

随着人工智能(AI)向通用智能(AGI)迈进,单一模态的链式思维(Chain-of-Thought,CoT)已难以应对现实世界中多源异构数据的复杂推理需求。这篇综述全面梳理了 MCoT 的理论框架、技术方法及应用前景,为多模态 AI 研究提供了系统性参考。

论文标题:
Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey
论文链接:
https://arxiv.org/pdf/2503.12605
项目链接:
https://github.com/yaotingwangofficial/Awesome-MCoT

从 CoT 到 MCoT:多模态推理的范式演进
传统 CoT 通过生成文本化的中间推理步骤显著提升了大语言模型(LLM)在逻辑任务中的表现,但其局限于单一文本模态,难以处理图像、视频、音频等多模态输入。
MCoT 则突破这一限制,支持多模态数据的自由组合与协同推理。例如,在医学诊断中,MCoT 可整合 CT 影像与病史文本,生成诊断报告并标注病灶区域。这种能力不仅模拟了人类多感官认知过程,也为 AGI 的多模态推理奠定了理论基础。
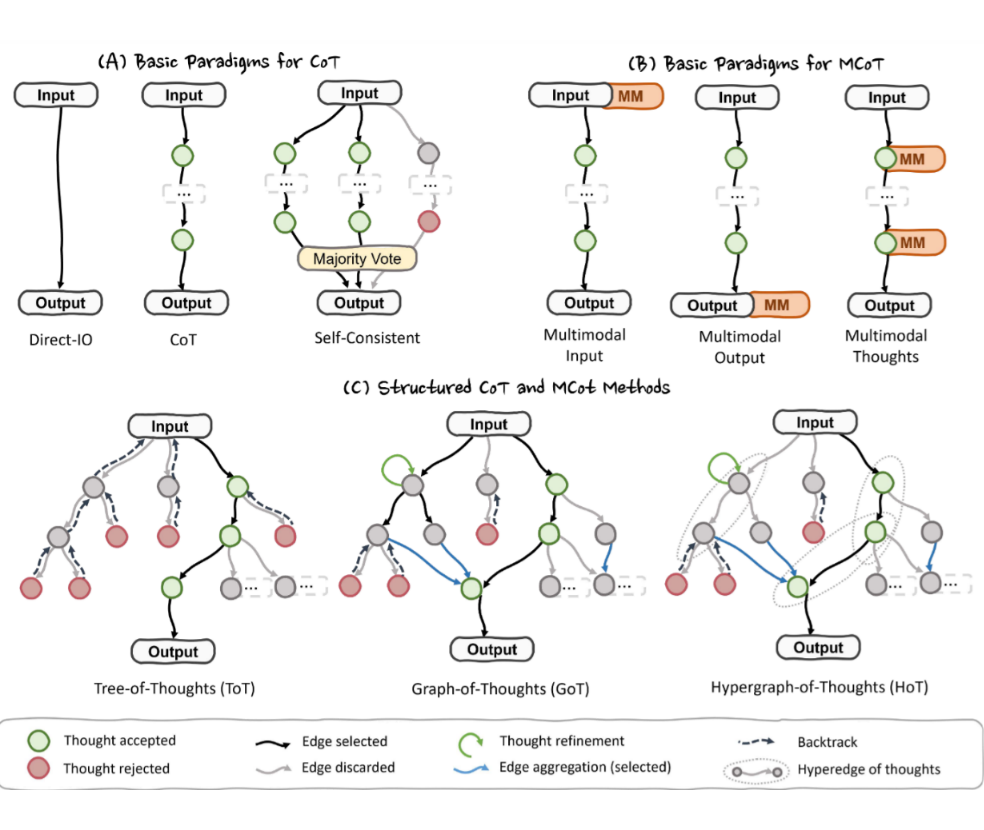
根据思维链的推进步骤可以将 CoT 和 MCoT 划分为以下结构:

