

作者|沐风
来源|AI先锋官
就在谷歌宣布Gemini 2.5 Pro推出的当天,OpenAI紧随其后,在GPT-4o中推出了图片生成的新功能。
2024年5月,OpenAI正式推出GPT-4o,作为一个原生多模态模型,现在它能够直接从文本提示生成精确、逼真的图像。
据OpenAI官方博客,GPT–4o图像生成在准确渲染文本、精确遵循提示以及利用4o的固有知识库和聊天上下文方面表现出色,包括转换上传的图像或将其作为视觉灵感。这些能力使得创建图像更容易也更准确。
GPT-4o还支持多轮生成,用户可以通过自然对话来优化图像。
并且,由于GPT-4o是在聊天上下文中构建图像和文本,所以整个过程它可以完美的保持角色的一致性。
例如,当你设计一个视频游戏角色,在后续进行任何优化和试验时,该角色的外观可以在多个迭代中可以保持连贯。
我们先来看看OpenAI官方展示的案例。

下方这张图片则为通过对话进一步的修改结果:

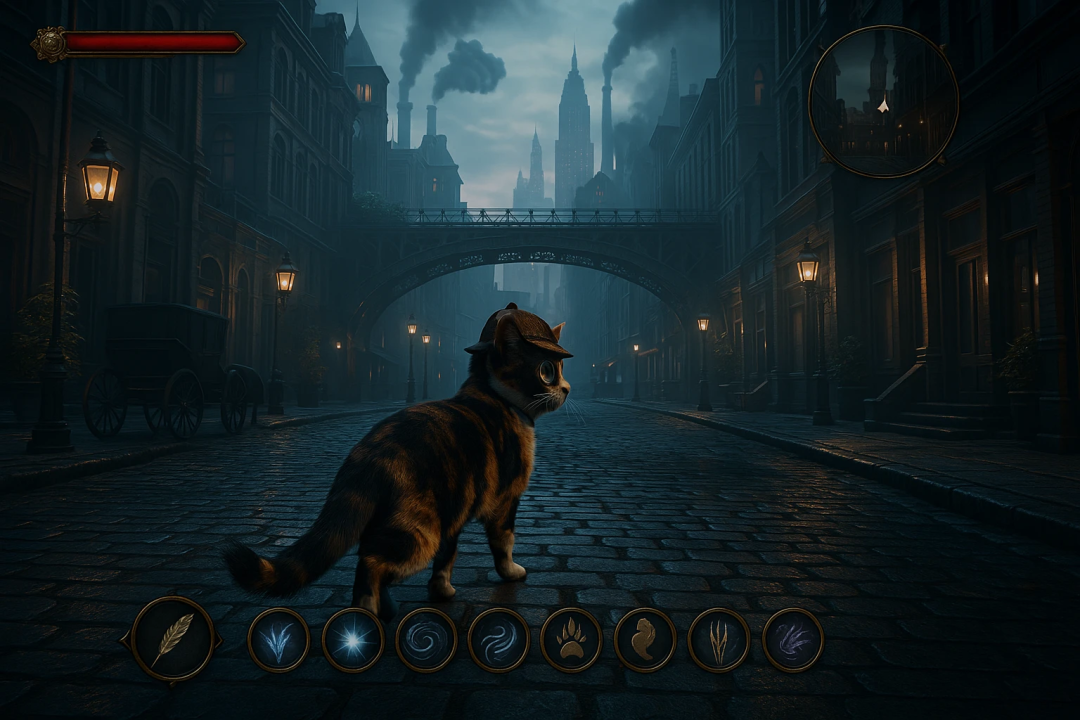
再比如给下面这只猫戴一顶侦探帽和单片眼镜。

你就会得到这张图片:

那再将其更新为横向图像16:9比例,在UI中添加更多法术,并取消缩放视觉对象,以便我们以第三人称视角看到猫走过蒸汽朋克曼哈顿,从而产生美丽的对比和照明,就像在最好的3A游戏中一样,具有冷色调。
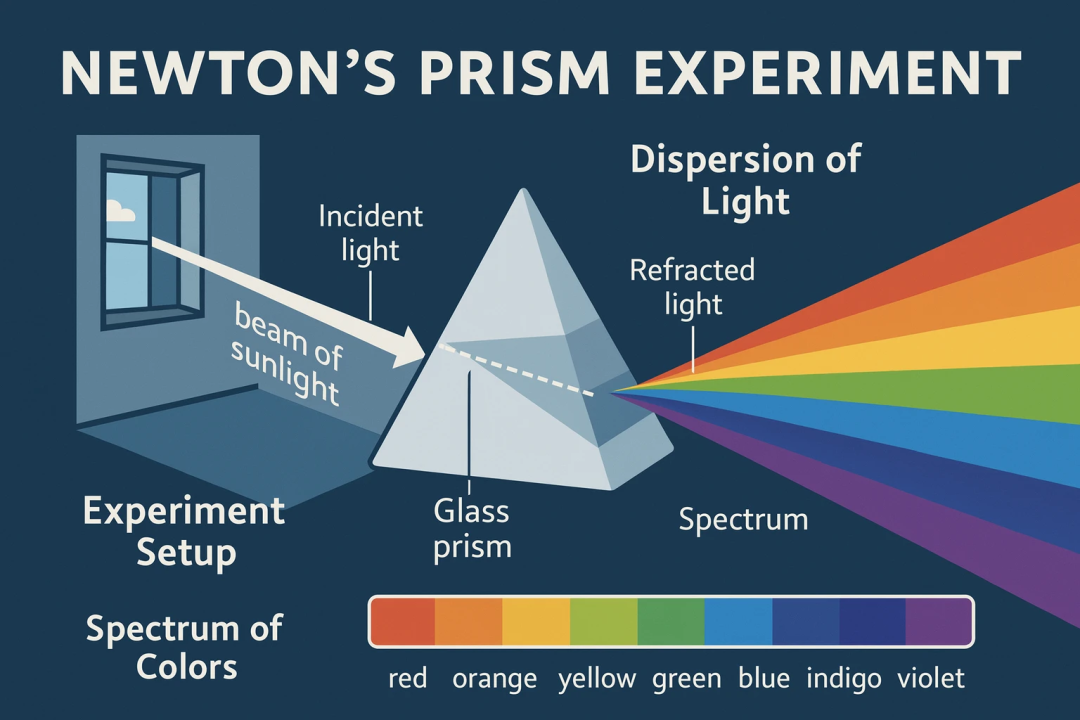
以前,在AI生成的图片中,文字往往会出现崩坏、乱码等问题,现在GPT-4o在生成文字能力上实现了跃升,无论是餐厅菜单、邀请函、科学实验示意图还是品牌宣传海报等,它都能搞定。



