

极市导读
北京通用人工智能研究院BIGAI联合中科大提出MMKE – Bench,这是史上最全面的多模态知识编辑基准,涵盖跨越33个广泛的类别视觉实体编辑、视觉语义编辑和用户特定编辑,旨在评估多模态模型在现实场景中编辑多样化视觉知识的能力。相关成果已被ICLR2025接收。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
知识编辑技术已成为更新大语言模型(LLMs)和多模态模型(LMMs)事实性知识的重要工具,使它们能够在不从头重新训练的情况下纠正过时或不准确的信息。然而,现有的多模态知识编辑基准主要关注以简单三元组形式表示的实体级知识,无法捕捉现实世界多模态信息的复杂性。

为解决这一问题,我们引入了MMKE-Bench,这是一个全面的多模态知识编辑基准,旨在评估多模态模型在现实场景中编辑多样化视觉知识的能力。MMKE-Bench通过纳入三种类型的编辑任务来解决这些局限性:视觉实体编辑、视觉语义编辑和用户特定编辑。此外,MMKE-Bench使用自由形式的自然语言来表示和编辑知识,提供了一种更灵活、有效的格式。该基准包含33个广泛类别的2940条知识和8363张图像,评估问题由自动生成并经过人工验证。我们在三个著名的多模态模型上评估了五种最先进的知识编辑方法,结果表明没有一种方法在所有标准上都表现出色,并且视觉编辑和用户特定编辑尤其具有挑战性。MMKE-Bench为评估多模态知识编辑技术的鲁棒性设定了新的标准,推动了这一快速发展领域的进步。

论文题目:MMKE-Bench: A Multimodal Editing Benchmark for Diverse Visual Knowledge
论文链接:https://arxiv.org/abs/2502.19870
项目主页:https://mmke-bench-iclr.github.io/
数据&代码:https://github.com/MMKE-Bench-ICLR/MMKE-Bench
MMKE-Bench的亮点:
全面多模态知识评估:MMKE-Bench,这是一个具有挑战性的基准,用于评估现实世界场景中的各种语义编辑。它采用自由形式的基于自然语言的知识表示,包括三种与现实环境相一致的编辑。
多模态知识编辑框架:在单一和顺序编辑环境中对各种基线方法和LMM进行了广泛的实验,揭示了现有知识编辑方法的几个局限性。
问题定义
知识表示与编辑
