

MagicMotion团队 投稿
量子位 | 公众号 QbitAI
轨迹可控的视频生成来了,支持三种不同级别的轨迹控制条件——分别为掩码、边界框和稀疏框。
近年来,视频生成技术快速发展,显著提升了视频的视觉质量与时间连贯性。在此基础上,(trajectory-controllable video generation)涌现了许多工作,使得通过明确定义的路径精确控制生成视频中的物体运动轨迹成为可能。
然而,现有方法在处理复杂的物体运动轨迹和多物体轨迹控制方面仍面临挑战,导致生成的视频物体移动轨迹不够精确,或者整体视觉质量较低。此外,这些方法通常仅支持单一格式的轨迹控制,限制了其在不同应用场景中的灵活性。不仅如此,目前尚无专门针对轨迹可控视频生成的公开数据集或评价基准,阻碍了该领域的更进一步的深入研究与系统性评估。
为了解决这些挑战,研究人员提出了MagicMotion,一种创新的图像到视频生成框架,共同第一作者为复旦大学研究生李全昊、邢桢,通讯作者为复旦大学吴祖煊副教授。

在给定一张输入图像和对应物体轨迹的情况下,MagicMotion能够精准地控制物体沿着指定轨迹运动,同时保持视频的视觉质量。
此外,本文构建了MagicData,一个大规模的轨迹控制视频数据集,并配备了一套自动化的标注与筛选流程,以提升数据质量和处理效率。
本文还引入了MagicBench,一个专为轨迹控制视频生成设计的综合评测基准,旨在评估在控制不同数量物体运动情况下的视频质量及轨迹控制精度。
大量实验表明,MagicMotion在多个关键指标上均超越现有方法,展现出卓越的性能。

方法介绍
MagicMotion基于 CogVideoX5B-I2V 这一图像到视频生成模型,并引入了额外的轨迹控制网络(Trajectory ControlNet)。该设计能够高效地将不同类型的轨迹信息编码到视频生成模型中,实现轨迹可控的视频生成。如图所示,本文使用 3D VAE 编码器将轨迹图编码到隐空间,然后将其与编码后的视频拼接,作为轨迹控制网络的输入。轨迹控制网络由所有预训练的 DiT 模块的可训练副本构建而成,用于编码用户提供的轨迹信息。每个轨迹控制网络模块的输出随后会通过一个零初始化的卷积层进行处理,并添加到基础模型中对应的 DiT 模块,以提供轨迹引导。
