


新智元报道
新智元报道
【新智元导读】LLM正推动推荐系统革新,以用户表征为「软提示」的范式开辟了高效推荐新路径。在此趋势下,淘天团队发布了首个基于用户表征的个性化问答基准UQABench,系统评估了用户表征的提示效能。
在「千人千面」的个性化服务浪潮中,大语言模型(LLM)凭借强大的语义理解与生成能力,正在重塑推荐系统与个性化问答的产业格局。
研究背景:当推荐系统遇见大模型,如何突破效率与效果的双重挑战?
传统方案通过将用户点击历史转化为文本提示注入LLM上下文,虽能提升相关性,却面临两大硬伤:
-
效率瓶颈:单用户行为序列动辄数万token,远超LLM上下文窗口限制,推理延迟与成本飙升;
-
噪声干扰:冗余点击、误操作等噪声易误导模型,削弱个性化效果。
破局之道:将用户行为序列压缩为高密度的表征向量(user embeddings),以「软提示」形式驱动LLM生成精准回复。
然而,这一路径的核心争议在于——用户表征能否真正承载关键信息并有效引导LLM?UQABench应运而生,成为首个系统化评估用户表征质量的权威基准。
核心创新:三阶评估体系 + 三维任务设计,直击产业痛点
1. 标准化评估流程:从预训练到场景化对齐
-
预训练:基于海量行为数据训练用户编码器(如SASRec、HSTU),捕获兴趣模式;
-
对齐微调:通过轻量Adapter(线性映射/Q-Former)桥接推荐空间与LLM语义空间,破解「表征-语义」鸿沟;
-
场景化评估:设计多粒度任务验证用户表征的实用价值 。
2. 三维任务体系:覆盖传统需求与LLM新愿景
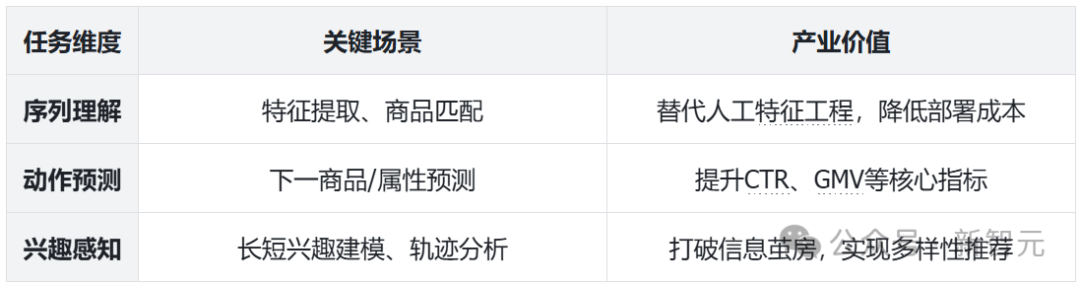
重磅发现:用户表征的效能密码与工业启示
-
模型架构:Transformer类模型(如HSTU)显著优于RNN类模型(如GRU4Rec,Mamba),序列建模能力更适配LLM需求;