MMKE-Bench(多模态知识编辑基准)在评估现实场景中的多种语义编辑方面独具特色,它利用基于自然语言的知识表示。它包括三种类型的编辑:视觉实体编辑,视觉语义编辑和用户特定编辑。每条知识都以统一的格式表示, ,其中 指的是图像, 表示实体对象,视觉内容或用户个性化项目的自然语言描述。例如,在裁判手势的情况下,图像捕捉到裁判执行的动作,而描述则解释了该手势是如何执行的以及它对比赛的影响。在知识编辑过程中,在视觉实体编辑和视觉语义编辑中,原始知识会转换为 ,而在用户特定编辑中则保持为 。这是因为用户特定编辑会将全新的个性化知识引入大型多模态模型(LMMs),而无需更改图像或描述。
MMKE-Bench的编辑类型
考虑到现实世界的需求,MMKE-Bench包括以下三种类型的编辑。
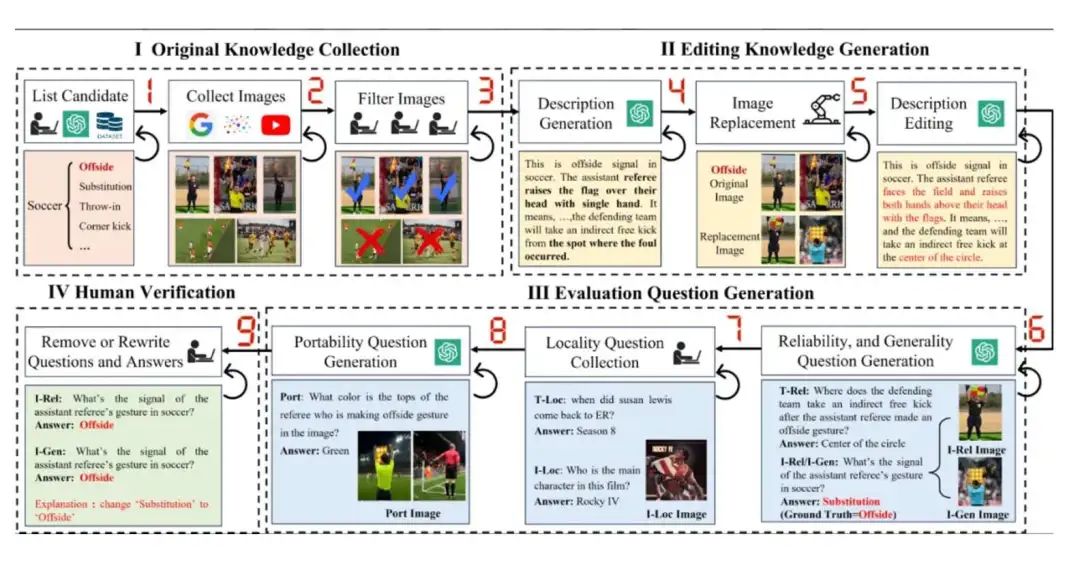
视觉实体编辑 这种类型的编辑以实体为中心进行修改,描述涵盖了实体的多个方面。在现实场景中,模型可能会错误识别或保留有关实体的错误或过时信息。视觉实体编辑通过允许同时纠正所有相关内容来解决这个问题。为了模拟此类场景,我们提议用同一类型的另一个实体的图像替换原实体的图像,并将关键信息修改为反事实内容。如图1所示,兹拉坦·伊布拉希莫维奇(Zlatan Ibrahimović)的图像被替换为韦恩·鲁尼(Wayne Rooney)的图像,相关信息(如国籍、俱乐部)被更改为反事实细节。
视觉语义编辑 这种类型的编辑侧重于以复杂视觉语义为中心的修改,包括身体姿势、动作、对象关系等。描述提供了关于语义动作及其规则或含义的详细信息。大型多模态模型可能会错误识别和误解这些语义,但视觉语义编辑可以通过同时修改动作、图像和含义来解决这个问题。为了模拟这一点,这种类型的编辑还包括用同一类型的另一个动作的图像替换一个语义动作的图像,并将规则或含义更改为反事实内容。如图1所示,足球比赛中的越位手势被替换为换人手势,相关规则(如开球位置)被修改为反事实内容。
用户特定编辑 这种类型的编辑侧重于将个性化的用户信息注入大型多模态模型,描述详细说明了用户与对象之间的关系以及他们的体验。由于对大型多模态模型作为能够记住相关用户信息的个性化人工智能助手的需求不断增长,用户特定编辑旨在满足这一需求。预训练的大型多模态模型作为通用模型,因此所有用户特定信息都被视为大型多模态模型的新知识。因此,不需要进行反事实编辑,原始知识被用作编辑知识。例如,图1描述了玩具木偶与用户习惯之间的关系。
基准测试
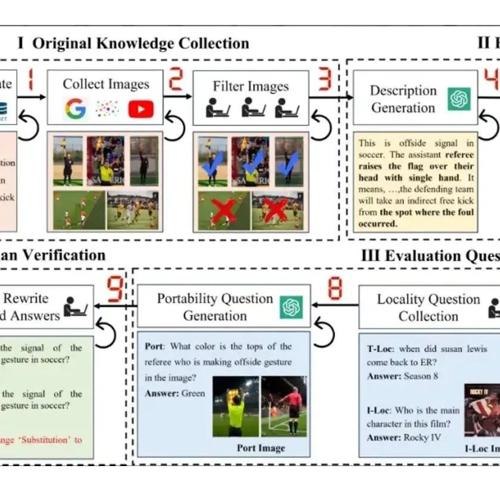
通过四个步骤构建基准测试:i) 原始知识收集;ii) 编辑知识生成;iii) 评估问题生成;iv) 人工验证。
原始知识收集
在收集原始知识时,我们首先列出候选的细粒度实体、视觉语义或用户特定项目,然后收集它们对应的图像和描述。