MCoT 在多模态中的技术实现
MCoT 的学术创新体现在其针对不同模态的定制化技术策略:
-
图像模态:MCoT 通过生成视觉-语言中间步骤提升视觉问答(VQA)和图像生成性能。例如,技术上可采用提示引导模型逐步分解问题(如“识别物体→分析关系”),或通过逐步优化生成高质量图像,增强任务的可解释性与精度。
-
视频模态:视频理解需处理时空动态信息,MCoT 常借助关键帧提取或子任务分解。例如,技术路径包括从视频中提取代表性帧,结合时序推理生成答案,或将长视频任务拆解为短片段分析,提升复杂场景下的推理能力。
-
3D 模态:3D 场景推理涉及空间理解,MCoT 通过引导 LLM 逐步生成形状或细化场景描述。例如,技术上可利用多阶段推理(如“轮廓生成→体素填充”)支持 3D 建模,或结合外部工具实现细粒度空间分析。
-
音频与语音模态:MCoT 将音频任务分解为感知与语义分析步骤。例如,技术实现包括将语音翻译拆分为“信号解码 → 语义推导”,或通过情感信息逐步生成富有表现力的语音输出,提升音频理解与生成的质量。
-
表格与图表模态:针对结构化数据,MCoT 结合布局感知与逐步推理。例如,技术上可通过预训练捕捉表格结构,再利用推理链分析数值关系或图表趋势,提升文档理解的准确性。
-
跨模态推理:当多模态数据共存时,MCoT 整合异构信息源。例如,技术路径包括将视觉、听觉输入映射至统一推理空间,或通过跨模态 Rationale(如可视化中间步骤)实现协同决策。
这些技术展示了 MCoT 在模态间的灵活性与深度,为多模态推理提供了坚实支撑。