-
信息融合:商品侧ID特征(类目/品牌)与文本描述(标题)联合编码,可提升LLM对用户兴趣的解读精度;
-
效率革命:最优表征模型效果逼近纯文本方案,推理token数减少90%+,成本效益比突破性提升;
-
扩展定律:编码器参数量从3M增至1.2B,LLM个性化性能持续提升,为「离线训练强化+在线高效推理」提供理论支撑 。

论文链接:https://arxiv.org/abs/2502.19178
代码库仓库:https://github.com/OpenStellarTeam/UQABench
数据集下载:https://www.kaggle.com/datasets/liulangmingliu/uqabench
接下来,我们来详细介绍论文的内容。
论文详解
研究背景
大语言模型(LLM)近年来在推荐系统和个性化问答中被广泛应用。为了追求更加个性化的用户体验,实现「千人千面」,将用户的历史点击序列融入LLM的输入中变得至关重要。最常见结合的方式是,将用户点击历史,利用特定的规则转化为自然语言文本,作为LLM的用户背景提示(context)。
然而,从工业应用的角度来看,噪声以及超长序列带来的性能和开销问题,对直接将序列文本用作用户context提出了挑战。一种自然的解决方案是,将用户交互历史压缩和提炼为表征向量(或向量组),作为软提示(soft prompt)辅助LLM生成个性化的回复。
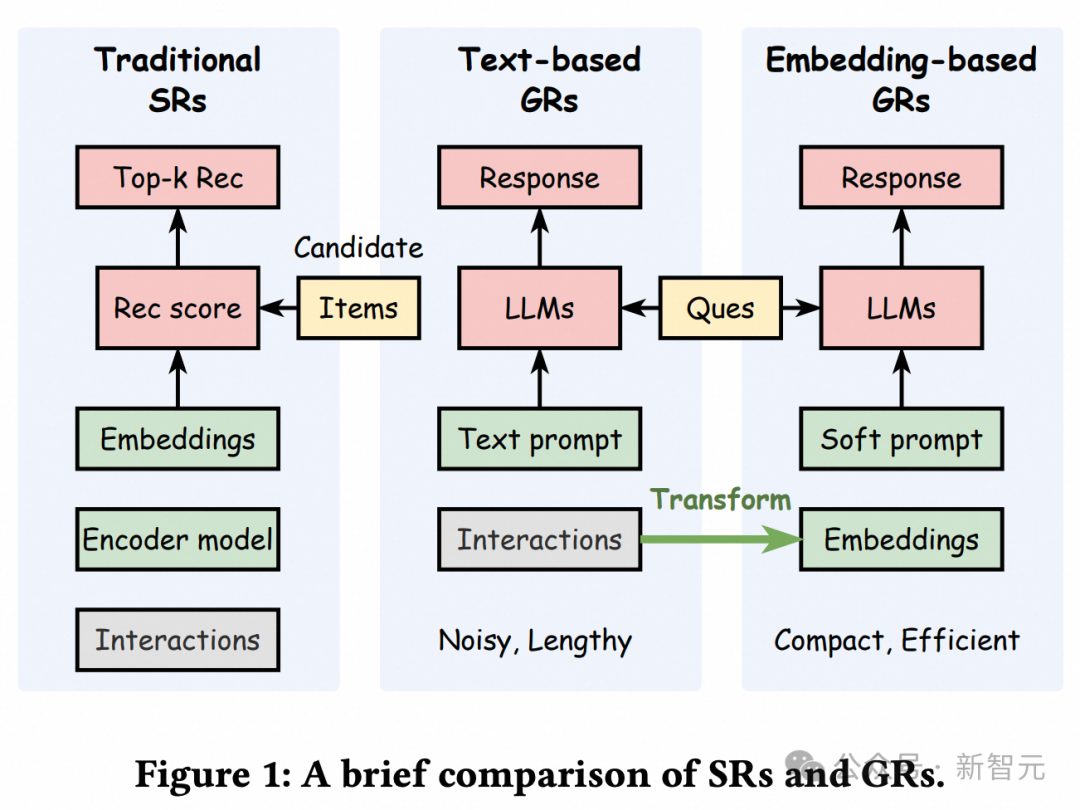
虽然这种方法提高了效率,但一个关键问题随之而来:用户嵌入能否充分捕获用户交互历史中有价值的信息并提示LLM?为了解决这一问题,研究人员提出了UQABench,一个专为评估用户嵌入在提示LLM进行个性化时的有效性而设计的基准。研究人员建立了一个公平和标准化的评估流程,涵盖了预训练、微调和评估阶段。
