

极市导读
提出了一个全面的评测基准OVBench,并基于记忆增强机制构建了多模态大模型VideoChat-Online。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文介绍在在线视频理解领域上的新工作:Online Video Understanding: OVBench and VideoChat-Online,提出了一个全面的评测基准OVBench,并基于记忆增强机制构建了多模态大模型VideoChat-Online。随着多模态大模型(MLLMs)在离线视频理解任务上的突破,如何让这些模型适应实时视频流的处理需求成为新的挑战。本研究从评测基准、模型架构和训练策略三个方面展开探索,力求提升模型对流式视频的感知、推理和预测能力。目前我们的工作已被 CVPR 2025接收。
项目主页:https://videochat-online.github.io/
论文链接:https://arxiv.org/pdf/2501.00584v1
一、背景
在线视频理解与离线场景存在本质性系统差异,主要体现在三个核心维度:
-
时间维度的动态性——在线场景中用户提问时刻天然划分出过去(历史视觉信息)、现在(实时感知)与未来(预测可能性)三个动态时间域,要求模型具备时间锚点意识(如“3秒前发生了什么”)。 -
答案的时空敏感性——离线模型的答案基于完整视频的全局信息,而在线场景的答案会随视觉上下文的动态演变而改变(例如“他现在在做什么”在不同时刻具有不同答案)。 -
视觉信息的持续性——持续数小时甚至无限制的视频流输入,迫使模型突破传统固定长度视频处理的限制,需建立记忆筛选机制,在有限计算资源下保留关键时空线索。
为了更好地评测模型的在线理解能力,需要在评测基准中着重强调在视频流上下文中对实时时空细节的理解,根据视频流的特点定制评测任务,并进行有针对性的优化,从而确保评测基准的完整性和可靠性。同时还需要优化模型架构设计和训练策略,实现效率和性能之间的平衡。
二、OVBench评测基准
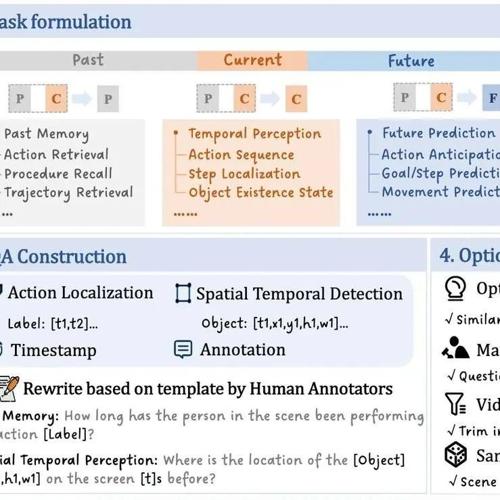
任务定义:为了系统地评估在线视频理解能力,这里定义了三个基本时间上下文,用于描述问题时间戳与视频时间线之间的关系:
-
当前(Current): 问题针对当前视频帧,可能需要少量前序帧作为辅助理解。 -
过去(Past): 位于问题时间戳之前的一系列视频帧,包含了有关动作、事件和物体轨迹等历史信息。 -
未来(Future): 位于问题时间戳之后的一系列帧,通常是根据当前动作和物体轨迹预测后续发生的事件。
基于过去(P)、当前(C)和未来(F)这三个基本时间上下文,我们确定了在线模型在视频流场景中需具备的6项关键能力,其中“→”表示从一个时间段到另一个时间段的推理或验证过程,“∪”表示对多个时间段的联合理解:
下图给出了OVBench时间上下文定义的示意图和上述六大类任务的例子。

-
空间感知。(Spatial Perception,C): 识别当前帧中的动作,准确描述物体的位置、数量和空间关系。 -
时间感知(Temporal Perception,C→P∪C): 追踪延伸到当前时刻的动作序列,评估正在进行的事件的持续时间,确定物体在前序帧中的存在状态。 -
时空感知(Spatio-temporal Perception,C→P∪C): 提供单个或多个物体运动轨迹、位移和相对位置的详细描述。 -
过往记忆(Past Memory,C→P或 P): 回忆与给定动作相关的过去事件,检索其持续时间和是否已达成目标,或者在被查询时定位物体过去所在的位置和状态。 -
时间幻觉验证(Temporal Hallucination Verification,P↔C): 判断过去观察到的动作在当前帧中是否仍在进行,验证已发生事件的状态,并分析过去和当前时刻之间物体位置变化。 -
未来预测(Future Prediction,P∪C→F): 根据观察到的运动模式和当前时空状态,预测可能即将发生的动作。
总共涵盖6大类任务、16小类任务。以全面评估模型在在线场景的性能。
QA对生成: OVBench中的问答对以选择题的形式呈现。为确保答案选项能够反映视频流中动态变化的视觉信息,我们在生成干扰项生成时,会尽可能地从同一视频内的不同时间戳、相似问题、同类物体对应的选项中进行选择,已确保问题的难度。
下图给出了OVBench评测基准的构建过程。

三、记忆增强机制的VideoChat-Online
在在线视频理解场景中,由于输入帧数随时间增加而计算资源有限,需要对视觉token进行有效压缩,以在接收视频流的同时保留关键信息。现有方法存在两个问题:固定窗口存储无法记住较早信息,而动态记忆机制采用单一分辨率建模,导致空间细节丢失和时间信息冗余。为此,我们提出了一种金字塔型记忆库(PMB)结构,通过多层、渐进式token处理平衡时空信息。其核心设计思想如下:
-
空间-时间解耦建模:低层级存储高分辨率细节,高层级存储长时间序列抽象信息,既捕捉短时精细信息,又保留长时时序信息。底层高分辨率特征通过低采样率捕获关键帧作为“空间锚点”。 -
层级递进存储策略:自下而上逐步降低空间分辨率,提高时间采样率,优化存储效率。空间分辨率按 β 因子指数衰减,时间采样率线性递增,形成对长时程运动模式的抽象表征。 -
动态信息淘汰机制:通过余弦相似度筛选冗余帧,结合平均池化的空间压缩,在信息损失可控的前提下减少存储占用,提升存储效率。
具体来说,金字塔记忆库分为 层,每层的记忆模块记作 ,自下而上从更加关注空间信息到更加关注时间信息,每层有两个关键参数:
1.采样率 :对于每一层 ,以采样率 输入流中采集视频帧,自下而上各层采样率逐渐增加,提升对时间信息的关注度。