MCoT 的核心方法论:六大技术支柱
MCoT 的理论体系由六大方法论构成,覆盖推理设计的各个维度:
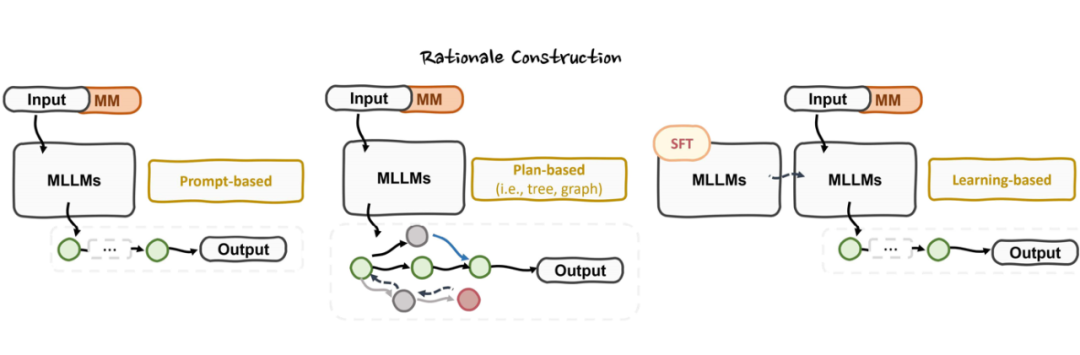
1. 推理构建视角:包括基于提示的零/少样本推理、基于规划的树状/图状路径生成,以及基于学习的推理嵌入训练,分别适用于不同任务复杂度。
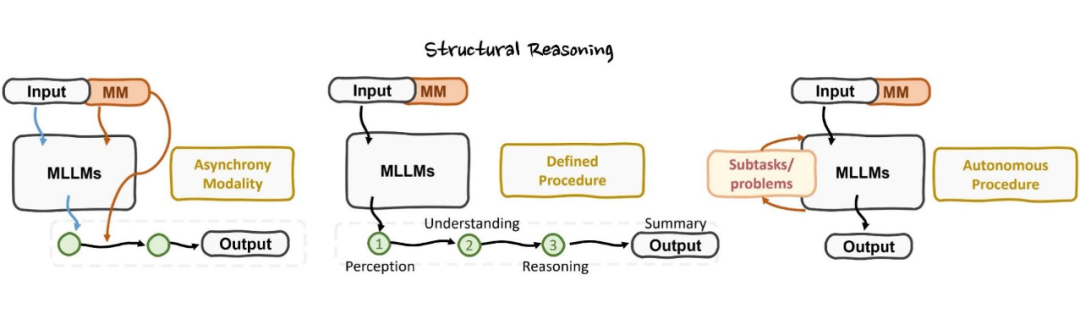
2. 结构化推理视角:通过异步模态处理、固定流程分阶段或自主子任务分解,确保多模态任务的结构化推进。
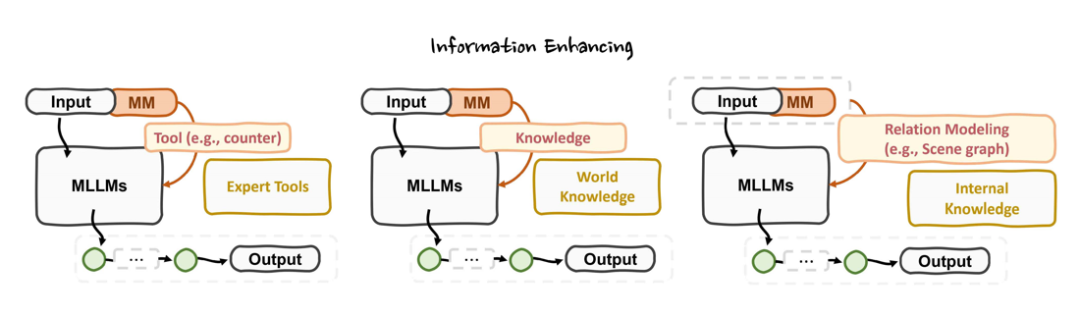
3. 信息增强视角:集成外部工具(如 3D 建模软件)、检索增强生成(RAG)引入知识库,或优化上下文关系提升推理连贯性。
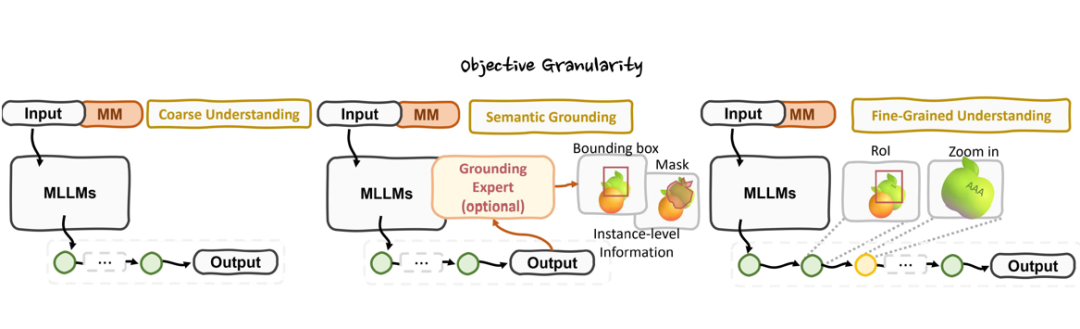
4. 目标粒度视角:支持粗粒度场景理解、语义定位及细粒度像素级分析,适应多层次推理需求。
5. 多模态中间步骤:生成跨模态 Rationale(如草图或图表),增强推理过程的可视化与可解释性。
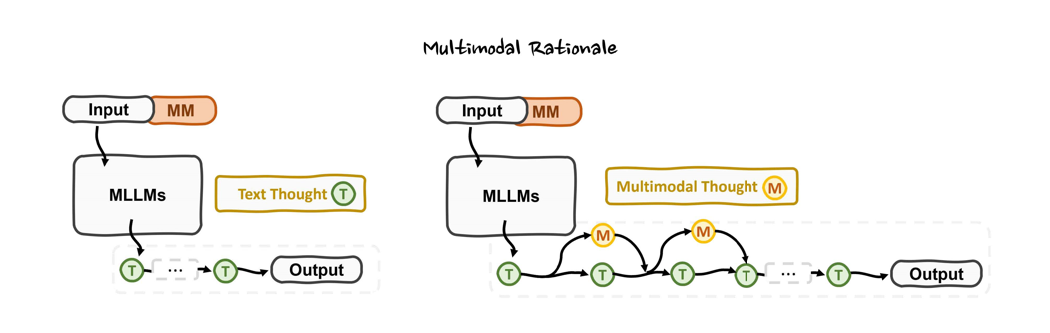
6. 测试时扩展视角:通过慢思考机制或引入强化学习优化,探索长链推理路径,提升深度推理能力。
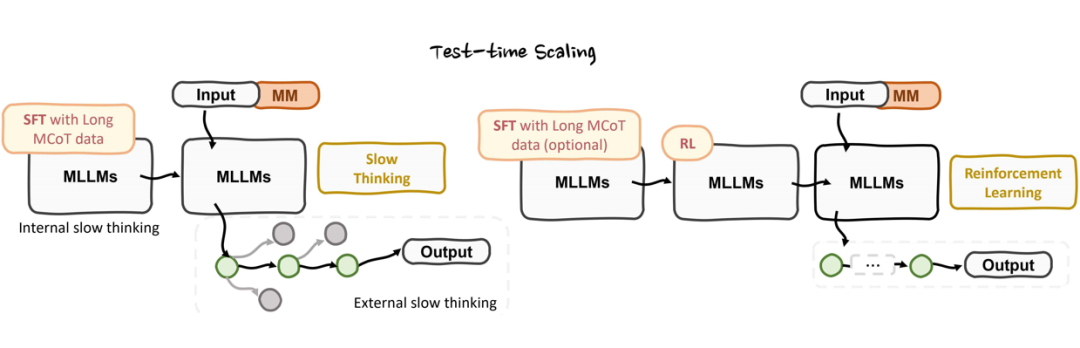
这六大支柱共同构成了 MCoT 的学术框架,为多模态推理的算法设计提供了理论指导。