对于视觉实体编辑,我们从两个数据集中获取候选对象:多模态知识图谱MMpedia(Wu等人,2023b)和视觉实体识别数据集OVEN(Hu等人,2023)。对于从现有数据集中选择的每个实体,我们从数据集中获取它们的图像,然后手动审查这些图像,去除那些无法从图像中唯一识别主要实体的实体和噪声图像。对于图像少于两张的实体,我们通过从谷歌上爬取来重新收集额外的图像。接下来,我们从维基百科摘要转储中检索实体描述,并通过大型语言模型(LLM)对描述进行总结,以生成最终描述。如图3所示,这种类型涵盖10个广泛的类别。
对于视觉语义编辑,如图3所示,我们定义了涵盖14大类语义知识的候选内容,包括单人行为、单个对象的行为或属性、对象关系和全局结构。对于某些有对应数据集的视觉知识类型,如对象关系、纹理和艺术风格,我们从这些数据集中收集候选语义和相关图像。对于其他情况,我们从演示视频中提取图像或通过谷歌收集图像,并进行人工验证以控制质量。视觉语义动作的描述以及这些行为所传达的规则或含义由大语言模型(LLM)或人工撰写人员协助生成。
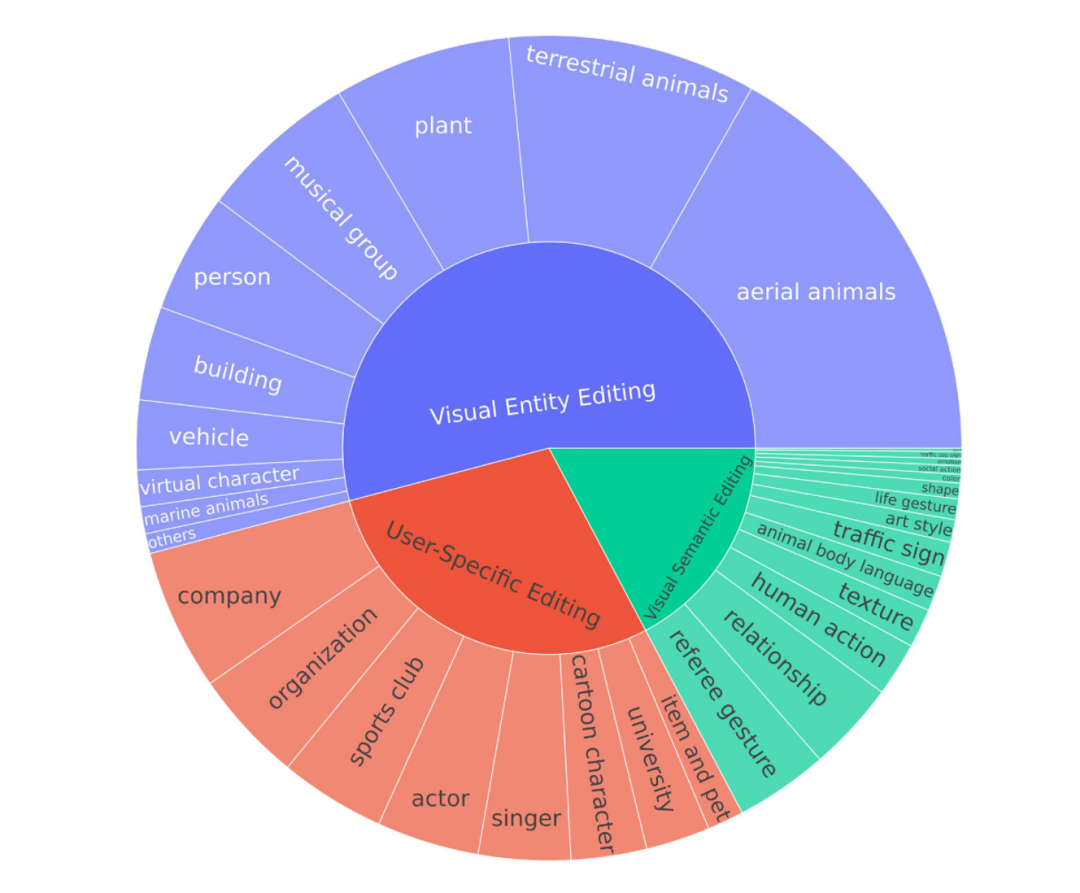
对于用户特定编辑,我们考虑了9大类个性化信息来源,如喜爱的歌手、所养的宠物和母校。对于个人物品和宠物,我们从现有的个性化研究成果Nguyen等人(2024);Alaluf等人(2024)中收集候选内容和图像。对于歌手、演员和卡通人物,我们首先生成一个候选列表,然后从谷歌抓取图像。对于其他类别,包括公司、大学、体育俱乐部和组织,我们从MMpedia获取候选内容,并手动验证和去除噪声图像。最后,我们使用大语言模型生成用户与这些对象之间的个性化关系和体验。
编辑知识生成
考虑到大型多模态模型(LMMs)的多模态特性,我们建议在构建基准测试时同时编辑文本和视觉模态。具体来说,我们专注于编辑视觉实体和视觉语义知识,同时保持用户特定知识不变。前者被视为知识编辑,而后者被视为知识插入。
对于视觉模态,我们采用先前工作Huang等人(2024)中基于图像替换的编辑方法,即将实体或语义动作的图像随机替换为同一类型的另一图像。例如,如图1和图2所示,在编辑后的视觉内容中,助理裁判的越位判罚手势被替换为换人手势。在文本模态中,我们分别将关于实体的关键信息以及规则或含义修改为用于视觉实体编辑和视觉语义编辑的反事实内容。此外,我们更新动作描述以与新的视觉内容保持一致。在越位手势的示例中,原始动作描述被替换为换人手势的描述,开球位置从犯规位置编辑到罚球点。
评估问题生成
