

大型语言模型(LLMs)在生成信息时通常存在知识滞后和信息准确性不足的问题,这使得开发高效且精准的知识更新技术成为一项关键需求。
然而,现有的模型编辑方法仅限于编辑特定类型的知识,如三元组知识,无法满足更广泛、更复杂的知识编辑需求。因此,一个值得探索的重要问题是:能否设计一种能够编辑任意形式知识的模型编辑方法?
针对这一挑战,中国科学技术大学 LDS 实验室、新加坡国立大学 NEXT 实验室与浙江大学联合提出了 AnyEdit 方法。这是一种简单有效的自回归编辑范式,可以有效突破现有方法在知识长度和知识格式上的局限,支持任意形式知识的高效编辑。
AnyEdit 的出现为大型语言模型知识编辑技术的实用化进程提供了重要支持,推动了 LLM 向更加准确、更加实时的信息生成方向迈进。

论文标题:
AnyEdit: Edit Any Knowledge Encoded in Language Models
论文链接:
https://arxiv.org/pdf/2502.05628
代码链接:
https://github.com/jianghoucheng/AnyEdit

引言
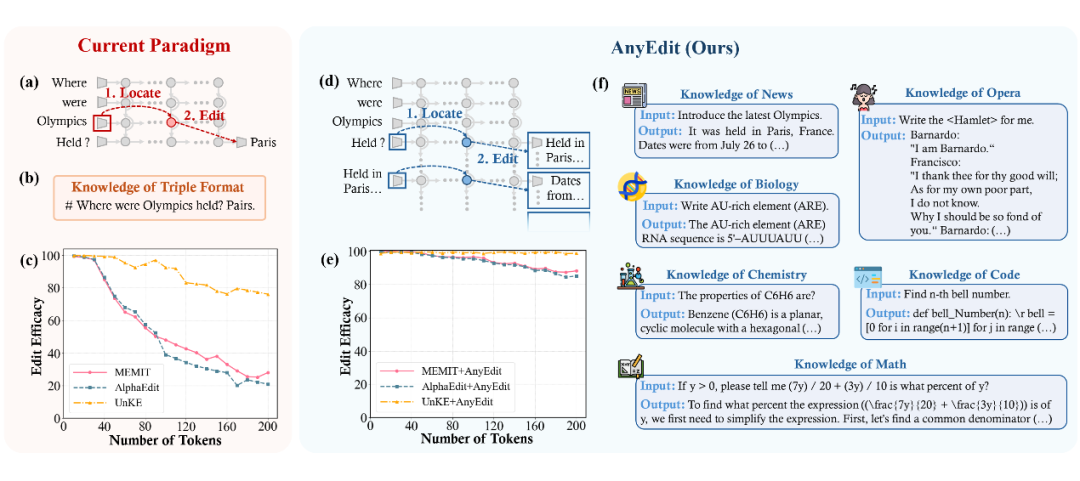
▲ 图1. 现有模型编辑方法与 AnyEdit 的比较
大型语言模型(LLMs)通过学习大量知识,在各类任务中表现出优秀的能力,但其生成的信息时常存在错误或过时现象,造成了可靠性问题。
例如,当用户询问「最新奥运会举办地」时,模型可能错误地回答「东京」而非正确答案「巴黎」。尽管通过重训练或微调能够部分解决该问题,但这些方法通常计算成本较高,并伴随过拟合风险。
近年来兴起的模型编辑技术可高效地修正 LLM 中的错误知识,其原理是通过定位关键令牌(例如「Olympics」)并修改其对应隐状态(如图 1(a)),实现无需全参数更新的知识修正。
然而,现有方法在长文本和多格式知识的更新方面面临严重瓶颈:主流方法(如 MEMIT [1]、AlphaEdit [2])难以有效处理超过 100 个令牌的知识编辑任务,且过度依赖于结构化的三元组知识表示,无法简单有效地适配数学推导、代码片段、诗歌等任意形式知识(如图1(c)、(f))。