为了全面评估用户嵌入,研究人员设计了三种维度的任务:序列理解、动作预测和兴趣感知。这些评估任务覆盖了传统推荐任务中提高召回/排序指标等行业需求,以及基于LLM方法的愿景,如准确理解用户兴趣和提升用户体验。
研究人员对用于建模用户的多种经典方法(如SASRec)和SOTA方法(如HSTU、Mamba4Rec)进行了广泛实验和评估。此外,研究人员揭示了利用用户嵌入来提示LLM的scaling law。
相关工作
用户历史行为序列中提取的user embeddings作为个性化场景的核心特征载体,其应用价值与演化前景已得到广泛验证。
当前研究趋势表明,深度融合LLM的语义理解能力来增强用户表征的语义泛化性,正成为提升embedding质量的重要技术路径。
研究人员在淘宝搜索广告场景中创新性地构建了基于大规模用户模型(LUM)的三阶段训练范式,实现了用户意图建模的显著提升。该方法在线上实验中获得CTR和RPM的显著增益。
具体方法论与实验细节可参考原论文:「Unlocking Scaling Law in Industrial Recommendation Systems with a Three-step Paradigm based Large User Model」。
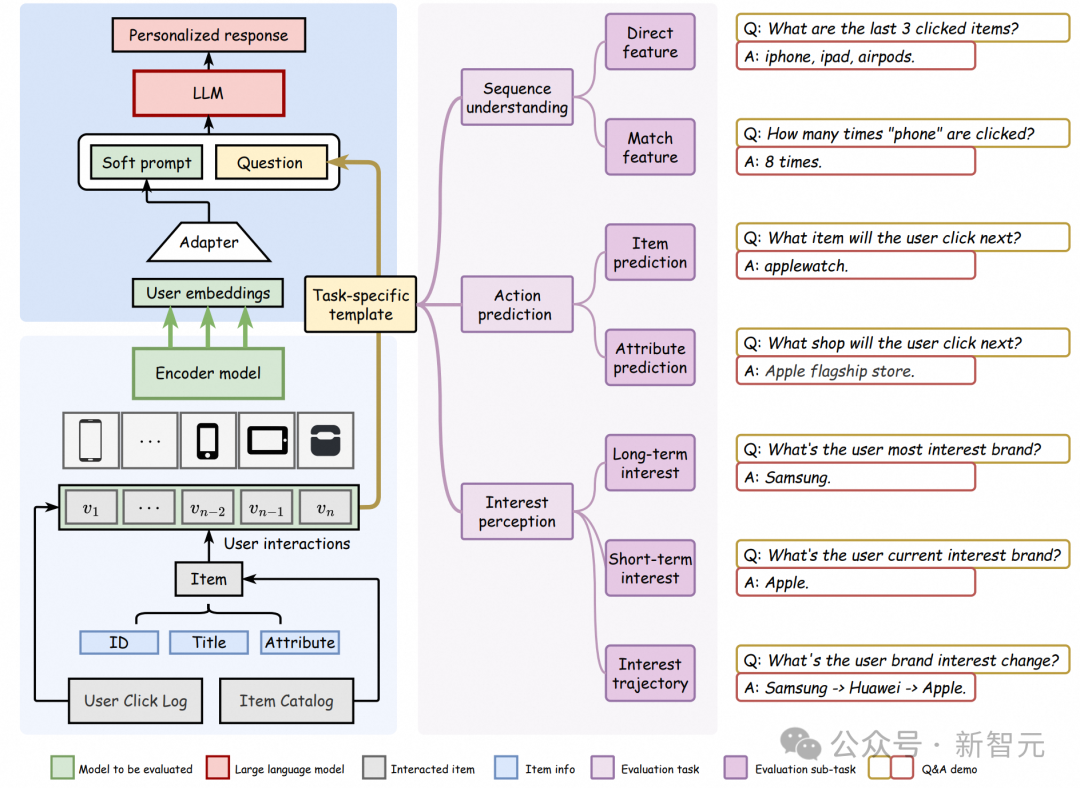
任务类型
UQABench由淘宝电商系统中18万个用户对100万个商品的点击的行为数据构建而来,要求LLM基于给定用户的表征向量,回答一个自然文本形式问题。问题类型有三大类共七个子任务,用以评估推荐系统中最关键的几类问题。
1. 序列理解:
分为直接特征理解和match类特征理解。前者要求模型回答用户序列中一些显而易见的特征,例如「用户最近点击的三个商品的品牌分别是什么」,而后者要求模型回答一些交叉类的特征,例如「用户共点击过多少次手机类商品」。序列理解任务涉及使用LLM从用户嵌入中提取和恢复历史用户信息。目标是评估用户嵌入在多大程度上可以作为桥梁,将用户交互序列中的必要信息传递给LLM。这个任务关系到在LLM时代用户嵌入是否可以替代大量的用户侧特征工程。
2. 动作预测:
预测用户下一个要点击的商品和要点击商品的属性,例如「基于用户的浏览历史,该用户下一个要点击的商品的标题是什么」。该任务的目标是评估用户嵌入如何能够帮助LLM完成诸如Top-k推荐和点击率(CTR)预测等传统工业推荐系统任务,这与电商平台的收入密切相关。
3. 兴趣感知:
预测用户的短期兴趣、长期兴趣以及兴趣的变化轨迹,例如「用户最喜欢的品牌是什么」或是「用户近期最喜欢什么类目的商品」。这反映了基于LLM做推荐的方法的愿景:准确理解用户兴趣和提升用户体验。基于LLM的推荐系统相比传统推荐系统的一个革命性进步是在引入显著的多样性方面。受限于训练范式和协同过滤框架,传统推荐系统往往集中在热门项目和频繁互动的用户上。研究人员希望用户嵌入能够帮助基于LLM的方法召回多样的用户兴趣项目,从而提高个性化并增强用户体验。
数据构造
首先,随机圈定18万个近期有较活跃行为的淘宝用户,并获取他们的商品点击行为序列。出于对合规性的需要,需要对各种ID类信息进行了脱敏、并移除了用户行为序列中的敏感商品。除此之外,研究人员还在不损伤效果的前提下,对用户行为序列做了一定程度的改写,以保护用户的隐私。
针对每一类问题,研究人员都为其设计了提问的模版。给定一个任务特定的模板和用户数据,便可以基于用户交互自动生成相应的问题和答案。例如,为直接特征理解任务设计的模板可能是「用户最近点击的 k个商品的类目分别是什么」,只需要将用户行为序列的后k个item的类目作为答案即可。