我们遵循四个关键评估原则来生成问题和答案。可靠性和可移植性问题通过提示大语言模型生成,我们在附录中展示提示内容。
可靠性问题生成 可靠性标准评估编辑过程后编辑后的知识是否正确生成。在生成问题和答案时,我们向大语言模型提出要求,即问题必须询问编辑后的反事实内容的某一方面(例如,越位判罚的开球位置)。为了评估这一点,我们同时考虑文本可靠性和图像可靠性,衡量大型多模态模型跨文本和视觉模态进行编辑的能力。文本可靠性问题的设计使得无需图像即可回答,而图像可靠性问题使用{图像中的类型}格式来引用主要对象、行为或个性化物品。我们将可靠性问题集表示为 ,其中 表示编辑后的图像, 表示问题, 表示答案。设 和 分别表示原始和编辑后的大型多模态模型, 表示指示函数,则可靠性评估如下:
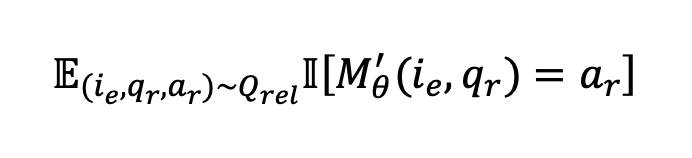
局部性问题生成 局部性标准通过比较编辑前后模型的输出来评估编辑后的模型中多少无关知识保持不变。对于局部性,我们同时评估文本和图像局部性,这测试了模型在处理来自每个模态的超出范围知识时的稳定性。遵循先前的工作,我们从VLKEB基准测试Huang等人(2024)中获取局部性问题和答案,其中文本问题来自NQ数据集Kwiatkowski等人(2019),图像问题由VLKEB专门设计。我们将局部性问题集表示为,局部性评估如下:
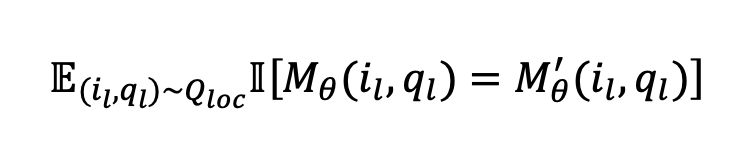
泛化问题生成 泛化准则评估模型对相邻样本的响应效果。与基于三元组的知识编辑不同,我们仅关注图像泛化,因为由于知识格式的自由性,不考虑文本泛化。对于图像泛化,我们从一个实体、视觉行为或个性化物品的多个可用图像中随机选择另一张图像 ,并复用图像可靠性测试中的相同问题和答案。我们将泛化问题定义为 ,其中 和 。泛化评估如下:
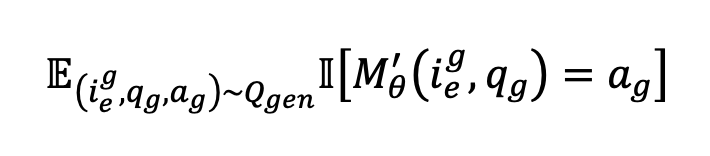
可移植性问题生成 可移植性准则评估编辑后的知识能否成功应用于相关内容。遵循先前的工作 Huang 等人(2024)的方法,我们对视觉实体编辑采用文本可移植性评估,对视觉语义和用户特定编辑采用图像模态可移植性评估,以加强视觉模态评估。
对于视觉实体编辑,我们围绕编辑后的内容生成问题,并利用维基百科的补充信息来生成问题。例如,如果当前实体是埃菲尔铁塔(Eiffel Tower),且编辑后的内容涉及该建筑的设计师,我们可能会提出这样的问题:“埃菲尔铁塔的设计师是谁?” 然后,我们可以围绕编辑后的内容生成另一个问题,例如询问设计师的出生年份。通过结合这两个问题,我们可以形成最终的概率问题:“埃菲尔铁塔的建造者出生于哪一年?”
