


新智元报道
新智元报道
【新智元导读】4D LangSplat通过结合多模态大语言模型和动态三维高斯泼溅技术,成功构建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。该方法利用多模态大模型生成物体级的语言描述,并通过状态变化网络实现语义特征的平滑建模,显著提升了动态语义场的建模能力。
尽管现有方法在静态语义场重建方面已取得显著成果,但如何建模4D语言场(4D language fields)以实现动态场景中时间敏感且开放式的语言查询,仍面临诸多挑战,动态世界的语义建模对于推动许多实际应用的落地至关重要。
近日,来自清华大学、哈佛大学等机构的研究团队提出了一种创新方法4D LangSplat,基于动态三维高斯泼溅技术,成功重建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。这一突破为相关领域的研究与应用提供了新的可能性, 该工作目前已经被CVPR2025接收。

Data:https://drive.google.com/drive/folders/1C-ciHn38vVd47TMkx2-93EUpI0z4ZdZW?usp=sharing
将现有静态语义场重建方法直接迁移到动态场景中,一种直观的思路是沿用CLIP提取静态的、物体级语义特征,并借鉴4D-GS等工作的思路,通过训练变形高斯场来建模随时间变化的语义。
然而,这种简单的迁移存在两个关键问题:首先,CLIP最初是为图-文对齐任务设计的,其在动态语义场中的感知和理解能力存在局限性;其次,基于输入时间信息预测特征变化量的方法缺乏对特征变化的有效约束,导致动态语义场建模的学习成本显著增加。
针对上述问题,4D LangSplat框架核心创新在于:利用视频分割模型和多模态大模型生成物体级的语言描述,并通过大语言模型提取高质量的句子特征(sentence feature),以替代传统静态语义场重建方法(如LERF、LangSplat)中直接使用CLIP提取的语义特征。在动态语义特征建模方面,4D LangSplat引入了状态变化网络(Status Deformable Network),通过先验压缩语义特征的学习空间,实现了更加稳定和准确的语义特征建模,同时确保了特征随时间的平滑变化。
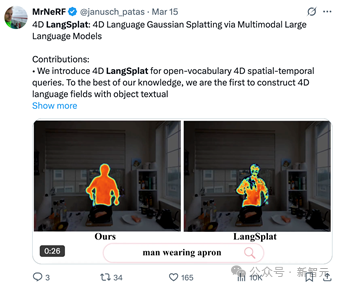
4D LangSplat的提出显著拓展了语义高斯场建模的应用场景,为动态语义场的实际落地提供了一种极具前景的解决方案。目前,该工作已在X(Twitter)平台上引发广泛关注,并得到AK、MrNeRF等大V转载,论文的代码和数据已全面开源。
 |
 |
方法论
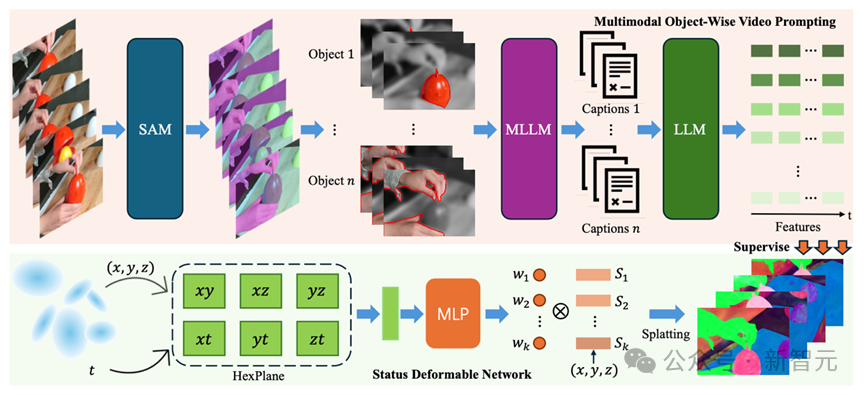
多模态对象级视频提示技术(流程图中上半部分的红色区域)
研究人员结合了SAM(Segment Anything Model)和DEVA tracking技术,对物体进行分割,并在时间维度上保持物体身份的一致性。
为了使多模态大模型能够更专注于已有物体的描述,首先为目标物体生成视觉提示。具体而言,视觉提示包括轮廓线(Contour)、背景虚化(Blur)和单色调整(Gray)。这一过程可以形式化地定义为:
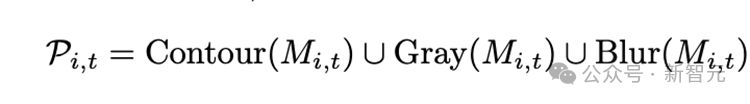
在加入视觉提示后,首先利用多模态大模型(Qwen-Instrution-7B)生成视频级的语言描述,随后逐帧将图片和视频描述再次输入到大模型中,提示其生成特定时间步骤下的物体状态变化的自然语言描述。生成视频-物体级语言描述和图片-物体级语言描述的过程可以形式化地定义为:
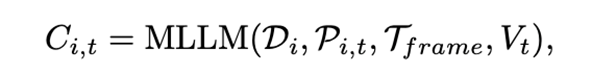
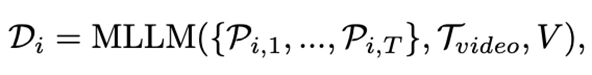
对于每一条生成的图片-物体级描述,使用在sentence-embedding任务上经过微调的LLM模型(e5-mistral-7b)将其转化为语义特征,并通过分割掩码生成最终的语义特征图。
此外,参考LangSplat的做法,研究人员训练了一个自动编码器,将高维特征压缩到低维空间,从而降低高斯场训练的复杂度和计算成本。
状态变化场(流程图中下半部分的绿区域)
通过对语义特征的观察,可以发现现实中的大部分变形和运动都可以分解为一系列状态及其之间的过渡。
例如,人的运动可以分解为站立、行走、跑步等状态的组合。在特定时间点,物体要么处于某种状态,要么处于从一个状态到另一个状态的过渡中。
基于这一观察,研究人员提出了状态变化网络(Status Deformable Network),将特定时间步下的变化状态分解为若干状态的线性组合,网络以Hexplane提取的时空特征作为输入,专注于预测指定时间步下的线性组合系数。数学上,其建模方式如下:
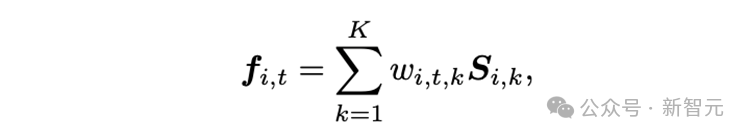
其中,w代表模型预测的系数,S代表状态特征。在训练过程中,状态特征和预测系数的状态变化网络联合优化,以确保对变化语义特征的准确和平滑建模。
4D开放词汇查询
研究人员将4D开放词汇查询任务定义为两个子任务:时间无关的查询和时间敏感的查询。时间无关的查询主要考验语义场的静态语义建模能力,目标是根据指定的查询词,给出物体在每一帧的查询结果掩码,类似于物体追踪检测任务。
而时间敏感查询则更注重动态语义建模能力,不仅需要给出查询物体的掩码,还需要精确到具体的时间步(例如动作发生的帧范围)。
为了完成这两个子任务,研究人员同时渲染了时间无关的语义场和时间敏感的语义场,前者基于CLIP提取语义特征,且不对语义特征的变化进行建模;后者则采用该方法提取时间敏感语义,并利用状态变化网络对语义特征进行建模。
在进行时间敏感查询时,首先通过时间无关场生成对应物体的查询掩码,然后计算掩码内时间敏感场的平均相关系数,并给出预测帧的结果。
通过结合这两个场,该方法能够同时胜任时间敏感查询和时间无关查询任务。
实验
实验设置
在评估指标方面,针对不同的查询任务设计了相应的衡量标准:
-
时间无关查询:使用平均准确率(mACC)和平均交并比(mIoU)作为查询结果的评估指标。
-
时间敏感查询:使用帧级别的预测准确率(ACC)和像素级别的平均交并比(vIoU)作为评估指标
结果:该方法在时间敏感和时间无关查询两个子任务上都显著优于最先进的方法。在时间敏感查询上,与基于CLIP特征的方法相比,该方法在帧级别准确率(ACC)和像素级别平均交并比(vIoU)上分别提升了29.03%和27.54%。
时间无关查询方面,在HyperNeRF和Neu3D两个场景中,该方法在平均交并比(mIoU)上分别比基线方法提升了7.56%和23.62%
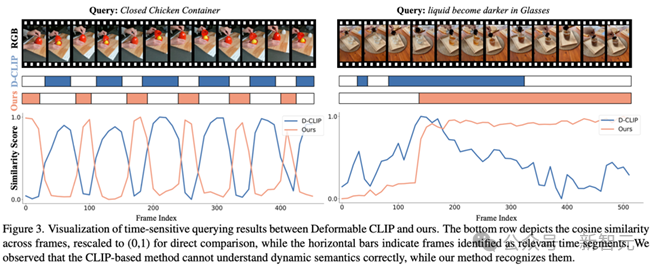
消融实验
为了验证该方法中各个组件的有效性,研究人员在论文中进行了详细的消融实验。实验结果表明,每个组件都对最终性能的提升起到了重要作用。
贡献
-
使用MLLM生成的对象文本描述构建4D语言特征。 -
为了对4D场景中对象的状态间平滑过渡进行建模,进一步提出了一个状态可变形网络来捕捉连续的时间变化。 -
实验结果表明,该方法在时间无关和时间敏感的开放词汇查询中都达到了最先进的性能。 -
通过人工标注,研究人员构建了一个用于4D开放词汇查询的数据集,为未来相关方向的研究提供了定量化的指标。
(文:新智元)