2.分辨率 :自下而上以逐渐降低的分辨率 存储视频帧,每层的分辨率按如下方式进行缩放:
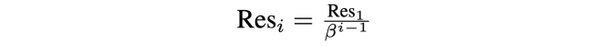
其中 是金字塔第一层的帧分辨率, 是下采样因子,设置为 2 。
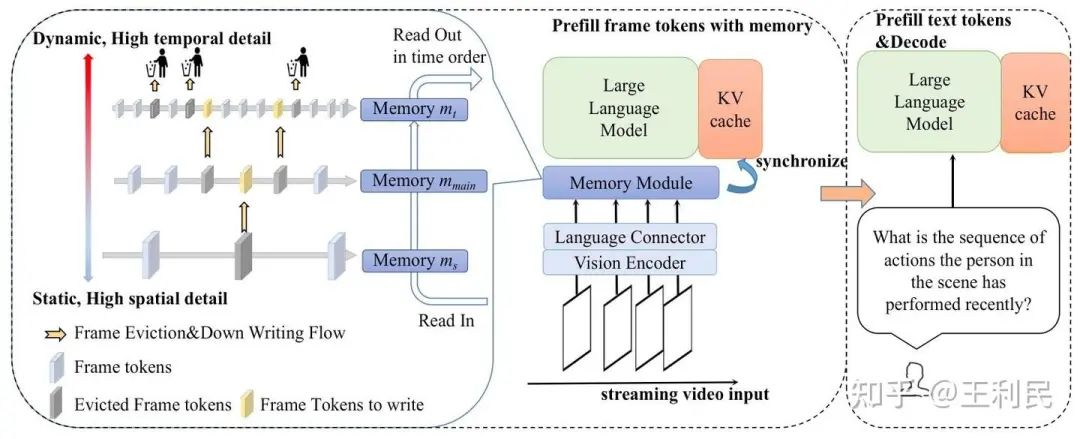
模型的整体框架如上图所示。每个记忆模块 执行三个主要操作:
1.流式视频帧写入: 记忆模块 直接从视频流中接收根据 采样的帧。这些帧被存储在 中,直至达到其容量 。当容量 已满时,执行下一个操作。
2.帧删除与下采样: 在 中,通过对每个帧应用平均池化后计算余弦相似度来确定最相似的相邻帧对,该帧对中较旧的帧被淘汰,其空间信息通过平均池化降低到相应的空间尺度 ,然后传递到下一层:
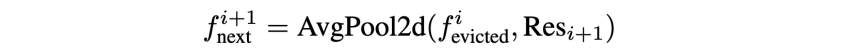
-
读取: 在从记忆库读取帧时,将所有层中存储的帧按时间顺序读出。
在线数据构造。 在在线微调阶段,我们从12个高质量的数据集中筛选出96K条数据,涵盖了时间和空间标注的多种任务类型,以提升模型在在线场景下的细粒度时空理解能力。这一阶段的核心目标是让模型能够准确理解、追踪和预测视频中的动态信息,同时确保模型在多轮交互中保持对话的连贯性和上下文一致性。
为此,我们采用了基于时间轴的任务插入策略,即:在视频时间线上合理插入查询(Temporally Random Insert),采用交错格式(Interleaved Format),确保任务在时间线上均匀分布,使模型能学习时间上下文随流式输入的变化关系。
我们选取了五大核心任务场景,分别来自12个不同的数据集,涵盖动作识别、目标跟踪、步骤定位、密集视频字幕、时空行为检测等任务。具体如下:
渐进式训练策略: 除了优化数据构造,我们还提出了一种新的训练策略,旨在解决现有多模态大模型在在线视频流理解方面的能力瓶颈。
我们认为,当前MLLMs的局限性不仅仅来自于数据不匹配,还与训练策略不适应流式视频处理密切相关。为此,我们设计了一种离线到在线(Offline-to-Online Learning)训练范式,该范式通过逐步增强模型的在线推理能力,使其能够从传统的离线视频理解平滑过渡到流式视频理解任务。训练初期,模型主要学习离线视频数据,构建稳固的基础视觉-语言理解能力。逐步引入在线视频任务数据,通过时间交错训练,使模型学会在线连续推理、动态信息检索、长时依赖建模等关键能力。
通过渐进式学习策略,使模型学会在线连续推理、动态信息检索、长时依赖建模等关键能力。
四、实验结果
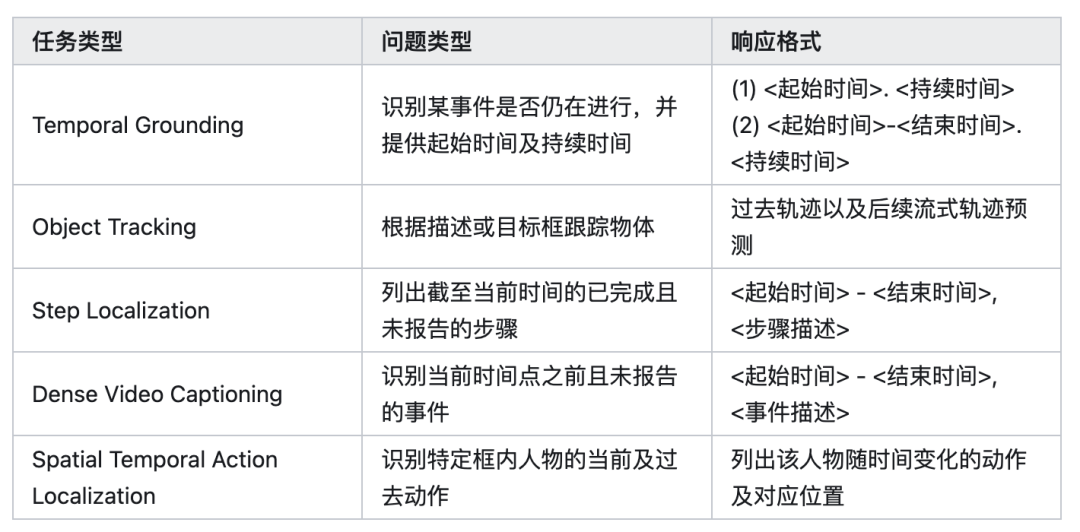