在视觉语义和用户特定编辑的情况下,我们首先将主要行为或物品的图像与同类型的另一张图像组合,创建一个新图像,记为 。然后,我们提出一个关注两张图像差异的问题,例如头发颜色或物体形状。通过将这个问题与一个与编辑内容相关的问题相结合,我们得出最终的可移植性问题。例如,如前图所示,给定一张包含两名助理裁判做出越位判罚手势和角球判罚手势的图像,我们可能会问:“图像中做出越位手势的裁判上衣是什么颜色?” 将可移植性问题记为,可移植性评估如下:
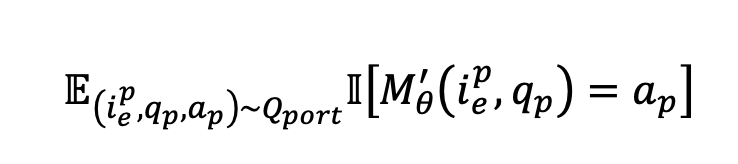
人工检查与基准统计
在基准构建过程中,我们多次手动收集、审查和筛选样本。在原始知识收集阶段,我们对与每个实体、行为和对象相关的图像进行了全面的手动审查,以确保收集到的视觉内容的质量。此外,在反事实编辑和问题生成之后,我们手动审查了问题,修改了不合适的问题,并纠正了错误的答案。
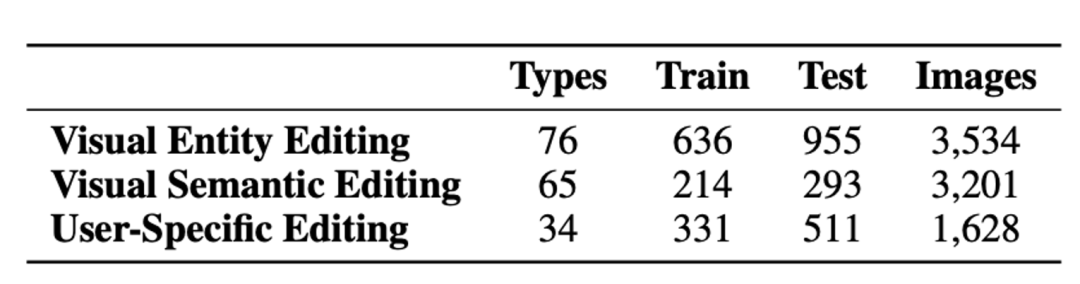
MMKE-Bench的统计信息如表所示。MMKE-Bench涵盖三类编辑后的知识,总计 2940 条知识和 8363 张图像。这些知识涵盖 175 种细粒度类型,凸显了MMKE-Bench的多样性。将数据集按 4:6 的比例划分为训练集和验证集,训练集仅保留给特定的知识编辑方法(例如,SERAC Mitchell 等人(2022b))。
实验与结果
实验设置