现有模型编辑方法面临的核心问题在于单令牌编辑的效能壁垒:长文本知识通常包含多个关键令牌,且隐状态之间存在复杂的依赖关系,仅通过修改单个令牌隐状态(如图 1(a)中的步骤 2)难以保证整体知识的完整性与一致性。
为了解决这一难题,我们提出了一种简单有效的自回归知识编辑范式——AnyEdit。AnyEdit 的核心创新点包括:
序列分解:将任意形式的长知识序列分割为多个连续知识块,并逐块定位末端关键令牌(如数学推导中的公式符号);
迭代扰动:基于互信息链式法则,通过逐步扰动当前知识块末端令牌的隐状态,以自回归的方式引导后续知识块的精准生成(如图 1(d))。
得益于这一机制,AnyEdit 能够简单有效地实现知识编辑长度的自适应(动态确定所需编辑的令牌数量),并且通用性强,能够高效支持代码、诗歌、数学推导等多样化的任意形式知识编辑任务,从而突破了传统单令牌编辑方法的效能瓶颈。
我们在 Llama3-8B-Instruct 和 Qwen2.5-7B-Instruct 等主流模型上进行了系统的实验验证。
结果表明,在已有的 UnKEBench [3] 和 AKEW [4] 基准,以及新构建的 EditEverything 长文本多格式评测集(最长达 458 令牌,覆盖数学、代码等多种知识格式)上,AnyEdit 的编辑准确率相比 MEMIT 和 UnKE [3] 等主流方法提升了 21.5%,同时计算开销与现有方法基本相当。
此外,AnyEdit 还具备即插即用的框架特性,可以简单有效地赋能现有方法(如图 1(e)),从而推动 LLM 知识编辑技术向更加通用化与实用化迈进。

AnyEdit
首先回顾已有的编辑方法。为更新模型 中的过时或错误知识,现有模型编辑方法通常遵循 locate-then-edit 范式,其流程可分为两步:
定位关键令牌与影响层:识别输入提示 (如「最新奥运会举办地是?」)中的关键令牌位置 (如「奥运会」)及其对应的影响层;
编辑隐状态:通过扰动关键令牌的隐状态 ,使模型生成期望输出 (如「巴黎」)。
