



语音交互又被玩出新花样?!
智东西4月2日报道,本周一,百度发布业界首个基于全新互相关注意力(Cross-Attention)的端到端语音语言大模型,已首发上线文小言,可免费体验。

用几个关键词概括新升级的文小言就是:语音交互超逼真、超低时延、超低成本。
百度语音首席架构师贾磊透露,该模型可以部署到L20卡上,在满足语音交互延迟要求的情况下,双L20卡的并发可以做到几百以上。目前,语音语言大模型的训练流程便捷,基本上基于文心大模型几百片卡优化一周就可以实现,且本身的优化工作也并不复杂。
相比于大模型在语音交互场景的应用,这一语音语言大模型的独特之处是什么?又是如何做到最高降低90%的调用成本?其背后的创新点该如何解读?智东西与百度语音首席架构师贾磊进行了深入交流,试图找到这些问题的答案。
大模型在语音交互场景的发展,正朝着更自然、低延迟、高拟真的语音交互体验演进。而这一更为拟人化的交互体验,我们在新升级的文小言上窥到了雏形,搭载了端到端语音语言大模型的文小言,已经化身情感陪伴、全能助手。
文小言这一情感饱满的交互形式,也使得其在知识问答等助手场景下,向着陪伴场景下的应用外延。当用户提到“我的心情有点不好”,文小言的语音带有担心等,并引导用户说出自己心情不好的原因,进一步进行开导。
不同于语言模型,语音语言大模型的核心差异点就是可以产生情感。
贾磊谈道,文本大模型只产生文字,而语音语言大模型可以有情感,其关键就是语音语言大模型架构图中的两个特殊环节,TN韵律和人设、风格情感控制,这是为语音合成而准备,可以让大模型在生成答案的同时拥有适配内容的情感,这也是百度此次端到端语音语音大模型的关键创新点所在。