由于让LLM生成高度专业化问题的完整答案是不切实际的,所以UQABench以选择题的形式评测。此外,研究人员还采用了一些过滤规则,以避免简单或过于繁琐的问题。
评测流程
研究人员提供了三份数据,待评测的模型需要在前两份数据上进行训练,并在第三份数据上做预测,并执行评测。整个评测流程分为三个阶段:
1. 预训练:
将待评测的用户建模模型(例如SASRec或HSTU),在研究人员提供的用户行为序列数据上进行预训练,训练任务可以自由设置,默认使用 next item prediction。
2. 对齐:
预训练后的encoder可以产出捕捉用户兴趣的表征,但是还需要引入一个adapter,用来桥接协同过滤空间和LLM语义空间。常见的adapter有简单的线性映射(维度对齐)加mean-pooling(长度压缩),或是稍微复杂一点的q-former。Adapter是随机初始化、未经训练的。所以需要在研究人员提供的对齐数据上进一步finetune。
3. 评估:
用对齐后的用户表征模型,生产对应的用户表征,并回答测试集中的7000个问题,然后使用打分脚本获得评价指标。
实验发现
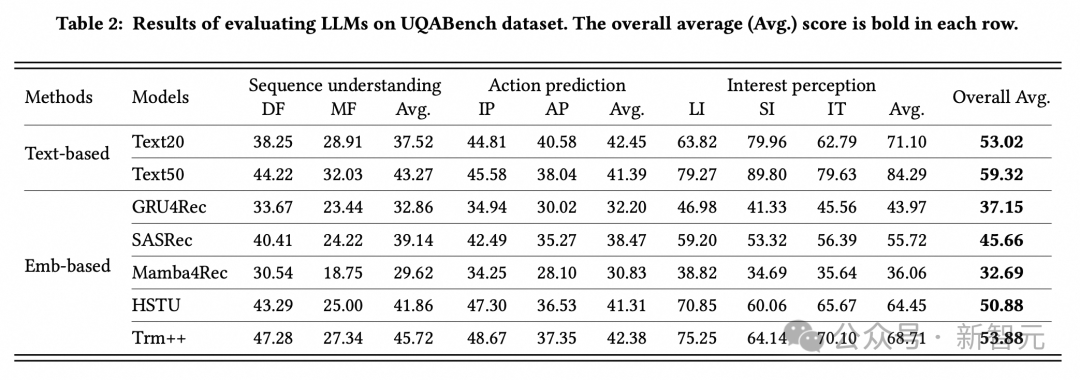
1. 总体实验:
研究人员评价了几个广泛流行的用户建模模型,在整体对比实验中,以HSTU 为代表的Transformer类模型在用户超长周期兴趣的表征的能力上表现出强劲的效果,超越了RNN类模型(GRU4Rec和Mamba4Rec)。
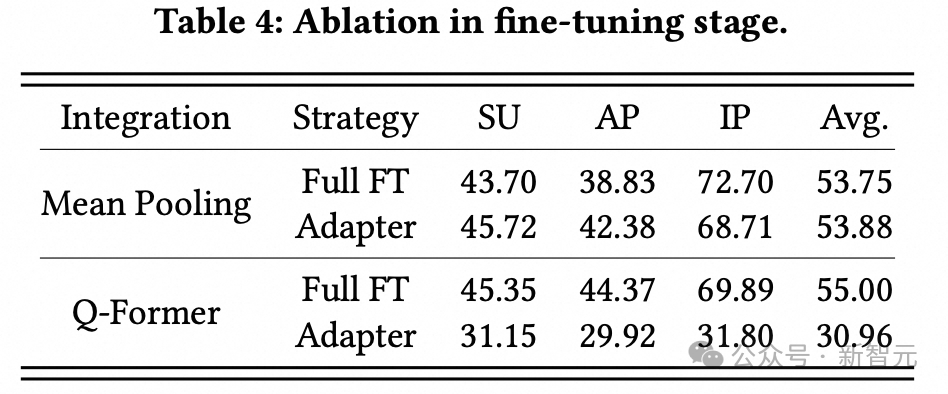
2. 消融实验:
a. 在对用户序列进行编码时,商品信息中的side info(例如类目ID、店铺ID和品牌ID)等和文本信息(例如标题),都会有助于LLM对用户表征的理解,在建模时需要将它们考虑在内。