具体地,现有方法通过梯度下降求解残差项 ,以最大化模型在隐状态 下生成 的概率:
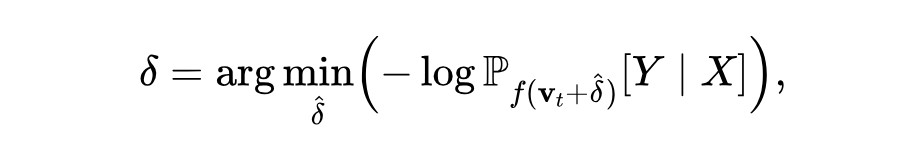
其中 表示将关键令牌隐状态替换为 后模型生成 的概率。最终,模型参数被更新以确保输入 时,关键令牌隐状态与 对齐。
尽管上述方法对于单令牌编辑已被广泛研究,我们认为其在更新长格式、多样化格式知识时存在根本性限制。本节将分析并实证验证这两大局限性。
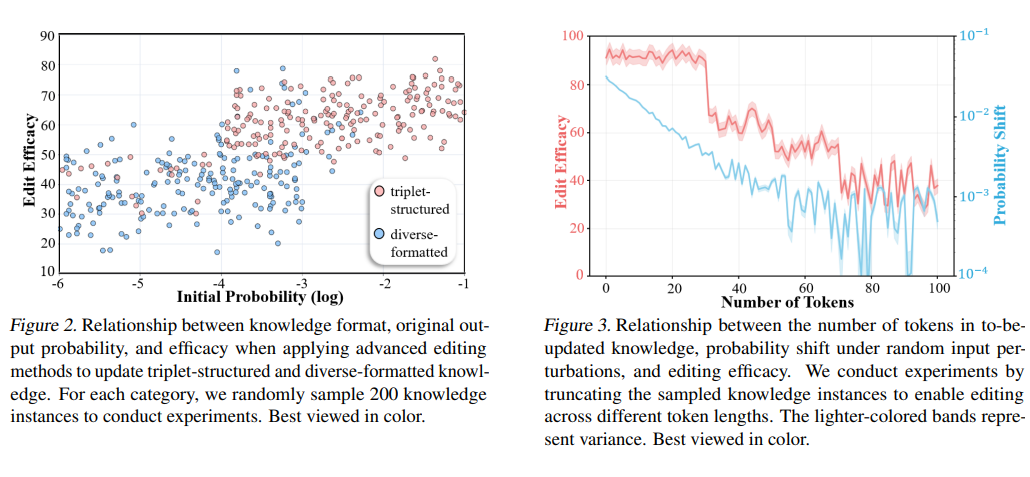
1. 多样化格式知识编辑的局限性
单令牌编辑方法的成功取决于施加扰动 于 后,LLM 是否能够生成 。换言之,扰动必须显著提升生成 的概率使其超越其他可能输出。
然而,当未编辑 LLM 中 的原始概率本身较低时(在代码片段、数学推导等多样化格式知识中尤为常见), 需要引发极大的概率偏移才能使 成为主导输出。受限于单令牌编辑的能力,现有方法往往难以应对此类场景。
这一局限性源于结构化知识(如事实三元组)相比多样化格式知识的简单性。三元组中修改单个令牌(如将“东京”改为“巴黎”)通常足够。而代码和数学等多样化格式知识需要跨多令牌的同步更新,因其涉及语法结构、变量依赖和层次关系。
为实证验证,我们在图 2 展示了知识格式、原始概率与编辑效能的关系。结果表明:具有较低原始概率的多样化格式知识表现出较差的编辑效能。简言之,低原始概率可能是更新多样化知识的根本限制。
2. 长文本知识编辑的局限性
近期研究表明,尽管 LLMs 采用注意力机制,但随着位置距离增加,远程令牌间的依赖关系会逐渐减弱。因此对于长输出 (如超过 100 令牌),输入令牌的扰动对后续令牌的影响力呈衰减趋势。此时,扰动 引起的 生成概率偏移可能过小,不足以使其超越其他潜在输出的概率。
为验证该结论,我们采用因果追踪(模型编辑常用策略)量化 扰动引起的 概率偏移。图 3 展示了 令牌数、概率偏移与编辑效能的关系。结果显示:受单令牌编辑影响较小的长格式知识表现出较差的编辑效能。换言之,单令牌编辑引起的低概率偏移成为有效更新长文本知识的内在限制。