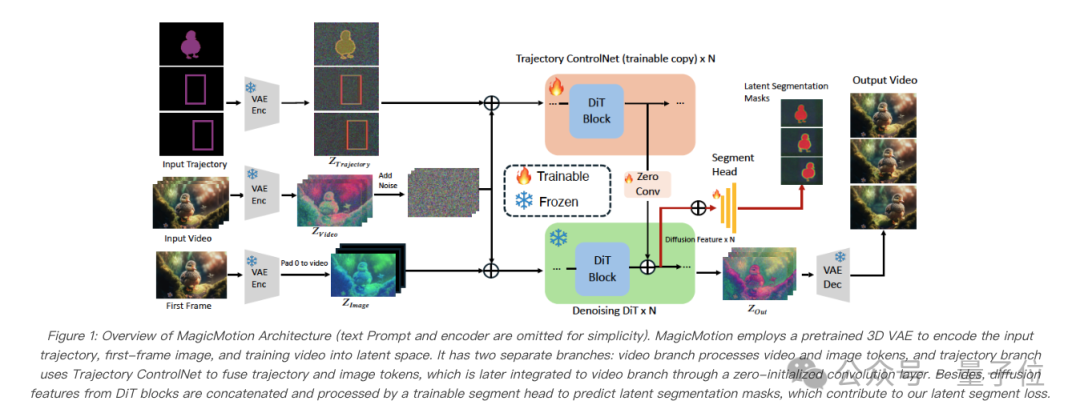
MagicMotion采用了从密集轨迹控制到稀疏轨迹控制的渐进式训练过程,其中每个阶段都用前一阶段的权重来初始化其模型。这使得能够实现从密集到稀疏的三种类型的轨迹控制。本文发现,与使用稀疏条件从头开始训练相比,这种渐进式训练策略有助于模型取得更好的性能。具体来说,本文在各个阶段采用以下轨迹条件:阶段 1 使用分割掩码,阶段 2 使用边界框,阶段 3 使用稀疏边界框,其中少于 10 帧有边界框标注。此外,本文总是将轨迹条件的第一帧设置为分割掩码,以指定应该移动的前景对象。
此外,MagicMotion还提出了隐分割损失(latent segment loss),它在模型训练过程中引入分割掩码信息,增强了模型对物体细粒度形状的感知能力。研究者使用轻量级分割头直接在隐空间中预测出分割掩码,从而在引入极小计算开销的情况下,无需进行解码操作,帮助模型在生成视频的同时在潜在空间中执行物体分割任务,从而更好地理解物体的细粒度形状。
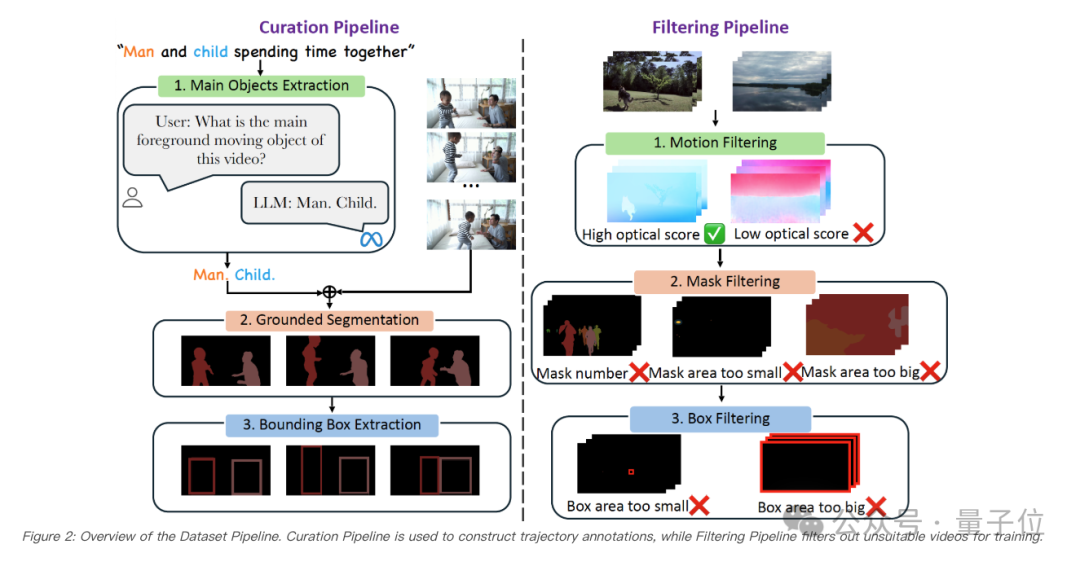
研究者还提出了一个全新的自动数据处理流程,包括两个主要阶段:数据整理流程(Curation Pipeline)和数据筛选流程(Filtering Pipeline)。数据整理流程负责从大规模的视频-文本数据集中构造轨迹信息,而数据筛选流程则确保在训练前移除不适合的视频。
实验与结果
MagicMotion的每个阶段都在MagicData上训练一个轮次。训练过程包括三个阶段。阶段1从零开始训练轨迹控制网络(Trajectory ControlNet)。在阶段2中,使用阶段1的权重进一步优化轨迹控制网络(Trajectory ControlNet),同时从零开始训练分割头(Segment Head)。