

极市导读
一种高效的自回归视频生成方法,通过非量化建模和双向注意力机制,显著降低了训练成本并提升了生成质量,同时在文本到图像和视频任务中展现了强大的zero-shot泛化能力。>>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 NOVA:无需矢量量化的自回归视频生成
(来自 BAAI,中科院)
1 NOVA 论文解读
1.1 NOVA 模型
1.2 视频生成中的自回归建模
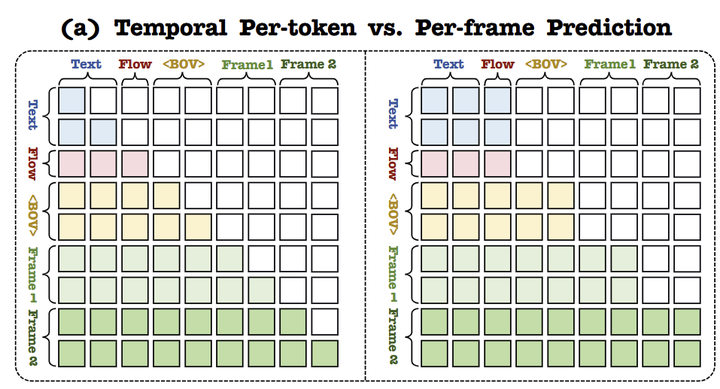
1.3 帧间时序自回归建模:自回归地预测时序的每一帧
1.4 帧内空间广义的自回归建模:set-by-set 地预测
1.5 对每个 token 预测使用 Diffusion Loss
1.6 NOVA 训练数据集
1.7 NOVA 架构和训练
1.8 NOVA 实验结果
太长不看版
自回归视频生成 (Emu3) + Diffusion Loss (MAR)。
NOVA 是一种自回归视频生成技术,而且不涉及 Vector Quantization 的过程。NOVA 在帧间,时序上,采用标准的自回归 frame-by-frame prediction;在帧内,空间上,采用 MAR 式的 set-by-set prediction。
NOVA 在帧间保持了 GPT-style 的 causal 模式,以使得整个模型有灵活的 in-context 能力,那么在帧内有使用 bi-directional attention,效率高。
NOVA 特点:
-
NOVA 首先按顺序预测 temporal frames,然后预测每一帧内的 spatial sets。 -
NOVA 第一个把 MAR 的 Non-quantized 思路用在了视频生成。
NOVA 硬指标:
视频生成:VBench 80.1
文生图:GenEval 0.75
下面是对本文的详细介绍。

1 NOVA:无需矢量量化的自回归视频生成
论文名称:Autoregressive Video Generation without Vector Quantization (ICLR 2025)
论文地址:
http://arxiv.org/pdf/2412.14169
项目主页:
http://github.com/baaivision/NOVA
1.1 NOVA 模型
在视觉生成领域,基于自回归的方法通常使用矢量量化 (Vector Quantization) 将图像或视频转换为 discrete tokens。然而,vector quantization tokenizer 同时实现高保真度和高压缩比很有挑战性。高质量意味着需要的 token。因此,随着视频中图像分辨率更高,视频更长,成本会大幅增加。
相比之下,视频扩散模型[1][2][3]在紧凑的 Continuous Latent Space 中使用高度压缩的视频序列进行学习。然而,它们中的大多数只学习固定长度的帧的联合分布,缺乏生成不同长度的视频的灵活性。更重要的是,它们不具备自回归模型的 in-context 能力,即使用统一的模型 (例如 GPT) 在 in-context 地解决不同的任务。
NOVA 实现了高效率的自回归视频生成。