对此,让它制作一个漫画那也是手到擒来。

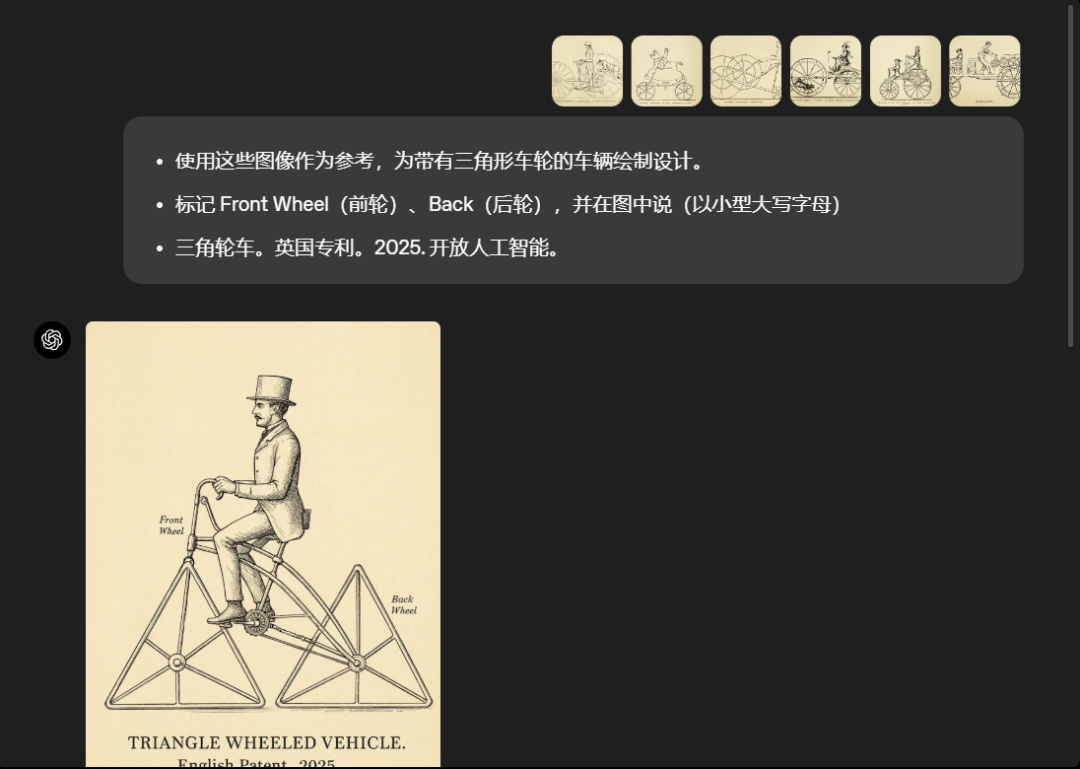
并且,GPT-4o的指令遵循能力也非常强,用户可以更精确的控制生成图像的内容,它还可以处理包含10-20个不同物体的场景,例如:

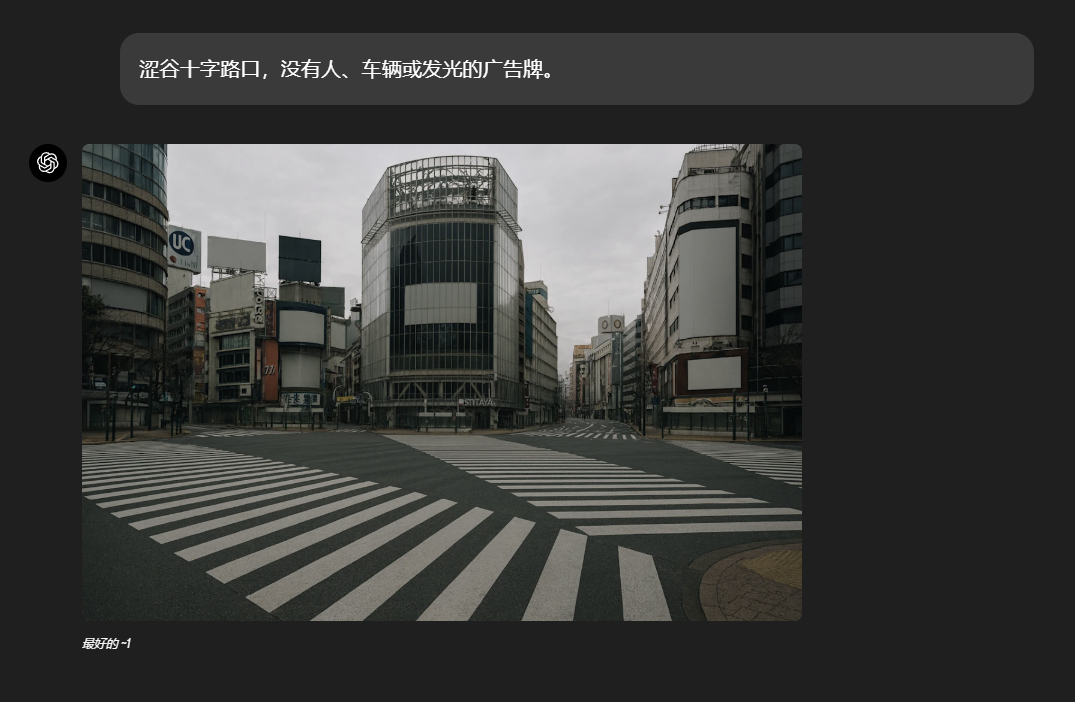
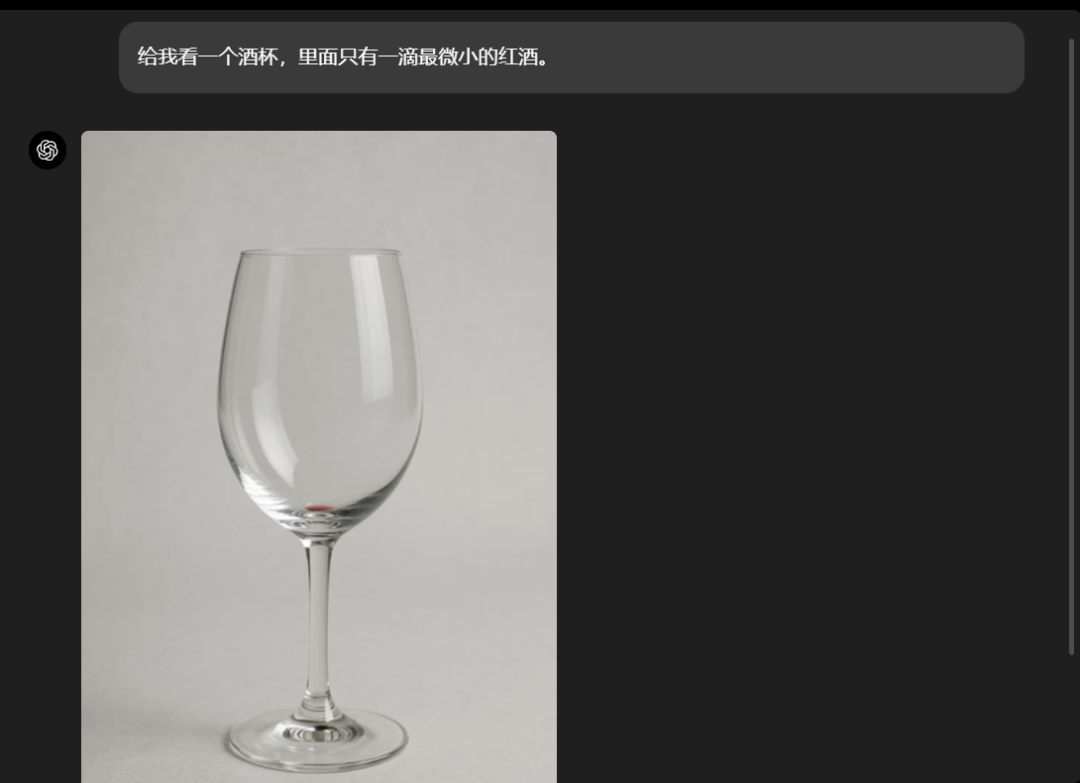
GPT-4o还可以直接从大模型中获取知识,从而生成与现实世界知识相符的图像。
例如使用代码生成图像:

抹茶的制作过程:

鸡尾酒配方:

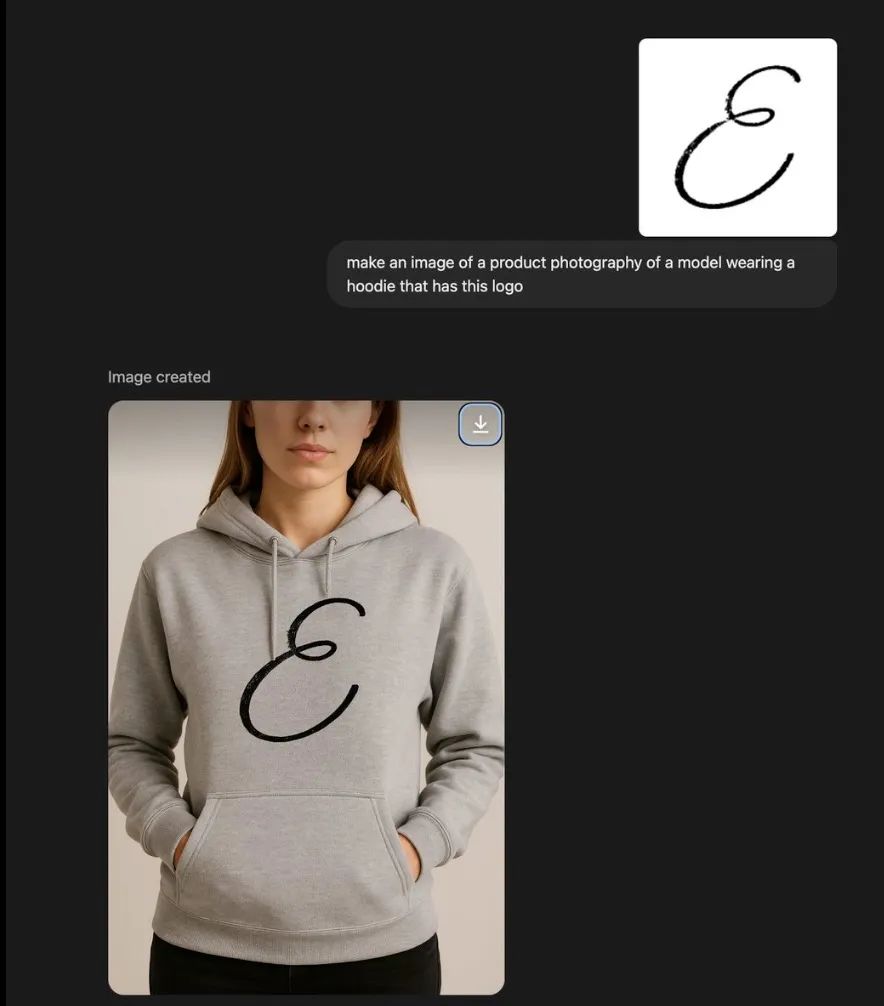
当然,也可以直接上传图片给GPT-4o,它可以分析和学习用户上传的图像,精准生成用户想要的图片,如:
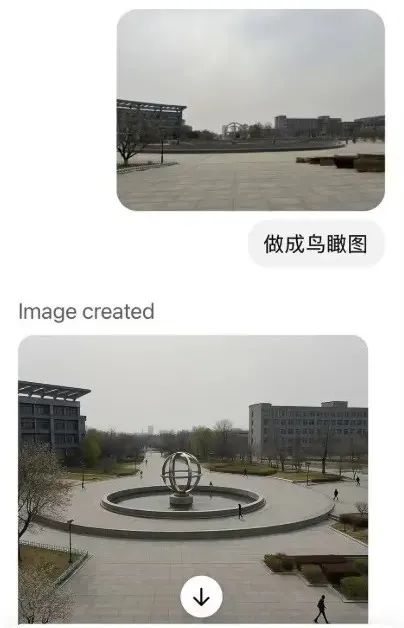

