压驱动)平台进行了实验,实验涵盖理想环境、驱动故障、输入扰动、外部扰动以及未探索区域等多种场景。研究团队在每种场景下都比较了KILC方法与已有基于Koopman算子控制方法的跟踪精度、计算效率和鲁棒性。
控制精度方面,在电机驱动连续机器人的理想环境下,经过5次迭代学习后,轨迹跟踪误差降低至0.77mm,较KMPC方法提升了62%的精度。更值得注意的是,在更具挑战性的气动连续机器人平台上,KILC仍能保持6.11mm的跟踪精度,且通过迭代学习实现了9.6%的误差改善。
抗干扰能力方面,实验特别设置了多种干扰场景进行测试:在电机故障情况下,KILC的跟踪误差仅增加2.2%,而KMPC和KLQR分别增加了26.5%和1.2%;面对输入干扰时,KILC误差增幅控制在8%以内,远低于KMPC的257%和KLQR的36%。这些数据充分证明了KILC卓越的扰动抑制能力。
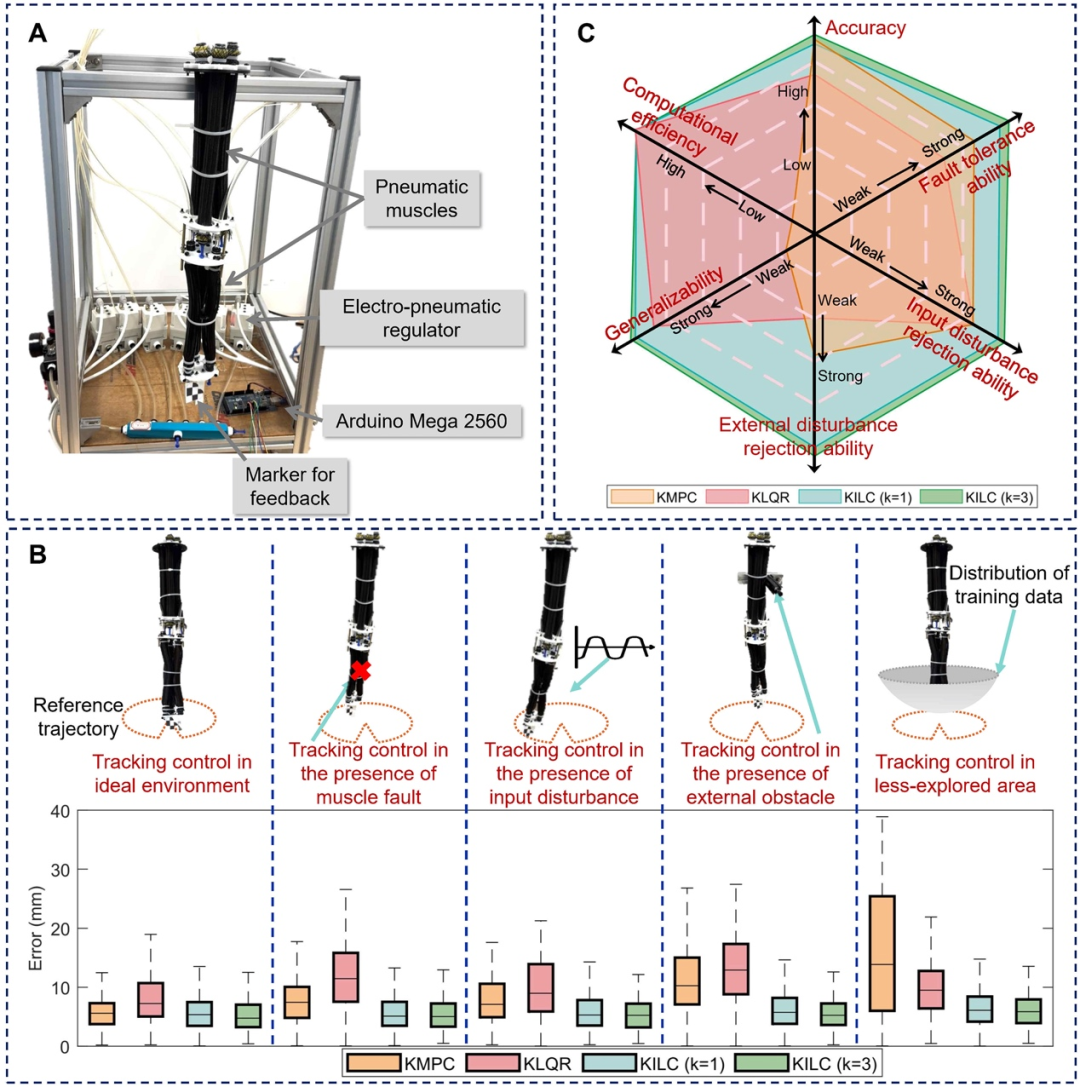
计算效率方面,KILC单步计算时间仅需0.32-0.36ms,与KLQR相当,但比KMPC快约93%。这种高效性使其非常适合实时控制应用。特别值得关注的是,KILC在保持计算效率的同时,通过迭代学习机制实现了控制性能的持续提升,5次迭代后平均改善率达17%。
泛化性能测试中,KILC在机器人未探索区域的任务表现尤为亮眼,误差增幅仅为1.7%,而KMPC和KLQR分别达到136%和14.6%。这得益于KILC独特的数据驱动特性和自适应能力,使其能够有效应对模型不确定性和环境变化。
两种机器人实验结果均表明,KILC在准确性、效率、鲁棒性和泛化能力上综合性能最优,尤其在非理想场景中优势显著,而随着迭代次数的增加,KILC方法的表现还可进一步得到改善。
参考文章:
https://doi.org/10.1177/02783649251351046
(文:机器人大讲堂)