NOVA 的做法是:依然使用自回归建模,但不使用 Vector Quantization。同时,把 Video Generation 的问题转化为 frame-by-frame prediction 和 spatial set-by-set prediction 的问题。
NOVA 受 Emu3[4]对于自回归视频生成的启发,以及受 MAR[5]对于non-quantized 自回归图像生成的启发,把视觉 token 表示为 non-quantized 向量,set-by-set 地执行自回归预测。
具体来说,NOVA 在时间维度上 causal 地预测每个 frame,在空间维度上 random 地预测每个 token set。通过 Non-quantized tokenizer 和灵活的自回归框架,NOVA 同时实现:1) 高保真度和紧凑的视觉压缩,使得训练和推理成本较低,2) 在统一模型中集成多个视觉生成任务的 in-context 能力。
1.2 视频生成中的自回归建模
视频生成中的自回归建模主要有 2 种方法。
1) 以 raster-scan order 逐 token 地生成
这种方法在视频帧序列内执行 causal per-token prediction,根据 raster-scan order 依次解码视觉 token,定义如下:
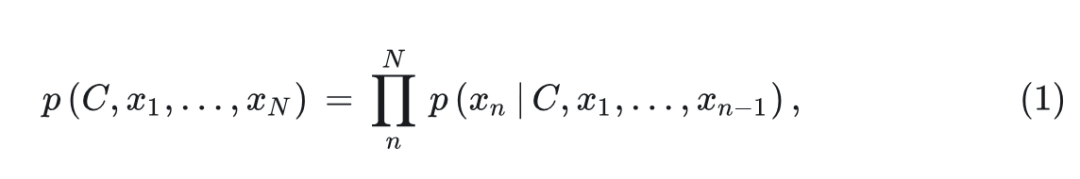
其中, 代表所有 video token, 为 个 video raster-scale tokens 中的第 个, 为各种各样的 condition 上下文(比如 label,text,image)。
2) 以 random order masked set-by-set 地生成
这种方法平等对待每个视频帧中的所有 token,使用 Bi-directional Transformer[6]的 Decoder 进行 set-by-set 地预测。
但是,这种模型是在很多长度固定的视频帧上训练的,可能导致上下文的可扩展性较差,且在长时间的视频的情况下有连贯性问题。
NOVA 提出了一种新颖的解决方案:在单个视频帧中使用 per-set 生成,对整个视频序列使用 per-frame prediction,把每帧内部生成的范式和帧间生成的范式解耦。这样的做法允许 NOVA 更好地处理时间因果关系和空间关系,提供更灵活和可扩展的自回归框架。
1.3 帧间时序自回归建模:自回归地预测时序的每一帧
NOVA 在帧间执行时序自回归建模,即自回归地预测时序的每一帧,如下图 2 所示。
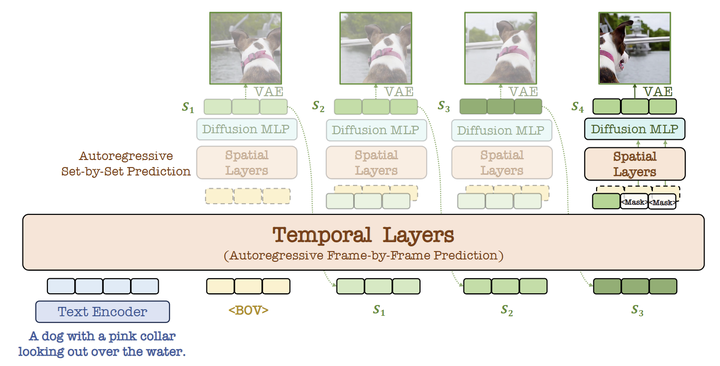
NOVA 使用 Phi-2 编码 text 信息。为了更好地控制视频动态,使用 OpenCV (cv2) 来计算采样视频帧的光流。平均 flow magnitude 用作 motion score 并与 prompt 集成。
VAE 采用开源的 3D VAE[7],temporal stride 为 4,spatial stride 为 8,将视频帧编码到 latent space。
