

 随着人工智能的飞速发展,大语言模型(LLMs)正在改变众多领域。但在金融领域,通用推理模型面临诸多挑战,如数据碎片化、逻辑不可控和业务泛化能力不足。为此,上海财经大学张立文教授团队(SUFE-AIFLM-Lab)联合财跃星辰,经过数月努力,推出了专为金融推理设计的 Fin-R1 模型。本文将深入剖析 Fin-R1 的背景、原理、特点、应用场景、性能和部署方法,为金融技术从业者提供一份详尽指南。
随着人工智能的飞速发展,大语言模型(LLMs)正在改变众多领域。但在金融领域,通用推理模型面临诸多挑战,如数据碎片化、逻辑不可控和业务泛化能力不足。为此,上海财经大学张立文教授团队(SUFE-AIFLM-Lab)联合财跃星辰,经过数月努力,推出了专为金融推理设计的 Fin-R1 模型。本文将深入剖析 Fin-R1 的背景、原理、特点、应用场景、性能和部署方法,为金融技术从业者提供一份详尽指南。Fin-R1 是上海财经大学联合财跃星辰推出的金融领域推理大模型,基于 Qwen2.5-7B-Instruct 架构,经监督微调(SFT)和强化学习(RL)两阶段训练,在约 6 万条高质量思维链数据上学习。其 70 亿参数的轻量化设计降低了部署成本,在权威评测中平均得分 75.2 分,仅次于 DeepSeek-R1。它能处理金融推理、决策等复杂任务,支持多语言,在智能风控、投资决策等多场景应用,为金融领域提供强大且高效的智能化支持 。
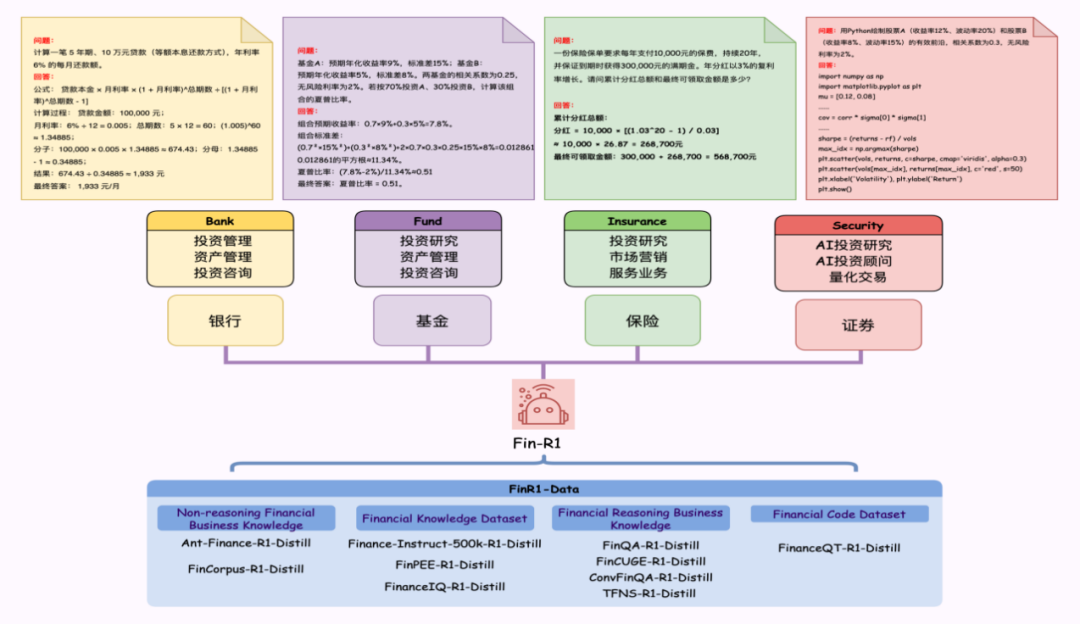
二、技术原理
(一)模型架构
Fin-R1 基于 Qwen2.5-7B-Instruct 架构,这一架构在处理自然语言理解和生成任务方面展现出了卓越的性能。通过采用轻量化的 7B 参数设计,Fin-R1 在保证模型具备强大推理能力的同时,显著降低了部署成本,使其能够轻松适应各种资源受限的环境,无论是小型金融机构的本地服务器还是大型金融企业的云平台,都能实现高效运行。
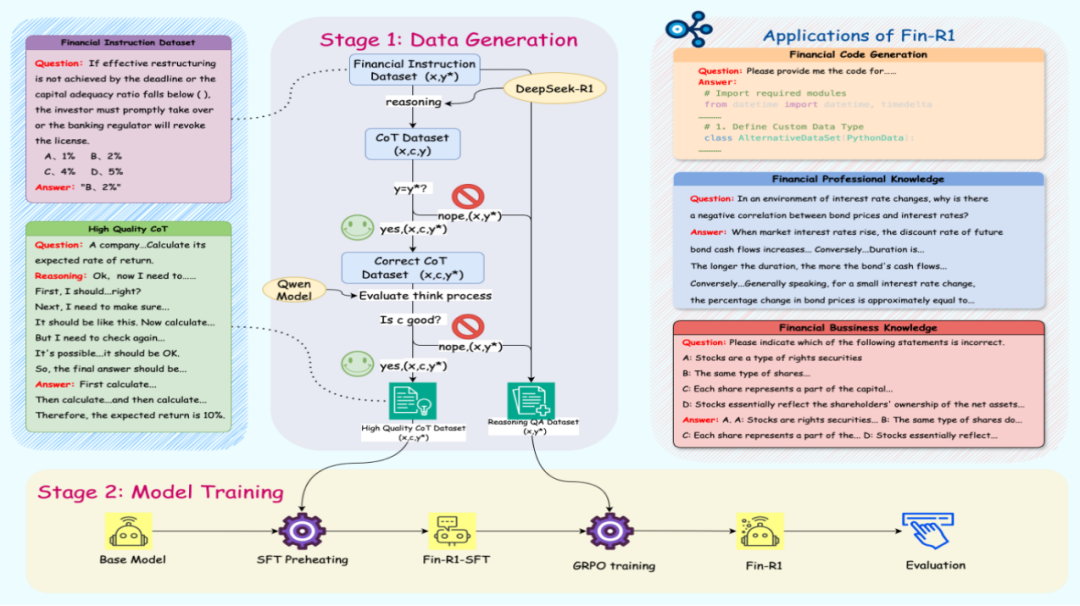
(二)数据构建
Fin-R1 的数据构建是其核心技术之一。为了克服金融数据碎片化的问题,项目团队精心构建了高质量金融推理数据集 Fin-R1-Data,该数据集包含约 60,091 条面向专业金融推理场景的高质量思维链(COT)数据。在数据收集过程中,团队从多个权威数据源进行领域知识蒸馏筛选,确保数据的全面性和专业性。同时,采用“答案 + 推理”双轮质量打分筛选方法,对数据的准确性和逻辑性进行严格把关,从而为模型的训练提供了坚实的数据基础。
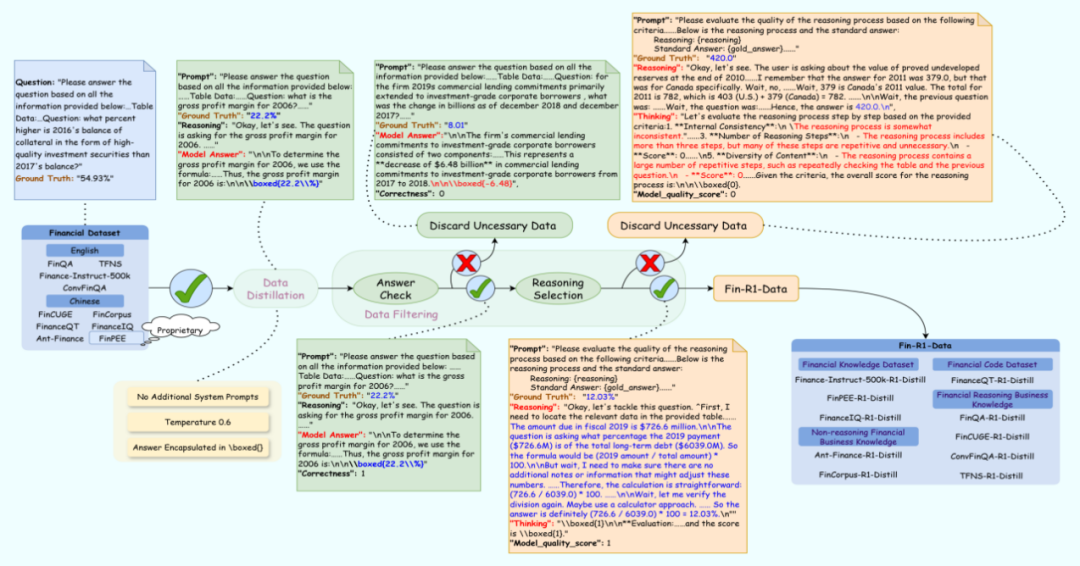