不过,GPT-4o也存在一些问题,如:
GPT-4o 偶尔会裁剪较长的图像,例如海报,尤其是在图片底部。

与文本模型一样,GPT-4o在图像生成时也有可能产生幻觉,尤其是在低上下文提示中。

在处理非拉丁语言时,字符也可能出现不够准确或产生幻觉等情况,尤其是在复杂性更高的情况下。

文本如果过于密集也不行。

并且,在生成依赖于其知识库的图像时,它可能难以一次准确呈现10-20个不同的概念,例如完整的元素周期表。

而且,在对图像特定部分(例如拼写错误)提出修改的请求时,可能会出bug,并且还可能以修改图像的其他部分或引入更多错误。

值得一提的是,从25日起,该功能向所有免费和付费用户推出,替换 DaLLE 作为默认图像生成器,并将在未来几周内向开发者开放API调用。
但免费版的每日图片生成数量仍然有限制(此前DALL-E为每天3张,GPT-4o具体数字暂未公布,但预计相似)。
另外,GPT-4o生成图片的速度略慢于之前的DALL-E 3。对此OpenAI表示,“这点延迟完全值得,因为图片质量和知识整合的提升远超等待几秒带来的不便。”
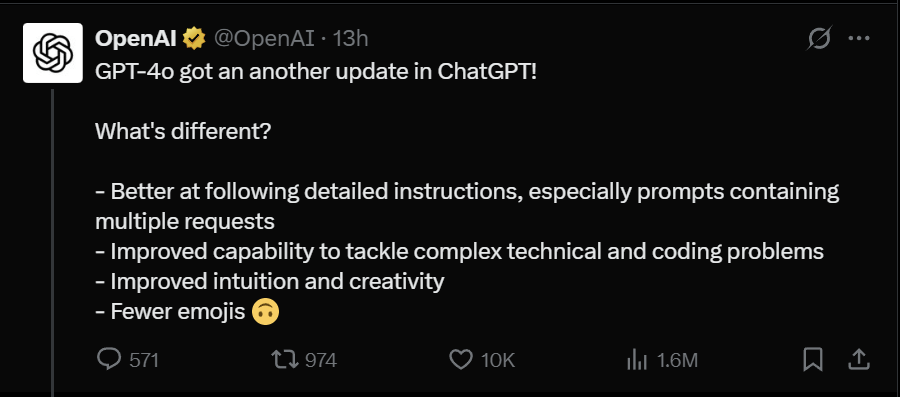
并且,就在今天凌晨,OpenAI在X上宣布GPT-4o再次迎来升级。
•更擅长理解并执行详细的指令,尤其是同时包含多个请求的提示。
•在处理复杂的技术问题和编程任务时表现更佳。
•直觉和创造力进一步提升。
•更少使用表情符号。