Patch Embedding 层的 stride 为 4,将 latent video 的 channel 对齐,使其可以输入后续的 Transformer 中。
视频帧可以自然地被视为 causal 序列,每帧充当自回归生成的 meta unit。
NOVA 实现了图 3 中的 block-wise causal masking attention,确保每一帧只能关注 text prompts,video flow 以及前一帧,同时允许所有当前帧的 token 彼此可见:
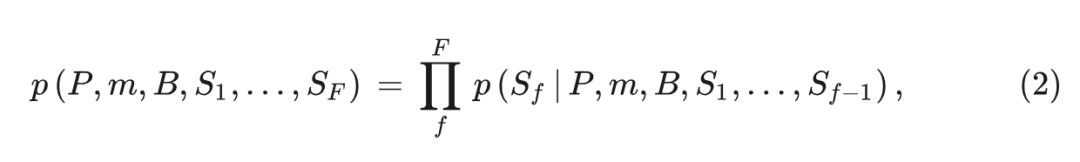
其中, 代表 video frame 的数量, 分别是 text prompts 和 video flow, 代表第 帧的所有的 tokens, 代表 learnable begin-of-video(BOV)embeddings,用于预测初始的 video frame(其数量等于单帧的 patch 数)。根据式 2:
可以把 text-to-image 和 image-to-video 的过程写为 和 。其中, 代表根据 text prompts 和 video flow 和 begin-of-video(BOV)embeddings,来预测第1 帧 , 代表根据 video flow,begin-of-video(BOV)embeddings 以及前 帧来预测第 帧 。
这种范式可以大大提高训练效率,并允许 KV-cache 在推理过程中快速解码。
1.4 帧内空间广义的自回归建模:set-by-set 地预测
受 MaskGIT[8]和 MAR[5]的启发,作者使用 MAR 的 generalized 自回归过程来生成每个 frame 的 tokens,并借助高效的并行解码。如图 4 所示是帧内广义的空间自回归过程。作者利用 indicator features 来辅助空间层,逐渐解码图像中所有随机 masked 的 token set。这种方法会导致随着帧数的增加,图像结构崩溃以及视频流畅度不一致。作者觉得这是因为相邻帧的 indicator features 相似,使得在没有显式建模的情况下很难准确地学习连续和难以察觉的运动变化。此外,在训练期间从真实上下文帧导出的 indicator features 有助于空间 AR。
作者引入了一个 Scaling 和 Shift Layer,通过学习统一空间中的相对分布变化来重新制定跨帧运动变化。具体做法是把 temporal layers 的 BOV-attended output 经过 MLP 之后再经过 Scaling 和 Shift Layer。使用 unmasked 的 token,作者 set-by-set 地预测 random masked 的视觉 token:
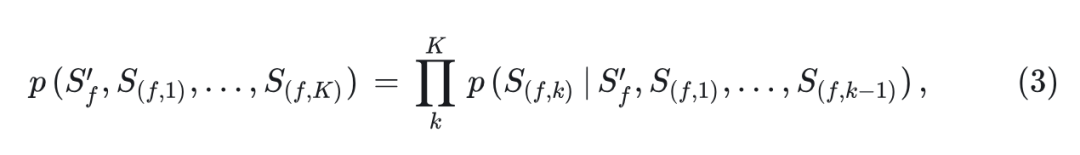
其中, 代表 indicator features,其目的是生成第 帧。 代表第 帧的第 个 token set。 是这图片一共的 set 数。
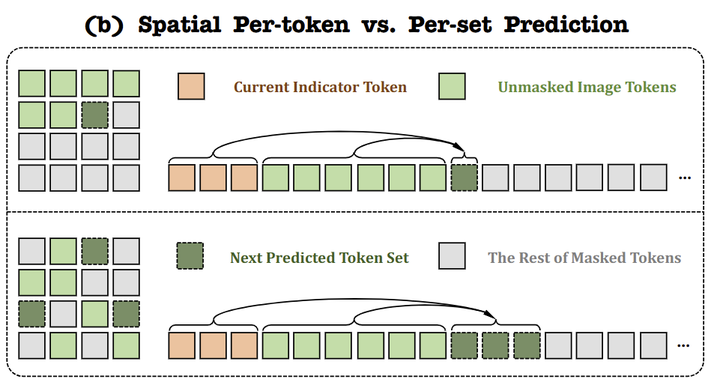
在帧内,相当于是做广义的空间自回归预测,可以实现高效的推理,以及并行解码。