b. 即使使用最简单的线性映射与平均池化 (linear + mean pooling)作为adapter,将用户的表征压缩为一个单一向量(输入给LLM时仅仅占用一个token的位置),也能取得不错的效果,这说明单一向量的表达能力也很强。Q-former的训练稳定性比较差,对参数比较敏感,使用未经细调的超参数效果不佳。
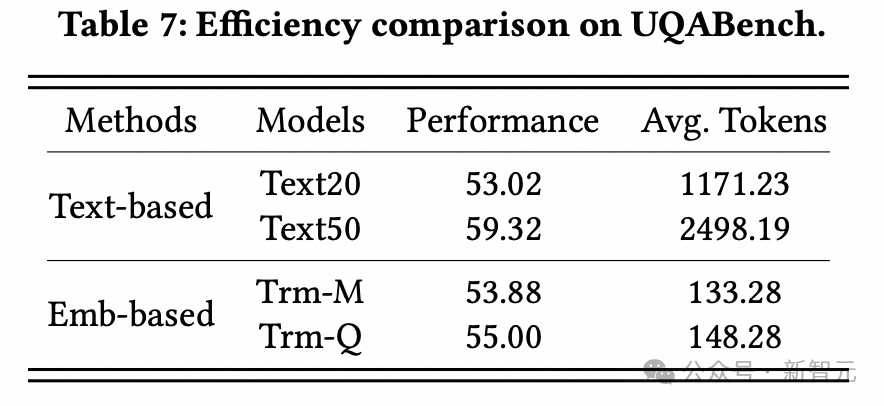
3. 效率实验:
研究人员也比较了基于纯文本context的模型的效果(TextN表示用户行为序列截断到近期的N个item),可以看出,最优秀的基于embedding的模型,效果可以接近文本模型,但其输入给LLM的token数只有前者的5%左右,推理开销要小得多,性价比很高。
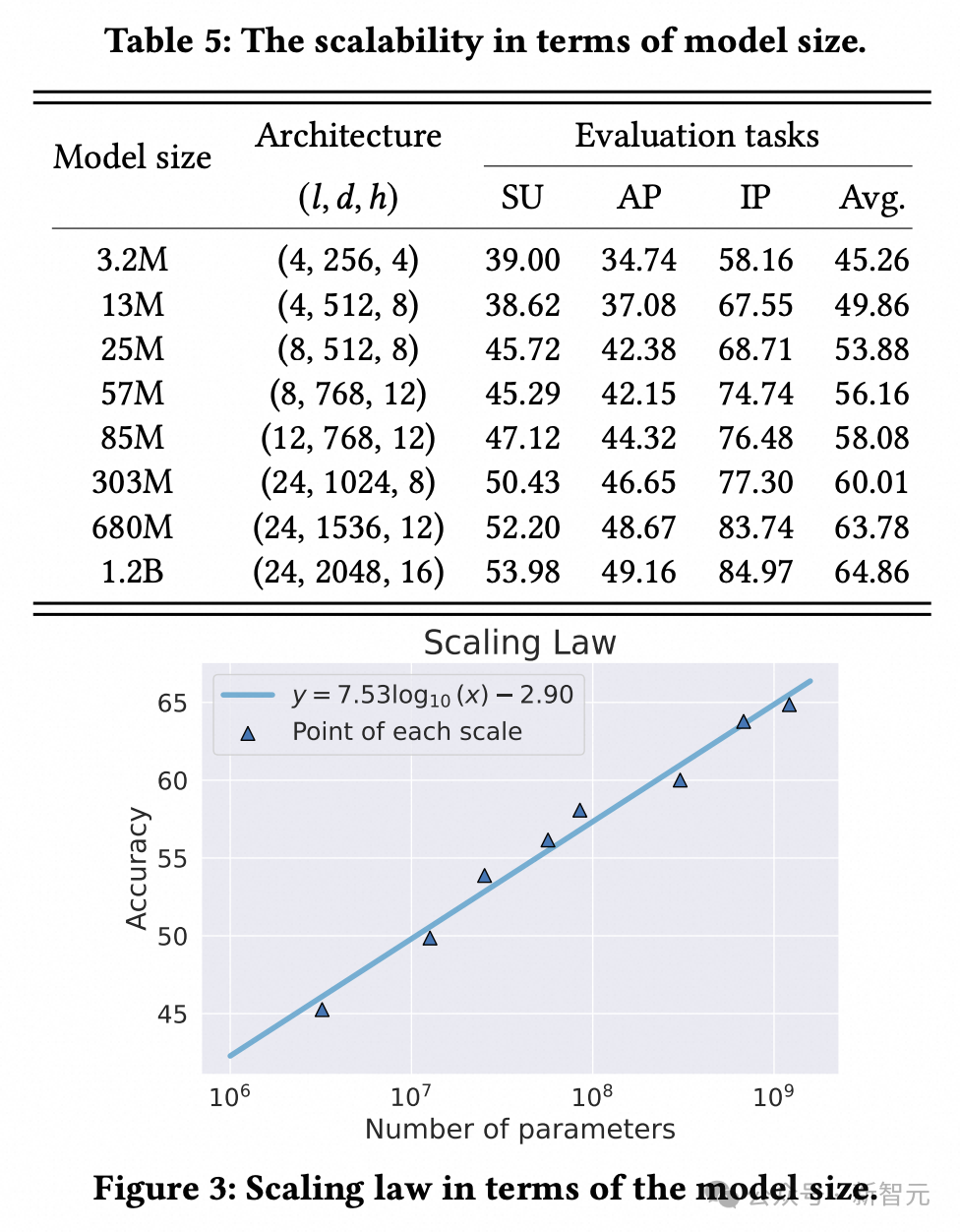
4. 放缩实验:
研究人员将用户编码器的参数量,从3M逐渐扩大到1.2B,并逐个进行完整评测流程(预训练-微调-评测),可以从评测结果看出性能与模型大小之间呈现的明显扩展规律。这一结果对工业场景应用具有重要意义:可以通过在离线环境强化编码器模型(即扩大模型规模),持续提升LLM在在线环境中的个性化性能,而不会影响推理效率。
最后,欢迎广大研究者使用评测集进行实验和研究。淘天集团算法技术-未来生活实验室团队将持续为中文社区的发展贡献力量。
作者介绍
核心作者包括刘朗鸣,刘石磊,袁愈锦,苏文博。作者团队来自淘天集团的算法技术-未来生活实验室团队和阿里妈妈-搜索广告团队。
为了建设面向未来的生活和消费方式,进一步提升用户体验和商家经营效果,淘天集团集中算力、数据和顶尖的技术人才,成立未来生活实验室。
实验室聚焦大模型、多模态等AI技术方向,致力于打造大模型相关基础算法、模型能力和各类AI Native应用,引领AI在生活消费领域的技术创新。
(文:新智元)