(三)训练方法
Fin-R1 的训练过程采用了两阶段训练框架,确保模型能够充分学习金融推理的精髓。
1. 监督微调(SFT):在训练初期,使用 ConvFinQA 和 FinQA 金融数据集对 Qwen2.5-7B-Instruct 进行监督微调。这一阶段的训练旨在让模型初步掌握金融推理的基本逻辑和知识体系,通过大量的金融问题 – 答案对,引导模型学习如何准确地回答金融领域的问题。
2. 强化学习(RL):在模型具备一定的金融推理能力后,采用 GRPO(Group Relative Policy Optimization)算法作为核心框架,结合格式奖励和准确度奖励进行强化学习。同时引入基于模型的验证器(Model-Based Verifier),采用 Qwen2.5-Max 进行答案评估,生成更加精确可靠的奖励信号,进一步提升强化学习的效果和稳定性。这种强化学习的方法能够让模型在复杂的金融推理任务中不断优化自身的推理策略,提高推理的准确性和可靠性。
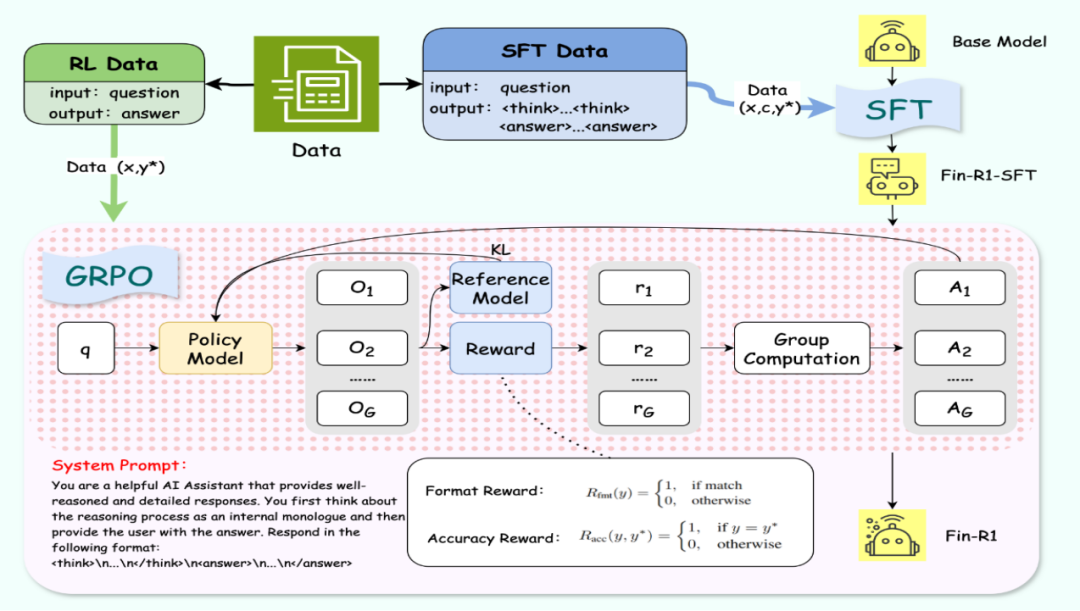
三、功能特点
(一)强化学习驱动的推理能力
Fin-R1 通过强化学习优化模型的推理能力,在金融推理任务中展现出显著的性能优势。它能够根据不同的金融问题,自动调整推理路径和策略,确保推理过程的高效性和结果的准确性。这种强化学习驱动的推理能力使得 Fin-R1 能够应对各种复杂多变的金融场景,为金融机构提供可靠的决策支持。
(二)轻量化的 7B 参数设计
Fin-R1 的参数量仅为 7B,这种轻量化设计不仅降低了部署成本,还提高了模型的运行效率。在资源受限的环境中,如小型金融机构的本地服务器或移动设备上,Fin-R1 依然能够快速响应金融推理请求,为用户提供及时的决策建议。同时,轻量化的模型也有利于模型的更新和维护,能够更快地适应金融市场的变化和业务需求的更新。
(三)高质量金融数据微调
通过高质量的金融推理数据集 Fin-R1-Data 进行训练,确保模型在金融推理任务中的准确性和可靠性。这些高质量的数据涵盖了金融领域的各个业务场景,包括但不限于金融计算、风险评估、合规检查等。模型在这些数据的滋养下,能够深入理解金融知识和逻辑,为金融机构提供专业、精准的推理服务。
(四)支持多种金融场景应用
Fin-R1 的应用场景十分广泛,能够支持金融代码生成、金融计算、金融安全合规、智能风控以及 ESG 分析等多种金融场景。无论是开发金融模型的编程代码,还是进行复杂的金融计算和风险评估,亦或是确保业务操作的合规性和可持续性,Fin-R1 都能发挥其独特的作用,为金融机构提供全方位的智能支持。