具体来看,其关键创新点有4个。
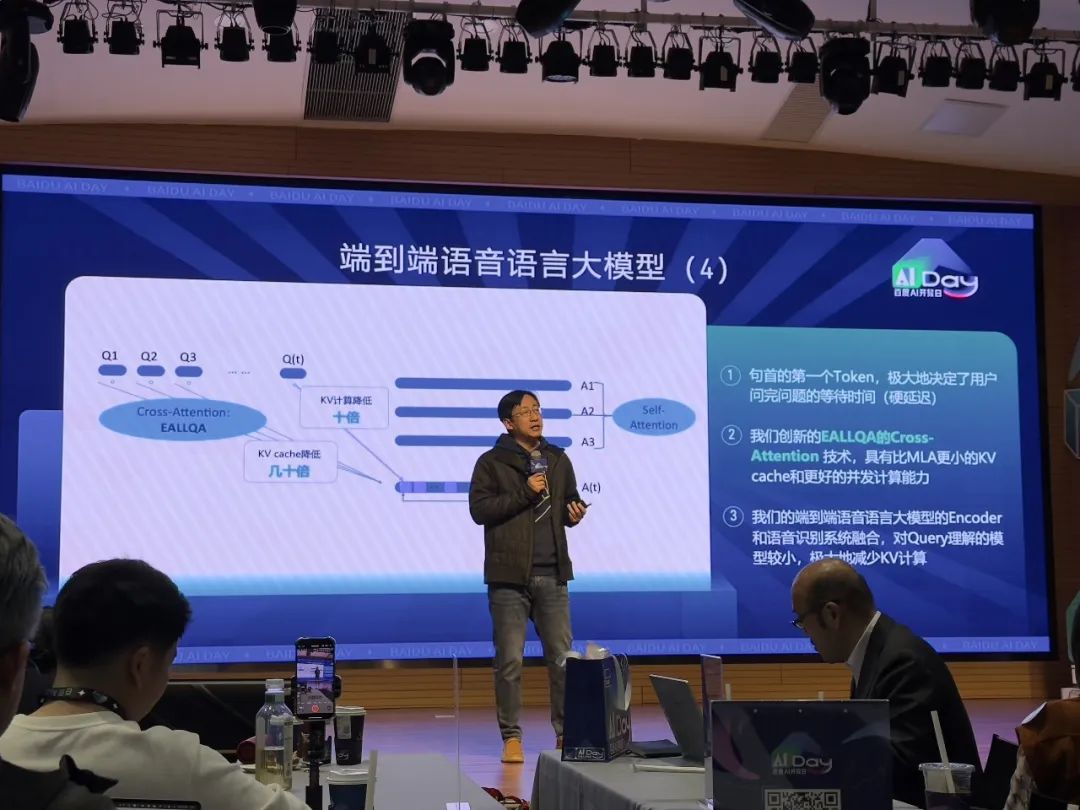
首先,这是百度发布的业界首个基于Cross-Attention跨模态的语音语言大模型;其二是该模型将Encoder和语音识别结合,使得KV计算节省到1/10;第三是Encoder和语音合成结合,输出内容可进行情感控制;最后是高效的全查询注意力EALLQA,使得KV cache降低到几十分之一。
在此基础上,该模型实现了识别文本一体化、文本合成一体化,这些相互耦合的技术在系统性端到端打通之上,使得模型在快速问答、快速理解的基础上,能实现自然、逼真、情感丰富的交互体验。
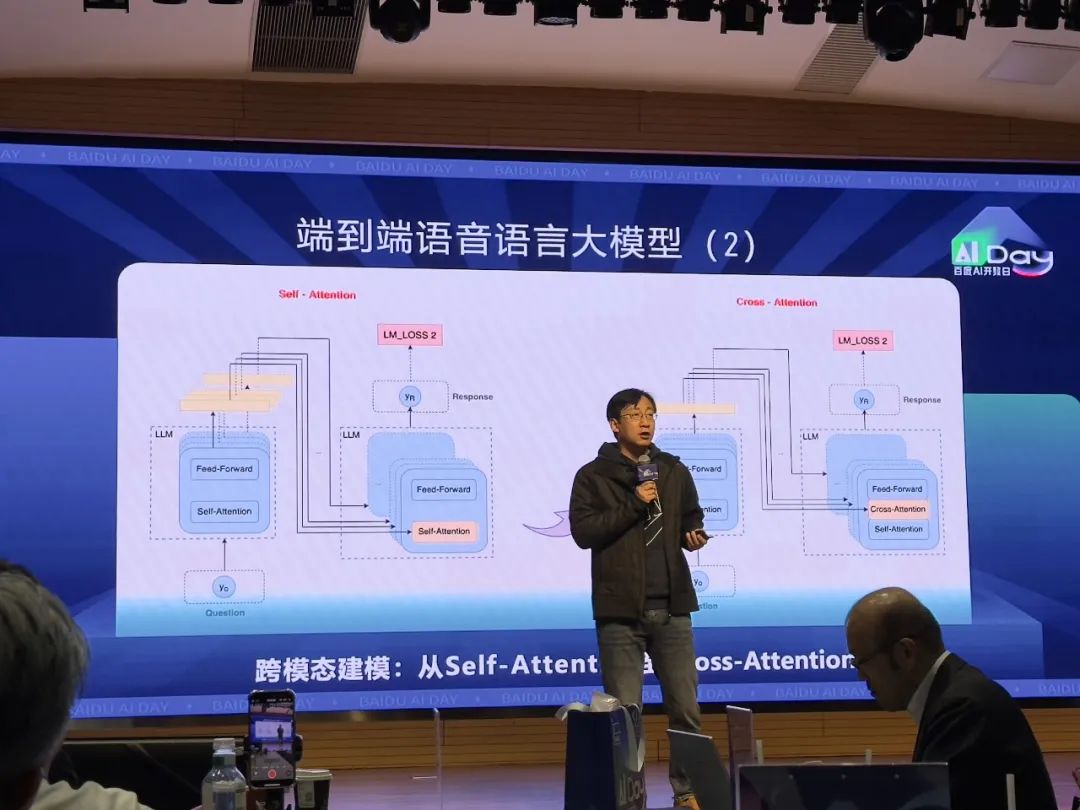
贾磊解释说,声学模型也是语音模型,只是通常大语言模型都是文字连接。因此在整合语音识别和大语言模型的过程中,研究人员将大语言模型中的Encoder和语音识别的过程融合共享,达到降低语音交互硬延迟的目的,其创新性引入跨模态建模,从Self-Attention切换到Cross-Attention,完成了语音识别和大语言模型的融合。
百度提出用Cross-Attention来解决语音、语言跨模态的难题。这一过程中,由于现存Attention技术在Cross-Attention的语音语言建模中存在速度方面的局限性,百度研发了适合Cross-Attention的EALLQA技术,采用隐式RNN两级位置编码,训练时在128空间上的MHA,推理在模型各层共享的512空间上的MQA,以达到充分利用有限训练资源,降低推理成本的目的。
模型基础训练中,百度基于Self-Attention的成熟的文心语言的预训练模型,采用自蒸馏方式进行post-train来训练Cross-Attention端到端语音语言大模型。
事实上,在语音模型中,KV cache和KV计算的压力远大于文本模型。贾磊解释说,语音识别相对于文本大模型的本质差异就是,句首第一个token决定了语音识别的延迟。对于文本大模型,其可以在用户输入一段文字后等待2~3秒钟给出答案,而语音语言大模型中,用户对于回复延迟的可容忍度更低,他们希望在0.5~1秒内听到答案。
在此基础上,端到端语音语言大模型实现了低成本训练、低成本高速推理。除此以外,语音语言大模型还需要快速响应、有情感的回应,这就是其另一项关键技术发力的场景——流式逐字的LLM驱动的多情感语音合成。贾磊谈道,多轮有情感地持续沟通才能让人有欲望继续交流。