结合两个限制,我们提出当前单令牌编辑范式面临理论效能壁垒。无论当前单令牌编辑方法如何优化,其编辑效能始终受限于理论上限。随着待更新知识的格式愈发多样、长度逐渐增长,该效能上限将不断降低直至失效。
为解决此问题,我们提出一个简单有效的方法,AnyEdit——一种支持多令牌协同更新的自回归编辑范式,其信息论理论基础请参考原文。
具体而言,AnyEdit 通过四步流程实现可扩展的知识编辑:
步骤1:分块输出
首先将目标输出 划分为多个知识块。我们提出两种分块策略:(1)固定令牌数的滑动窗口(2)基于自然语句边界的语义分割。这些策略赋予 AnyEdit 根据知识长度自动调节编辑令牌数的能力,确保高效无冗余的编辑。
步骤2:定位令牌与层
选取每个知识块 的末位令牌作为编辑目标,并沿用传统模型编辑方法直接应用因果追踪定位影响层。
步骤3:编辑隐藏状态
将输入 及先前知识块 输入 LLM,通过梯度下降编辑选定令牌的隐藏状态 以最大化 生成概率:
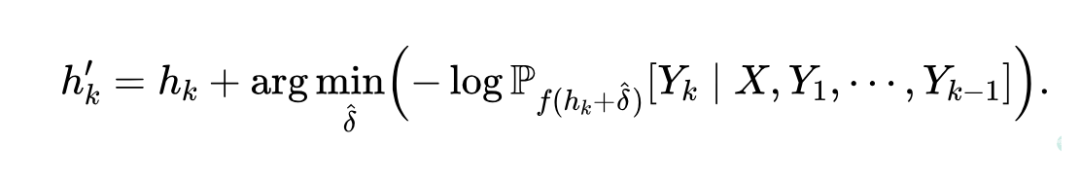
步骤4:更新模型参数
最终采用标准最小二乘优化更新 LLM 参数,使选定令牌的隐藏状态与编辑后状态对齐,该方法继承自现有模型编辑技术 [1]。
这种多令牌协同编辑机制使 AnyEdit 能够突破单令牌编辑的效能屏障。更重要的是,AnyEdit 可与现有方法无缝集成,使其具备编辑 LLM 中任意知识的能力,极大拓展了大模型知识编辑的适用范围与实用价值。

实验
为了更全面地评估了 AnyEdit 的有效性,我们在 UnKEBench、AKEW 和我们构建的 EditEverything 三个数据集以及多个大模型上与基线方法对比了编辑效果。部分定性和定量的实验结果如下表所示。更多结果烦请移步我们的文章或代码。
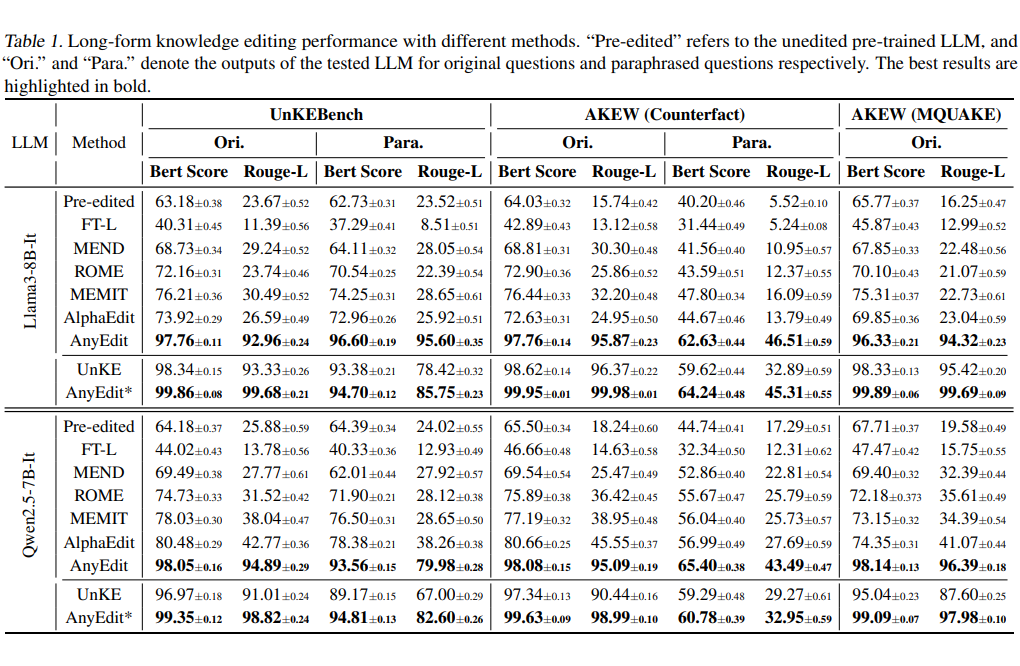
▲ 表1:各方法在长文本编辑效果上的对比
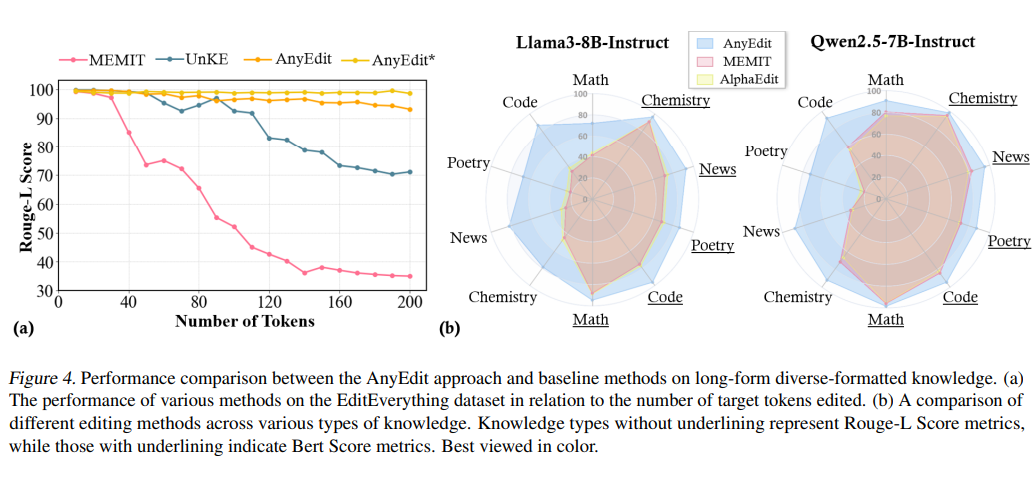
▲ 图4:各方法在长文本编辑效果上的对比

(文:PaperWeekly)