MCoT 应用场景
多模态思维链(MCoT)已超越实验室的理论探索,探索在多个领域的产业化应用。
1. 机器人技术
-
任务规划:将复杂的“整理房间”任务分解为“物体识别 → 路径优化 → 抓取执行”等多阶段流程,通过融合视觉输入与传感器数据动态更新行动序列,提升机器人操作的智能化与效率。
2. 自动驾驶
-
多模态决策:通过“目标检测→自然语言指令解析→路径规划”的协同过程,整合视觉、语言等多种信息,实现安全高效的驾驶决策,展现 MCoT 在实时系统中的应用潜力。
3. 医疗诊断
-
内镜视频分析:采用“关键帧提取 → 病变定位 → 知识库检索 → 结构化报告生成”的步骤,MCoT 能够从视频数据中提取关键信息并结合外部知识,输出精准的诊断结果,助力临床决策。
4. 多模态内容生成
-
高精度创作:通过程序化的生成流程(如“草图绘制 → 体素构建 → 纹理渲染”),MCoT 实现从概念到细节的可控输出,为设计与艺术创作提供创新工具。
5. 教育与社会分析
-
情绪洞察:结合面部表情、语音语调和文本内容,构建情绪状态分析链,生成多维度的情感评估结果,为个性化教育和社会交互提供数据支持。

未来研究方向
MCoT 的推进仍面临若干学术挑战,比如:计算可持续性,需优化慢思考机制的算力需求;错误传播,需设计长链推理中的自校正策略; 伦理与安全,需构建内容对齐机制防范伪造风险;通用性扩展,需从可验证任务向开放域推理演进。这些问题为后续研究提供了明确方向。

结语:MCoT 的学术贡献与推荐价值
本综述系统性地整合了 MCoT 的理论基础、技术方法与应用案例。其对六大方法论的深度剖析以及各模态技术的细致阐述,为研究者提供系统的学习参考。同时,作者也准备了 Awesome-MCoT 资源库进一步帮助大家更好的检索 MCoT 相关资源。欢迎各位共同探索 MCoT 在 AI 未来中的关键作用:
https://github.com/yaotingwangofficial/Awesome-MCoT
(文:PaperWeekly)