并且,升级后的GPT-4o现已对所有付费用户开放,免费用户将在未来几周内陆续体验到。
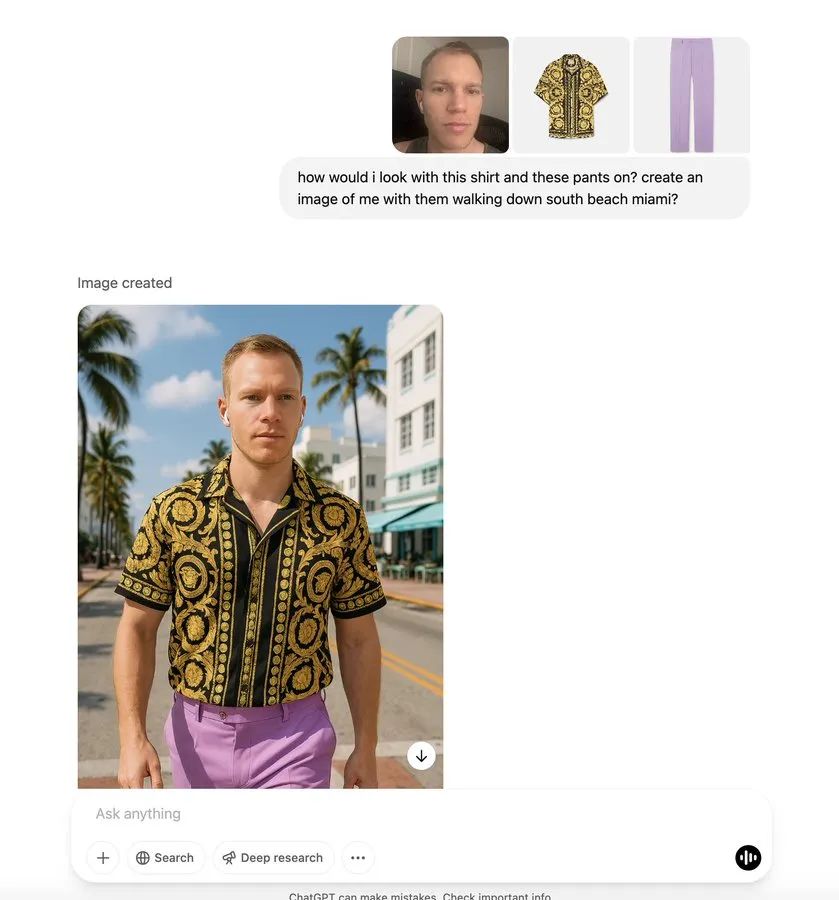
目前,已经有许多网友在X上发布了自己生成的图片,就让我们一起来看看吧。
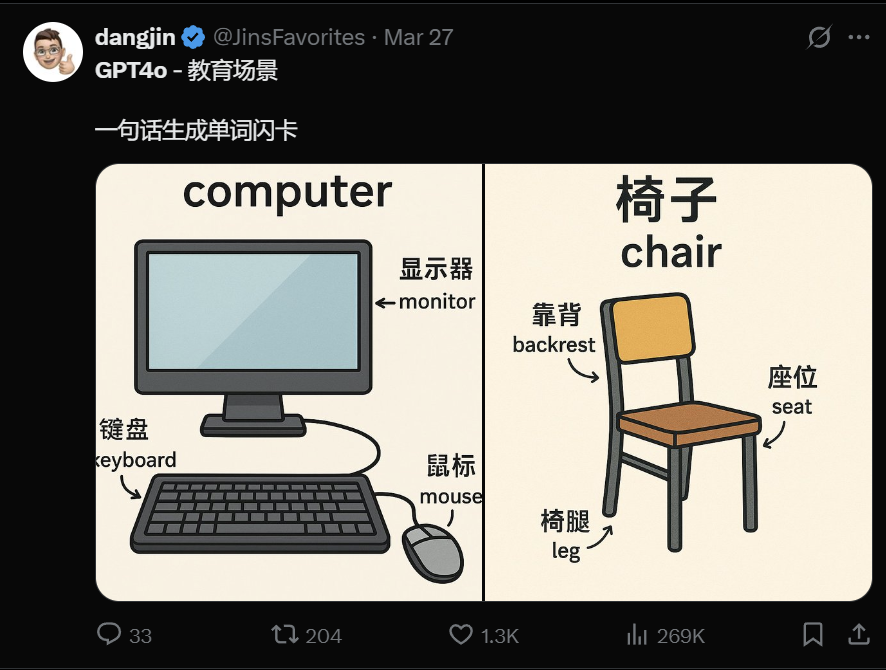
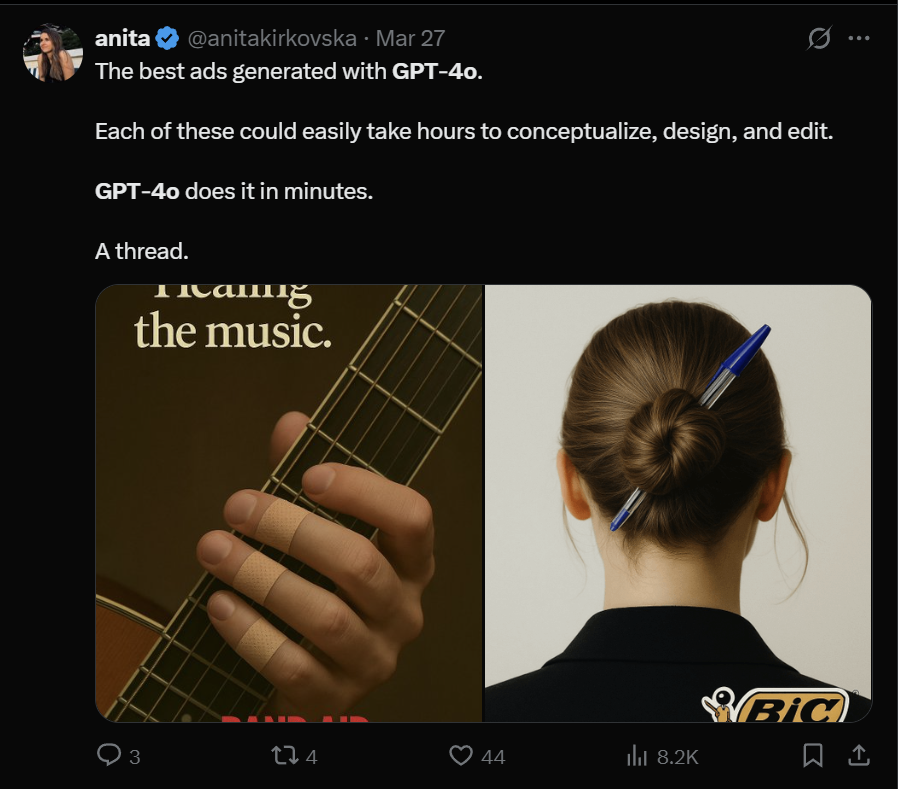
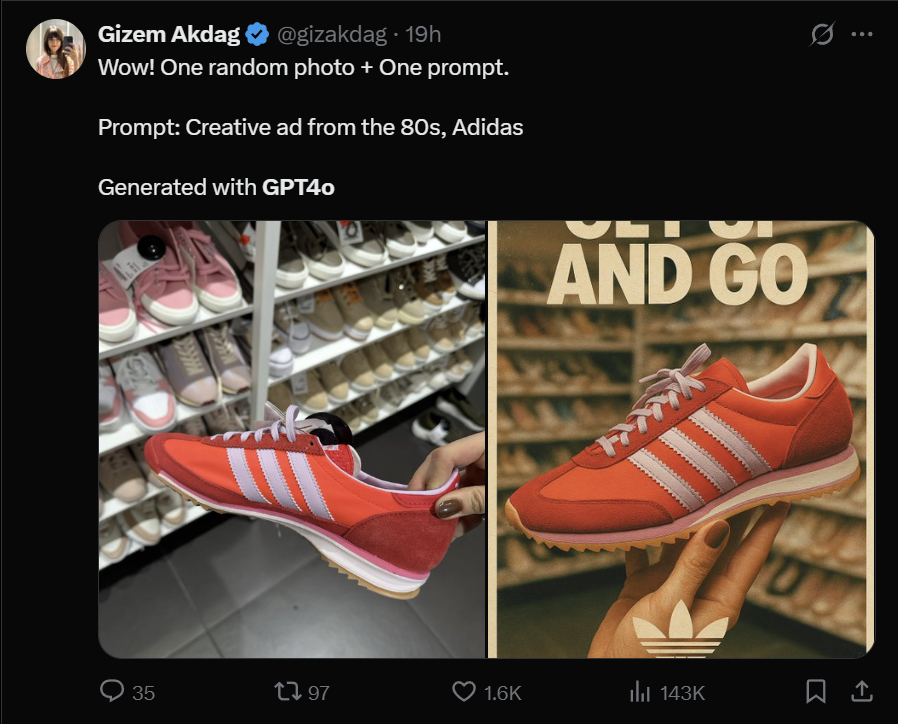



有意思的是,吉卜力风在X上一夜爆火,网友纷纷开始用GPT-4o生成吉卜力工作室风格的图片。




感兴趣的小伙伴赶快去试试吧!
(文:AI先锋官)