值得一提的是,作者为 temporal and spatial AR layers 的残差连接之后增加了 post-norm layers。
1.5 对每个 token 预测使用 Diffusion Loss
在训练期间,NOVA 按照 MAR[5]的做法使用 Diffusion Loss 来估计连续值空间中的 per-token 概率。例如,将 GT token 定义为 ,NOVA 的输出定义为 。损失函数可以表述为:
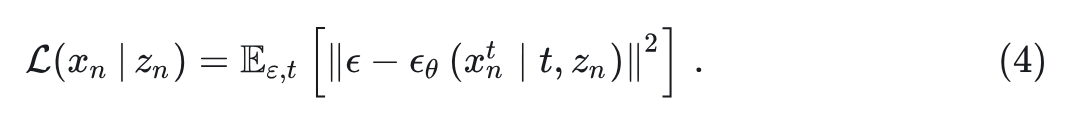
其中, 是从 中采样的高斯噪声向量,噪声数据为 为 noise schedule。 是扩散模型(一个 MLP)。
的意思是以 为 condition,以 为输入。
NOVA 按照 MAR[5]的做法为每个图像在训练期间将 采样 4 次。
在推理过程中,作者从随机高斯噪声 中采样 ,并通过 对 进行逐步去噪,直到采样获得 。其中, 是第 步的噪声等级, 是从随机高斯噪声 中采样的。
1.6 NOVA 训练数据集
首先做了 16M image-text pairs,从 DataComp,COYO,Unsplash 以及 JourneyDB。然后把数据集扩展到约 600M image-text pairs,通过从 LAION、DataComp 和 COYO 中选择美学分数最小为 5 的图像。
选择 19M video-text pairs,来自 Panda-70M 的子集。以及内部的 video-text pairs。
从 Pexels 选择 1M 高分辨率 video-text pairs。最大文本长度为 256。
1.7 NOVA 架构和训练
Spatial AR 层和 denoising MLP block:来自 MAR 的设计。
temporal encoder, spatial encoder,decoder:16 层,dimension 分别为 768 (0.3B), 1024 (0.6B) 和 1536 (1.4B)。
denoising MLP:3 层,1280 维度。
Spatial layers 使用 MAR 的 encoder-decoder 架构。
预训练的 VAE 来自 Open-sora plan,时间维度上 4× 压缩,空间维度上实现 8×8 压缩。
masking schedulers 使用 MAR 思路,diffusion schedulers 使用 IDDPM。训练 1000-step noise schedule,推理 100 steps。
从头开始训练 text-to-image 模型,然后加载这些权重来训练 text-to-video模型。
评测:
T2I:T2I-CompBench, GenEval 和 DPG-Bench。
T2V:VBench 来评估文本到视频生成在 16 维方面的能力。
对于给定的文本提示,随机生成 5 个样本,每个样本视频大小为 33×768×480。
采用 classifier-free guidance,值为 7.0,以及 128 个自回归步骤,以提高所有评估实验中生成的图像和视频的质量。
1.8 NOVA 实验结果
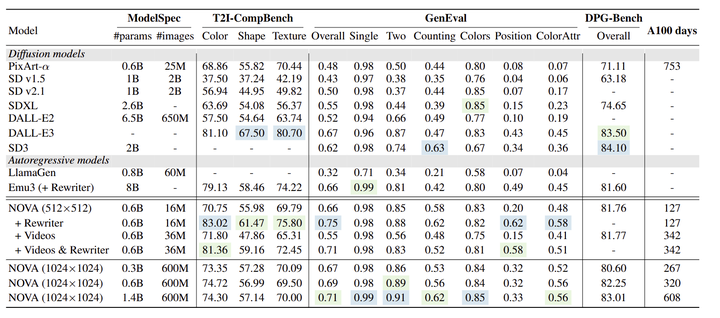
NOVA 优于现有的文生图模型,具有卓越的性能和效率。