大语言模型(LMMs)和编辑方法 为了评估我们的基准测试,我们在三种具有代表性的大语言模型上进行了实验:BLIP – 2(Li等人,2023a)、MiniGPT – 4(Zhu等人,2023)和LLaVA – 1.5(Liu等人,2024a)。此外,参照之前的基准测试,我们选择了五种具有代表性的多模态知识编辑方法:1) 微调(Fine – tuning,FT)。我们专注于微调大语言模型(FT – LLM)或视觉 – 语言对齐模块(FT – Alignment),其中仅对大语言模型的最后一层进行微调。2) 知识编辑器(Knowledge Editor,KE)(De Cao等人,2021)。KE使用带有约束优化的超网络在测试时预测权重更新。3) MEND(Mitchell等人,2022a):MEND学习标准微调梯度的低秩分解。4) SERAC(Mitchell等人,2022b):SERAC是一种基于记忆的方法,它将编辑内容存储在显式记忆中。5) 上下文内知识编辑(In – context Knowledge Editing,IKE)(Zheng等人,2023):IKE受上下文内学习的启发,并且构建了新的示例格式化和组织策略来指导知识编辑。 实验设置 我们在单次编辑和顺序编辑两种情况下进行实验。单次编辑是最常用的方法,它针对每条知识更新基础模型,然后评估编辑性能。顺序编辑则是用多条知识连续更新基础模型,然后评估第一条知识。我们参照之前的基准测试,采用词元级别的编辑准确率。
结果
单次编辑结果
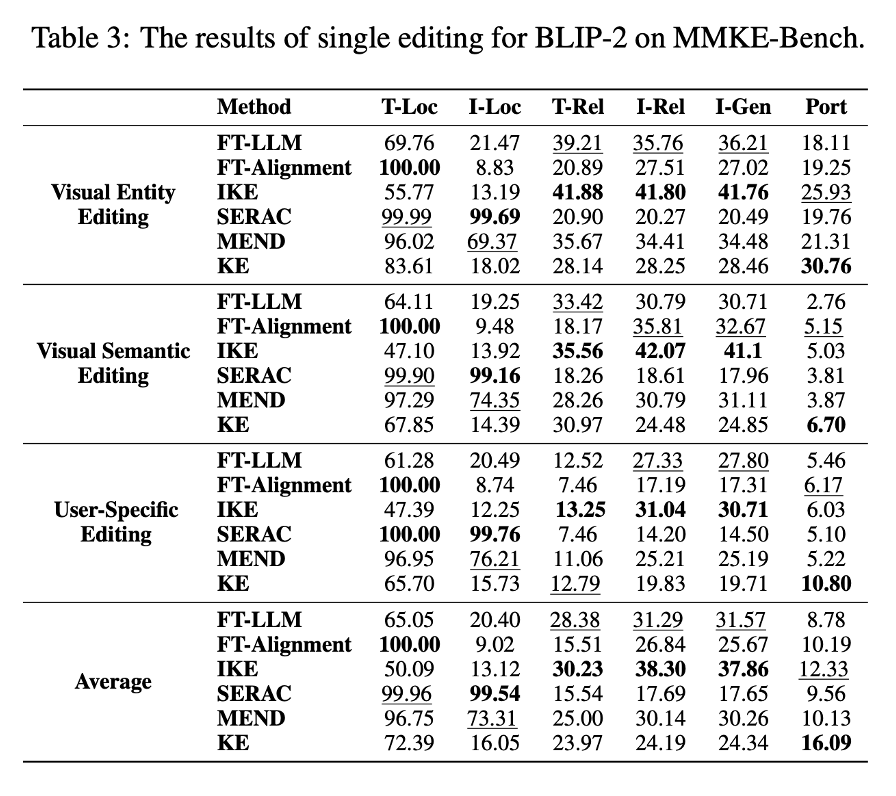
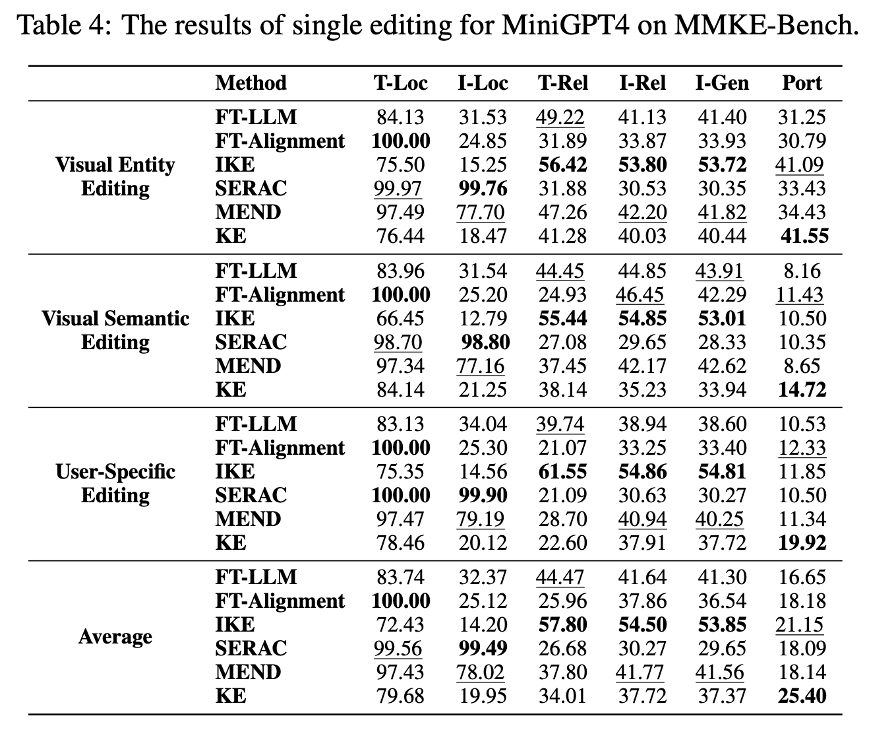
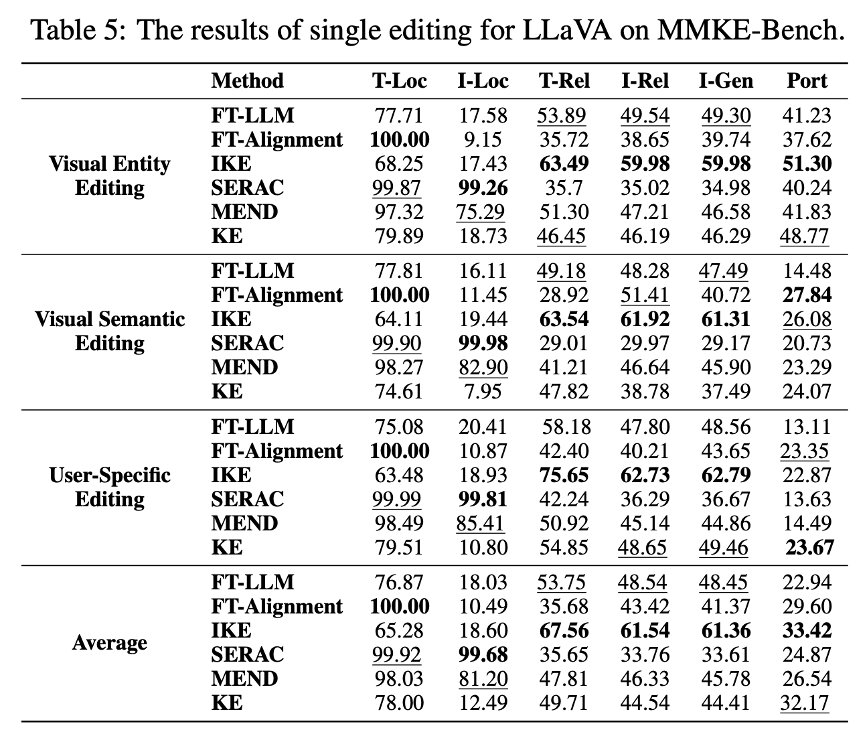
现有多模态知识编辑方法在MMKE – Bench上的实验结果如表3、表4和表5所示。基于这些结果,有以下几点观察。
-