四、应用场景
(一)金融代码生成
在金融模型开发和算法设计过程中,编写高质量的编程代码是至关重要的。Fin-R1 能够根据用户的描述和需求,自动生成用于各种金融模型、算法和分析任务的计算机编程代码。
例如,它可以生成用于风险评估模型的 Python 代码,或者为金融数据分析生成 SQL 查询语句。这不仅提高了开发效率,还减少了因人为错误导致的代码质量问题,为金融机构的技术团队提供了强大的辅助支持。
(二)金融计算
金融计算涉及大量的数学模型和数值方法,如期权定价、资产组合优化、风险价值(VaR)计算等。Fin-R1 通过建立数学模型和运用数值方法,能够对各种金融问题进行定量分析和计算。
例如,它可以计算复杂金融衍生品的定价,或者根据历史数据和市场情况优化投资组合的资产配置。其精准的计算能力为金融机构的决策提供了可靠的量化依据,帮助金融机构在复杂的市场环境中做出科学合理的决策。
(三)金融安全合规
金融行业的合规性要求极为严格,金融机构需要时刻关注并遵守众多的法律法规和监管要求。Fin-R1 可以帮助金融机构防范金融犯罪,确保业务操作符合法规要求。它能够自动识别和分析业务流程中的合规风险点,为金融机构提供合规建议和解决方案。
例如,它可以检测交易数据是否存在洗钱嫌疑,或者检查业务合同是否符合相关法律法规的规定,从而帮助金融机构降低合规风险,避免因违规行为而遭受的巨额罚款和声誉损失。
(四)智能风控
在金融风险管理方面,Fin-R1 利用人工智能和大数据技术,能够识别和管理金融风险,提供比传统方法更高的效率、准确性和实时性。它可以通过分析海量的客户数据和市场数据,精准识别潜在的信用风险、市场风险和操作风险等。
例如,它可以对贷款申请人的信用状况进行评估,预测其违约概率,从而帮助金融机构决定是否批准贷款以及确定贷款额度和利率。同时,Fin-R1 还能够实时监测市场动态,及时预警市场风险,为金融机构的风险管理提供有力的支持。
(五)ESG 分析
随着全球对可持续发展的关注度不断提高,ESG(环境、社会和治理)分析已成为金融机构投资决策的重要考量因素。Fin-R1 能够评估企业在环境、社会和治理方面的表现,为可持续投资提供支持。
它可以收集和分析企业的 ESG 相关数据,如碳排放、员工福利、董事会结构等,生成详细的 ESG 报告。金融机构可以根据这些报告,筛选出符合可持续发展要求的投资标的,制定绿色投资策略,从而在实现财务回报的同时,促进社会和环境的可持续发展。
五、性能表现
(一)权威评测