最后,在阶段3中,轨迹控制网络(Trajectory ControlNet)和分割头(Segment Head)都使用阶段2的权重继续训练。研究者采用AdamW作为优化器,所有训练实验均在 4 张 NVIDIA A100-80G GPU 上进行,学习率设为 1e-5。
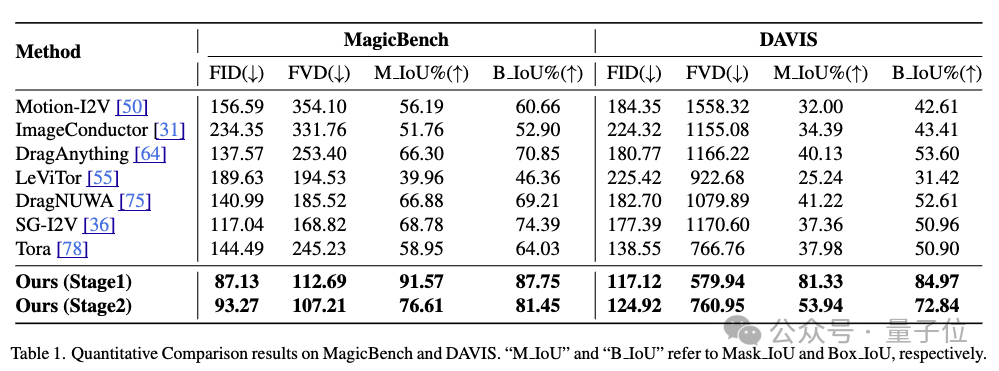
研究者将MagicMotion与7种流行的轨迹可控图像到视频(I2V)方法进行了对比,在MagicBench和DAVIS上对所有方法进行评估。
结果如下表所示,MagicMotion在MagicBench和DAVIS上的所有指标上都优于以往的所有方法,这表明它能够生成更高质量的视频并实现更精确的轨迹控制。
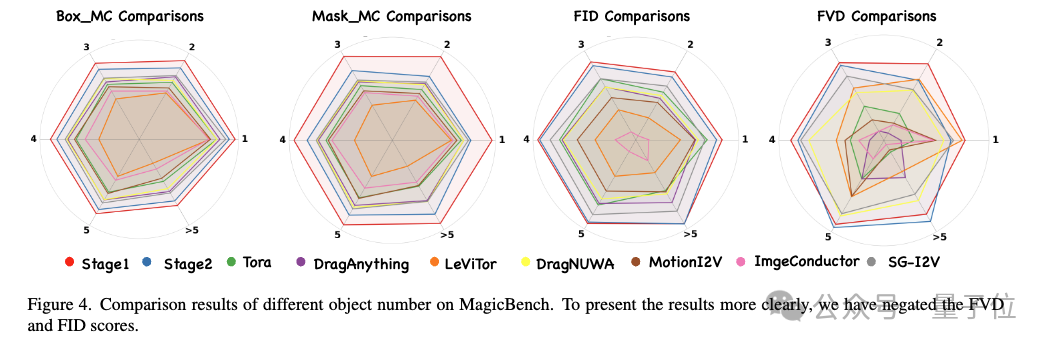
此外,本文根据受控对象的数量评估了每种方法在MagicBench上的性能。如下图所示,MagicMotion方法在所有受控物体数量的类别中都取得了最佳结果,进一步证明了该方法的优越性。
定性对比结果
如下图所示,Tora能够精准控制运动轨迹,但难以精确保持物体的形状。DragAnything 、ImageConductor 和 MotionI2V 在 保持主体一致性方面存在困难,导致后续帧中出现明显的形变。同时,DragNUWA、LeviTor 和 SG-I2V生成的结果经常出现视频质量底下和细节不一致的问题。相比之下,MagicMotion能够使移动的物体平滑地沿指定轨迹运动,同时保持高质量的视频生成效果。

论文地址:https://arxiv.org/abs/2503.16421
论文主页:https://quanhaol.github.io/magicmotion-site/
代码链接:https://github.com/quanhaol/MagicMotion
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
—
(文:量子位)