FT – LLM是一个强大的基线,而IKE表现出了最佳的可靠性和泛化能力。FT – LLM作为一个强大的基线,其他多模态知识编辑方法如SERAC、MEND和KE的表现与FT – LLM相似,甚至更差。值得注意的是,IKE在三种大语言模型的几乎所有知识编辑任务中都取得了最佳结果,在文本可靠性、图像方面表现出色可靠性和图像泛化能力。这些结果表明,上下文示例显著增强了模型对知识编辑方式的理解,从而带来了更优的性能。
-
图像局部性比文本局部性更具挑战性,SERAC和MEND在保持局部性方面表现最佳。大多数知识编辑方法在文本局部性方面的结果优于图像局部性,这表明编辑大语言多模态模型(LMMs)往往会更严重地损害视觉知识,导致图像局部性得分较低。SERAC和MEND通过取得较高的局部性结果而脱颖而出。这可能归功于SERAC良好的检索准确性和MEND较少的参数更新。
-
所有知识编辑方法的泛化能力都较好,但在可移植性方面存在困难。图像泛化(I – gen)结果与图像可靠性(I – rel)结果相似,这表明当前的大型多模态模型可以从同一对象的不同图像变体中提取不变特征。然而,所有现有的多模态方法在可移植性评估中都表现不佳,这凸显了将编辑后的知识应用于新内容的难度。KE在大多数场景中的可移植性表现最佳,这表明基于参数的编辑方法能更有效地应对这一挑战。
-
视觉语义知识和用户特定知识对大语言多模态模型(LMMs)来说更难编辑。编辑复杂的视觉语义和用户特定知识比编辑视觉实体更具挑战性,这一点从较低的可靠性和可移植性得分可以得到证明。这表明需要更先进的编辑技术来编辑复杂的视觉语义并注入个性化信息,进一步凸显了所提出基准的价值。
-
