


NeurIPS 24 论文 “Interactive Deep Clustering via Value Mining” 提出在聚类过程中引入用户交互,通过询问少量高价值样本的类别从属关系,有效缓解了现有内部驱动的聚类方法面临的难样本问题,以较小的交互成本突破了聚类性能瓶颈。

论文标题:
Interactive Deep Clustering via Value Mining
论文地址:
http://pengxi.me/wp-content/uploads/2024/11/Interactive_Deep_Clustering_via_Value_Mining-1.pdf
代码地址:
https://github.com/XLearning-SCU/2024-NeurIPS-IDC

背景
聚类旨在按照语义将样本划分至不同的类簇。现有的聚类方法大多是内部驱动的,注重于挖掘样本自身有限的语义信息,进而导致其性能受限于数据自身固有的信息量,即存在性能瓶颈。
如图 1 所示,该瓶颈具体表现为,难以分辨位于不同类簇边界的样本。因此,引入合适的外部知识来帮助辨别和纠正这些难样本,能够有效地改善聚类性能,促进其在现实生活中的落地应用。

▲ 图1:现有的内部驱动聚类方法与我们提出的交互式聚类方法的比较。(a)现有的内部驱动聚类方法对难样本的区分度较差。以图中红圈内的一个难样本为例,该样本图片与邻居在视觉上相似,然而实际语义差距较大。这样的样本难以被内部驱动的聚类方法正确划分,进而导致了聚类性能上的瓶颈。(b)我们提出的交互式聚类方法,通过用户交互的方式对难样本进行辨别与纠正,从而突破内部驱动的聚类方法固有的性能瓶颈。

方法
针对内部驱动的聚类方法所遇到的难样本问题,我们提出了一种基于价值挖掘的交互式聚类方法(IDC)。给定预训练聚类模型,通过用户交互的方式,对难样本进行有效的辨别和纠正,从而显著改善模型聚类性能。所提出的 IDC 方法框架如图 2 所示。

▲ 图2:IDC 方法框架,包括用户交互和模型优化两个阶段。在用户交互阶段,对于给定的预训练聚类模型,从困难度、代表性和多样性三个角度,挑选出高价值样本,再向用户询问这些样本相对于其最近的若干个聚类中心的隶属关系。在模型优化阶段,依据用户的正/负反馈,使用相应的损失函数对聚类模型进行微调,同时对高置信度的样本采用规范化损失函数,来避免模型过拟合交互样本。
为了实现交互式聚类,需要解决两个关键问题:(1)如何构建高效且用户友好的交互方式(用户交互);(2)如何有效利用交互结果来改善聚类性能(模型优化)。
(1)用户交互
用户交互首先要高效。因此,选择用于交互的样本必须是高价值的,对改善模型聚类性能有显著帮助。具体而言,IDC 用困难度 、代表性 和多样性 三个指标来衡量样本的价值 :

其中, 表示第 个样本的价值。这三个指标的详细阐述如下:
困难度。预训练聚类模型通常能够准确地分配位于聚类中心附近的简单样本的类簇,但在处理位于类簇边界的难样本时表现不佳。换言之,辨别这些难样本对于改善聚类性能是非常关键的。因此,IDC 用样本离其最近的两个聚类中心的距离差来衡量样本的困难度:

其中 表示第 个样本的标准化特征, 和 分别代表该样本最接近和第二接近的聚类中心的表征。 越大,预训练模型在为第 个样本分配类簇时的不确定性就越高。
代表性。尽管纠正难样本对改善聚类性能是有效的,但只关注于难样本容易导致聚类结果欠佳。原因在于难样本中往往会有离群点的存在,会对模型的泛化能力产生负面影响。因此,在挑选高价值样本时,应该优先考虑位于高密度区域的样本。这样只需纠正单个样本,即可连带优化与其相邻的数个样本的类簇分配。
IDC 将样本的代表性定义如下:

其中 表示第 个样本的第 近邻, 代表邻居的数量(通常设为20)。 越大,第 个样本所处的局部结构就越为紧凑。
多样性。我们在实际应用中发现,如果只采用困难度和代表性两个指标,那么挑选出来的样本易出现类间分布失衡,聚集于少数几个类簇。因此,挑选样本的分布应该呈现多样性,以避免出现类塌缩的情况:

其中 表示当前已挑选样本集合的序号。需要指出的是,困难度和代表性指标是独立于挑选过程全局计算的,而多样性指标则是在挑选过程中逐步计算的。 越大,第 个样本与当前已挑选样本集合的差异就越大。
其次,交互过程要对用户友好。因此,用于交互的样本数量不能过多,并且要让用户容易做出判断。
交互数量。我们在 5 个数据集上均挑选了 M=500 个高价值样本用于交互,为完整数据集的 0.8%~3.8%。对于每次交互,用户大致需要 6 秒的时间进行判断,所以完成 500 次交互大致需要 50 分钟。
事实上,根据论文里提供的消融实验结果,仅需对 50 个样本进行交互(耗时 5 分钟),即可达到 500 个样本所带来性能提升的一半。实际应用中,用户可根据需要在时间和性能之间灵活地进行取舍。
交互形式。如图 2 所示,对于每个交互样本,IDC 向用户展示与该样本最接近的 T=5 个候选聚类中心,询问其中是否有与样本呈现相同语义的候选,相应得到正反馈或者负反馈。
值得注意的是,相比常见的直接询问类别和成对询问方式,IDC 的询问方式更加实用和友好。因为聚类通常是没有类别先验的,所以直接询问类别是不现实的。
而对于成对询问,IDC 提供了更多的参考,可以帮助用户更容易地做出判断。例如,在成对询问下,用户难以判断一张猫和一张狗的图片是否属于同一类,因为不清楚聚类的准则是‘猫-狗’还是‘动物-非动物’。
(2)模型优化
基于用户交互的结果,IDC 采用正样本损失函数 ,负样本损失函数 和规范化损失函数 对模型进行优化:

对这三个损失函数的详细阐述如下:
正样本损失。对于候选聚类中心里存在与样本呈现相同语义的正反馈,IDC 使用如下损失函数将样本与相同语义的聚类中心拉近:

其中 表示正反馈的数量, 表示类簇的数量, 表示第 个样本被模型识别为第 类的概率, 是一个指示变量,当用户认为第 个样本与第 类的聚类中心呈现相同语义时取 1,否则取 0。
负样本损失。对于候选聚类中心里没有与样本呈现相同语义的负反馈,IDC 使用如下损失函数将样本与所有候选聚类中心推远(实现时每轮优化将样本与候选中的随机一个中心聚类推远):
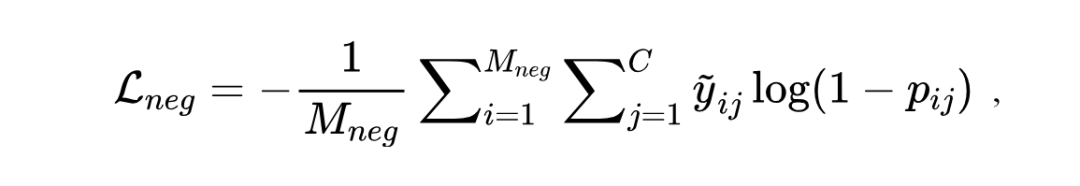
其中 表示负反馈的数量, 是一个指示变量,当该轮优化随机挑选第 类的聚类中心时取 1,否则取 0。
规范化损失。考虑到交互成本,IDC 仅仅选取了一小部分样本用于交互。如果只使用上述两个损失函数进行优化,容易导致模型过拟合这些交互样本,从而破坏原本正确的预测。因此,IDC 提出如下损失函数进行规范化约束:

其中 表示数据集样本数量, 表示置信度阈值, 是一个指示变量,当条件 cond 成立时取 1,否则取 0。
基于上述三个损失函数对模型进行 100 轮微调后,推理时直接从模型的聚类头得到聚类结果(如果预训练模型缺少聚类头,则需手动添加一个后再进行微调,细节可参考论文)。