整体结果。 我们基于InternVL2-4B(集成InternViT-300M视觉编码器与Phi-3语言模型),通过架构优化与训练策略改进,构建VideoChat-Online-4B模型。在在线视频理解评测集OVBench中,VideoChat-Online以4.19%优势超越现有的开源先进模型Qwen2-VL 7B。
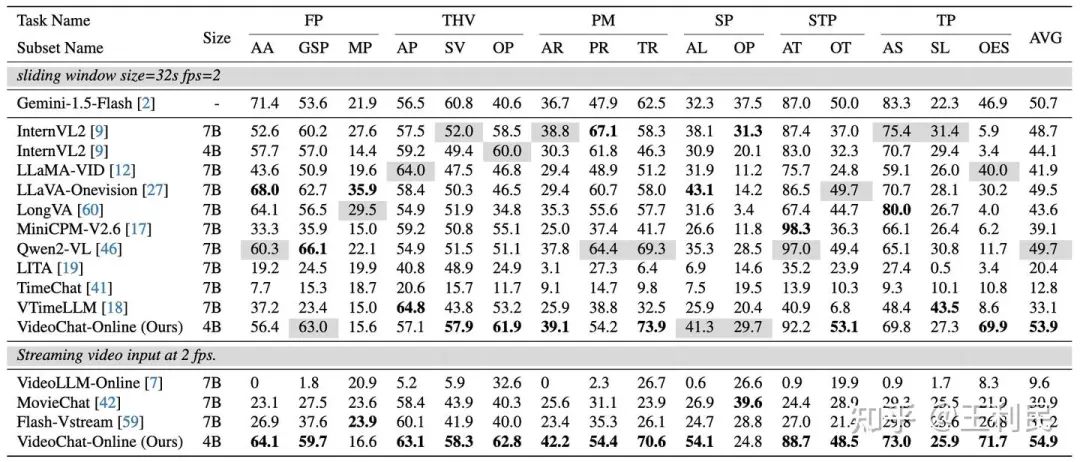
同时,在离线评测中亦展现出不错的性能。
我们选取了代表性消融实验展示。
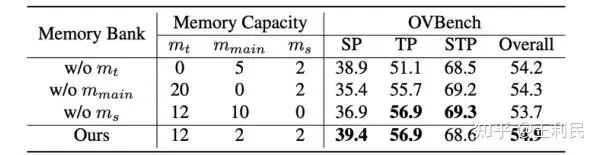
金字塔结构消融。 在实验中,我们将金字塔设置为3层,下表展示了每个记忆层的必要性(每层中的帧分辨率。通过比较第1行与第2、3行,我们发现增加空间信息的内存配置显著提高了空间感知(SP)任务的性能,而增加时间信息的内存配置有助于改善感知(TP)和时空感知(STP)任务的性能。这说明了我们金字塔记忆库设计的有效性。
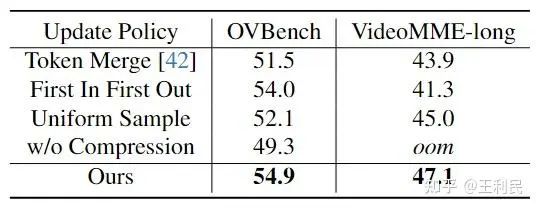
我们对各种记忆库中的token更新策略进行了对比分析,包括 Token Merge、FIFO 队列、均匀时间采样和非压缩帧输入。Token Merge策略更多的保持了视频帧的空间信息,而会损失时间信息;FIFO策略下模型会优先考虑最近的视频帧信息,而对之前的信息无法记忆;而均匀采样策略可能会忽略视频中的关键帧,导致理解性能的降低。而我们提出的方案避免了上述策略的缺陷,有效地平衡了视频的时间和空间信息。
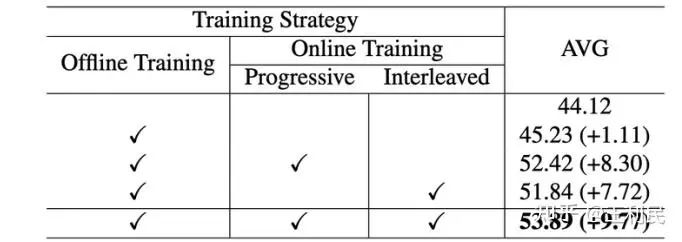
我们通过实验验证了训练策略对模型性能的关键影响:仅使用离线数据训练的基线模型准确率为45.23%,而通过引入在线数据(仅占总训练数据的6%),配合渐进式训练策略(先粗粒度时空建模,后细粒度优化),性能显著提升至52.42%(+7.19%),证明在线数据对时间上下文建模具有决定性作用。采用交织输入方式后,最终模型准确率达到53.89%,表明时序上下文关系学习能有效增强在线场景理解,凸显渐进式学习对时空多尺度特征提取的强化作用。
多轮对话在线场景的样例展示。 如图所示,我们在多轮对话场景下验证了在线数据的影响。结果表明,相较于仅基于离线训练的模型,经过在线微调(Online SFT)的模型能够更精准地输出目标的近似位置,并且在多轮对话中构建更连贯的上下文关联,显著提升模型在在线交互中的理解能力。在网站主页上展示了更多示例结果可供参考。

五、总结
本文针对在线视频理解领域中存在的不足之处,做出了以下贡献:(1)设计并提出了OVBench,这是一个全面的在线视频理解评测基准,旨在评估模型的实时时空理解能力;(2)开发了在线视频理解方法VideoChat-Online,能够有效地兼顾视频中的时间和空间信息,在在线和离线视频理解榜单中都取得了卓越的性能,其4B的参数量兼具了部署灵活性。这些创新为未来在线视频理解的研究和实际应用奠定了坚实的基础。

(文:极市干货)