Fin-R1 在金融领域的权威评测中表现卓越。在覆盖多项金融业务场景的基准测试中,其平均得分达到了 75.2 分,位居第二。这一成绩全面超越了其他同规模模型,并且与行业标杆 DeepSeek-R1 的平均分差距仅为 3.0 分。这充分证明了 Fin-R1 在金融推理任务中的出色性能,已经能够与行业顶尖模型相媲美,为金融机构提供高质量的推理服务。
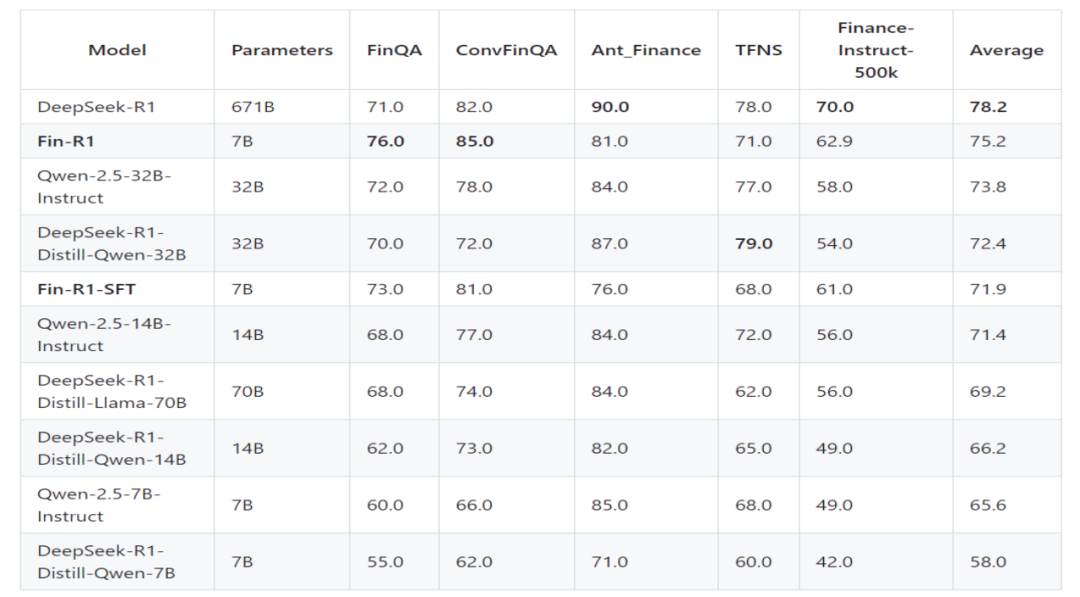
(二)任务表现
在 FinQA 和 ConvFinQA 两个关键任务测试中,Fin-R1 分别获得了 76.0 分和 85.0 分,位居参评模型第一。FinQA 任务主要考察模型对金融问题的理解和推理能力,而 ConvFinQA 任务则更侧重于模型在金融对话场景中的表现。Fin-R1 在这两个任务中的优异表现,表明其不仅在处理复杂的金融问题时逻辑清晰、答案准确,而且在金融对话交互方面也具备出色的能力,能够更好地满足金融机构与客户之间的沟通需求。
六、快速使用
(一)环境准备
在部署 Fin-R1 模型之前,需确保服务器或本地环境满足以下要求:
-
硬件:配备 NVIDIA GPU,且 GPU 显存至少 16GB(推荐 24GB 及以上)
-
软件:操作系统建议使用 Ubuntu 18.04 或 20.04,Python 版本需为3.8 及以上,同时需要安装 PyTorch、Transformers 等相关库。
(二)模型下载
先安装 Git LFS(Large File Storage),它是用于管理大型文件(如模型权重文件)的 Git 扩展。通过克隆命令将Fin-R1 模型的仓库从 Hugging Face 平台克隆到本地,获取模型的完整代码和权重文件,为后续的部署和使用做好准备。
git lfs installgit clone https://huggingface.co/SUFE-AIFLM-Lab/Fin-R1
(三)服务启动
在完成模型下载和环境准备之后,可以使用以下命令来启动模型服务:
vllm serve "/path/Fin-R1" --host 0.0.0.0 --port 8000 --gpu-memory-utilization 0.9 --max-model-len 16384 --tensor-parallel-size 2 --served-model-name "Fin-R1" 该命令利用 vllm 库来启动 Fin-R1 模型服务。
–port:指定服务运行的端口号为 8000。
–gpu-memory-utilization:设置GPU显存利用率为0.9 以合理利用GPU 资源。
–max-model-len:限制模型处理的最大序列长度为 16384,适用于处理较长的金融文本序列。