图 5 将 NOVA 与最近的几个文生图模型进行比较,包括 PixArt-α、SD v1/v2、SDXL、DALL-E2、DALL-E3 、SD3、LlamaGen 和 Emu3。NOVA 在 GenEval Benchmark 中实现了最先进的性能,尤其是在生成指定数量的目标方面。值得注意的是,NOVA 在 T2I-CompBench 和 DPG-Bench 上也取得了领先的结果。VOVA 文生视频模型优于大多数专门文生图模型,例如 SD v1/v2、SDXL 和 DALL-E2。
NOVA 与文生视频扩散模型性能相当,超过自回归模型。作者进行了一项定量分析,将 NOVA 与开源和专有的文本到视频模型进行比较。如图 6 所示,尽管 NOVA 小得多 (0.6B 与 9B),但在各种文本到视频评估指标中,NOVA 显著地优于 CogVideo。它还匹配最新的 SOTA 模型 Emu3 的性能 (80.12 vs. 80.96),且模型尺寸明显更小 (0.6B vs. 8B)。此外,作者将 NOVA 与最先进的扩散模型进行了比较,例如 Gen-2、Kling 和 Gen-3 ,以及 LaVie、Show-1、AnimateDiff-v2、VideoCrafter-v2.0、T2V-Turbo、OpenSora-v1.1、OpenSoraPlan-v1.1/v1.2 和 CogVideoX。NOVA 缩小了自回归架构和扩散模型之间的差距,提高了视频生成的质量和指令跟踪能力。此外,在推理延迟方面,NOVA 比现有模型表现出显著的速度优势。
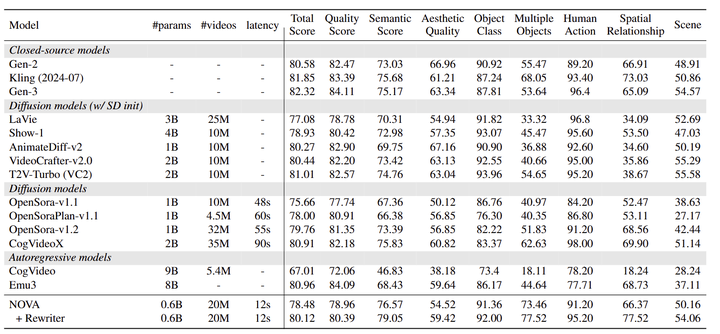
图 7 中展示了定性比较结果。 NOVA 在一系列提示样式中表现出强大的视觉质量和保真度,并且在颜色属性绑定和空间对象关系方面表现出色。图 8 中展示了文生视频的可视化,突出了 NOVA 能够根据提供的文本提示捕获多视图视角、平滑对象运动和稳定的场景转换的能力。


通过预填充参考图像,NOVA 还可以从图像生成视频,无论是否附带文本。图 9 提供了一个示例。我们表明,NOVA 可以在没有文本提示的情况下模拟真实的运动。此外,当包含文本时,透视运动显得更加自然。这表明NOVA 能够捕获基本物理,如相互作用力和流体动力学。

参考
-
Video generation models as world simulators -
Kling ai -
Stable video diffusion: Scaling latent video diffusion models to large datasets -
Emu3: Next-Token Prediction is All You Need -
Autoregressive image generation without vector quantization -
Magvit: Masked generative video transformer -
Open-sora plan: Open-source large video generation model -
Maskgit: Masked generative image transformer
(文:极市干货)