实验
IDC 在五个经典数据的图像聚类数据集上对方法进行了验证,数据集概览可见表 1,结果如表 2 所示。

▲ 表1:数据集概览
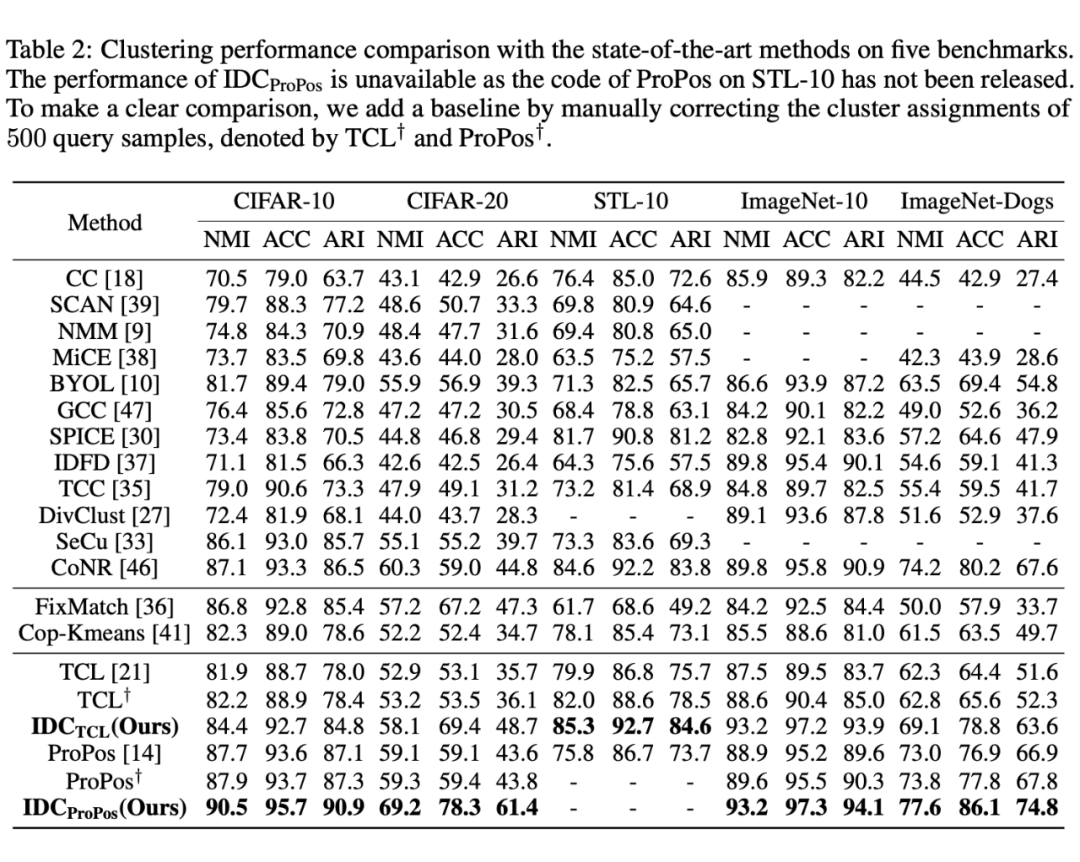
▲ 表2:IDC 在经典图像聚类数据集上的聚类性能
从表 2 中可以看出,IDC 有效地改善了两个内部聚类方法(TCL [1]、ProPos [2])的预训练模型的性能,尤其是在较为困难的 CIFAR-20 和 ImageNet-Dogs 数据集上。同时,与经典的半监督学习和聚类方法相比,IDC 都取得了显著的性能优势。更多实验结果详见论文。

结语
与现有的绝大多数聚类方法只挖掘内部语义信息不同,我们提出使用交互式的深度聚类方法 IDC,通过引入用户交互来解决现有方法面临的难样本问题,是此前团队在 TAC [3] 中提出的外部引导的聚类范式进行的一次全新的探索性工作。
通过挖掘高价值样本和设计高效的交互方式,本方法通过较小的交互成本,显著地提升了聚类算法的性能,有效地促进了深度聚类算法在现实生活中的落地应用。我们希望借由本工作,能够给聚类领域带来一些新的见解和想法。

(文:PaperWeekly)