基于流式逐字的方式,其语音合成是看到一个字蹦一个字,大模型可以帮助语音合成输出其需要的文本归一化输出、韵律停顿输出、情感输出,使得语音合成的过程像人说话时一样流动起来,其根据文本输出自适配的情感覆盖可达17种。
此外,语音识别中还有一大痛点是,其无法判断用户说话的起点和终点,而大模型加持可以使其基于语义分析用户说的话是否已经结束,语义不完整需继续等待。
贾磊进一步解释道,语音场景被激活需要极地交互成本、极快交付速度、聪明富有情感的人性化的问答。百度将语音识别和大模型一体化,解决了预存预取、犹豫、内容理解和快速问答的问题,将文本合成一体化与大模型融合,输出语音和中所需的韵律情感,解决了合成中的上下文理解和情感控制问题。这就使得语音场景的应用潜力大幅提升。
大模型不断优化在语音的稳健性、自然度和说话人相似度方面显著提升,但此前的技术路径仍有许多痛点,这也是百度聚焦于端到端语音语言大模型的原因。
相比于人和人之间的交流,大语言模型响应速度慢,用户需要等待一段时间才能得到回复。此外,语音交流往往伴随着多轮对话交互,而模型完成口语化多轮交互的难度极大,且相比于文本,用户使用语音交互的场景更多,其交互量激增会导致大模型应用成本上升,大规模应用普及的难度也会随之增高。
而在传统语音交互路线上,又会受限于上下文记忆、噪音场合、犹豫发问和打断之间的准确响应。

因此这成为语音交互领域的一个核心矛盾点,语音交互的便捷性决定了其有大规模应用的潜力,而这些痛点又正在阻碍其普及。贾磊认为,语音和文本两个跨模态之间相互关联的化学反应,就是未来大模型在特定领域找到突破口的关键。
语音语言模型的出现是质变,其创新合成技术使得模型不需要看到一句话的整个文本,而是看到一个字的文本就可以合成一个字,在此基础上,百度挖掘到了独特的应用场景。他举了一个例子,如询问天气时,用户获得了天气的温度区间就可以快速打断问下一个问题,其好处就是大幅降低了模型的使用成本,而文本模型想要实现如此高效应用就需要强大的硬件,但语音语言模型可以使用低成本的硬件就能实现高效并发。
与此同时,从整个语音交互领域来看,大模型语音识别部分的准确度已经大幅提升,贾磊认为更多在于速度、成本、回答准确度的一种比拼,当下成本降低,就是大规模使用跨模态语音交互的关键。
贾磊说:“成本降低是技术进步的必然方式。” 百度语音语言大模型的极低成本也就意味着大规模工业化的可能,AI落地应用是2025大模型产业发展的核心,而该模型就是解决语音问题的关键。
百度在语音识别领域的积累由来已久。
2018年,百度语音发布的Deep Peak 2模型突破了沿用十几年的传统模型,大幅提升各场景下识别准确率。2019年初,百度语音技术团队公布在线语音领域全球首创的流式多级的截断注意力模型SMLTA, 相对准确率提升15%。2021年,百度发布基于历史信息抽象的流式截断conformer建模技术——SMLTA2,解决了Transformer模型应用于在线语音识别任务时面临的问题。
这些技术创新已经应用于汽车、消费电子、手机等诸多领域。此次,为了推动语音语言模型的规模化应用,目前,百度已经将其上线文小言并免费开放,并且计划4月上线到开放平台,后续将接入呼叫中心、音箱等业务线上。
贾磊提到:“科学可能有国界,但没有公司边界。”后续,百度将端到端语音语言大模型开放出来,就是想推动大语言模型在语音领域的应用,有利于整个行业和生态的发展。
便捷高效、自然友好、广泛应用于多场景的语音交互在数字化时代地位至关重要,但从目前的实际效果来看,语音交互在识别的准确度等方面已经有了很大提升,现在业界的竞争焦点集中于其识别的速度、成本以及回答的准确度。
(文:智东西)