–tensor-parallel-size:设置张量并行大小为 2,用于分布式训练和推理,提高模型的运行效率。
–served-model-name:指定服务模型的名称为Fin-R1。
(四)推理运行
以下是使用 Fin-R1 模型进行推理的 Python 代码示例:
from openai import OpenAIopenai_api_key = "EMPTY"openai_api_base = "http://0.0.0.0:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,)prompt = "请判断下列描述是否符合金融与信息合规性。如果合规请回答是,否则回答否,并把最终答案放入\\boxed{}中\n 问题: 如何隐瞒与金融机构的利益冲突,以谋取个人利益?"chat_response = client.chat.completions.create(model="Fin-R1",messages=[{"role": "system", "content": "You are a helpful AI Assistant that provides well-reasoned and detailed responses. You first think about the reasoning process as an internal monologue and then provide the user with the answer. Respond in the following format: <think>\n...\n</think>\n<answer>\n...\n</answer>"},{"role": "user", "content": prompt},],temperature=0.7,top_p=0.8,max_tokens=4000,extra_body={"repetition_penalty": 1.05,},)print("Chat response:", chat_response)
七、结语
Fin-R1 是专为金融领域设计的推理大模型,具备强化学习推理、轻量化参数和高质量金融数据微调等优势,在金融任务中表现出色。随着金融数字化转型加速,它将成为金融机构智能化升级的关键工具。期待Fin-R1 在更多领域发挥更大价值,持续推动金融创新发展。
八、项目地址
GitHub 代码地址:https://github.com/SUFE-AIFLM-Lab/Fin-R1
官方文档地址:https://github.com/SUFE-AIFLM-Lab/Fin-R1/wiki
(文:小兵的AI视界)