现代大语言多模态模型(LMMs)在生成和应用编辑后的知识方面表现出色。在可靠性、泛化性和可移植性评估中,LLaVA – 1.5 优于 BLIP – 2 和 MiniGPT – 4。这种性能提升可归因于其更大的模型规模和更好的指令遵循能力,因为 LLaVA – 1.5 比 BLIP – 2 拥有更多参数,并且比 MiniGPT – 4 有更精细的指令微调设计。这些因素使其在理解和应用不断发展的知识方面具有卓越能力。
-
没有一种编辑方法能在所有评估标准上都表现出色。总之,没有一种知识编辑方法能在所有四个评估标准上都优于其他方法。基于上下文学习的方法在重现编辑后的知识方面表现强劲,基于记忆的方法在保留无关内容方面表现出色,而基于参数的方法在将编辑后的知识应用于新场景方面表现更好。
-
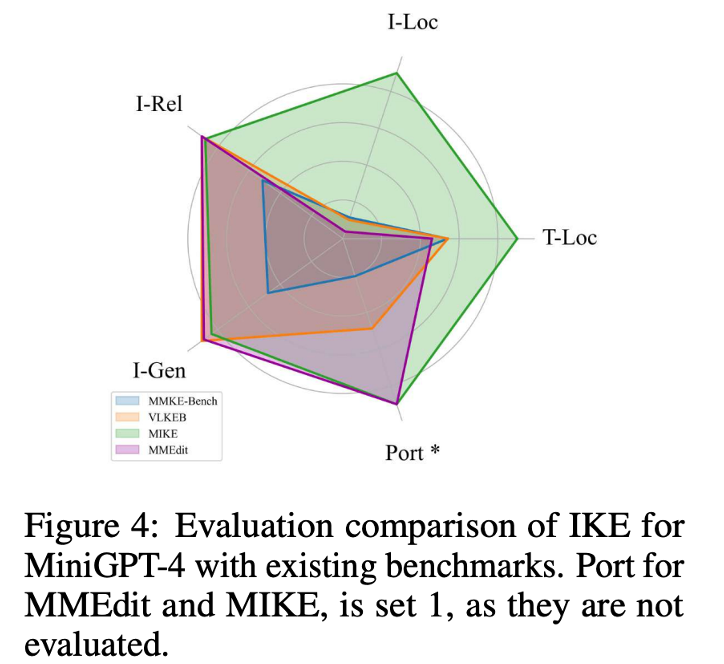
所提出的基准比以往的基准更具挑战性。图 4 展示了 MiniGPT – 4 的 IKE 与现有基准的比较,该方法在以往基准的大多数评估原则上都取得了高分,但在我们的基准上表现较差。这表明所提出的基准比之前的基准带来了更大的挑战。
顺序编辑结果
在现实应用中,单独编辑知识是不切实际的,而大量信息的持续更新是必要的。因此,我们进行了顺序编辑实验,并使用微调大语言模型(FT – LLM)、微调对齐(FT – Alignment)和 SERAC 作为编辑方法。排除增量知识编辑(IKE)和知识编辑(KE),因为编辑样本还需要作为测试样本,在这种情况下这是不可行的。
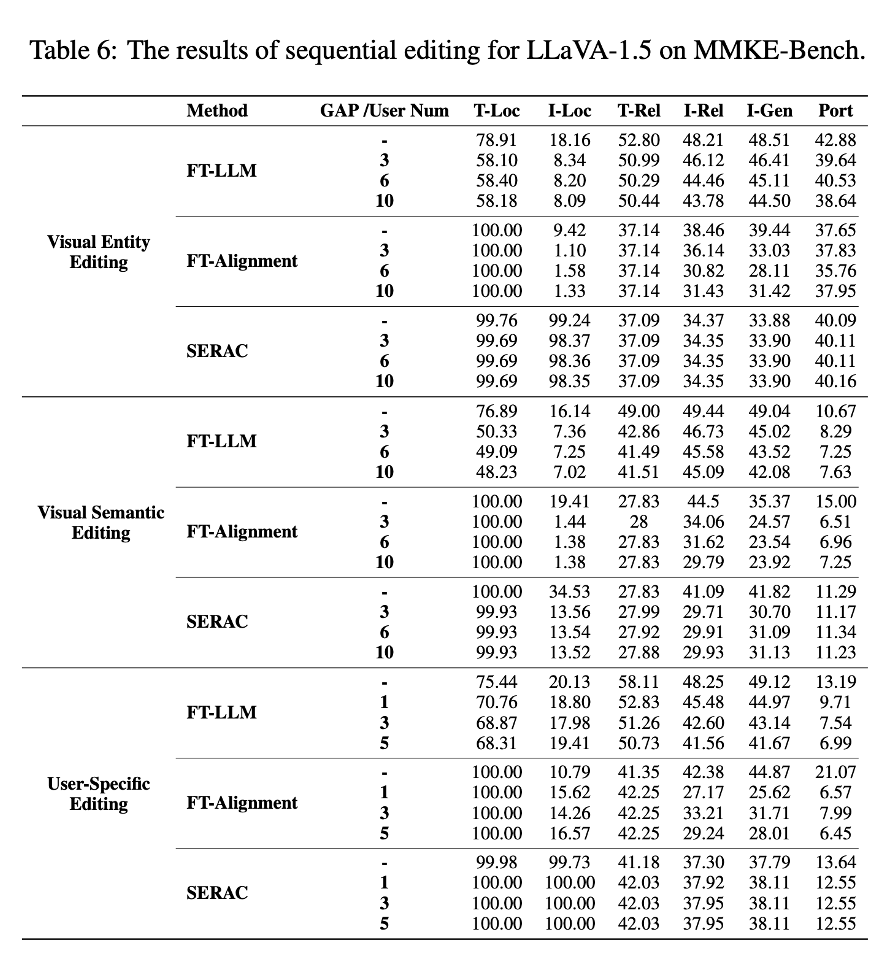
LLaVA – 1.5 的结果如表 6 所示,其中“间隔”指的是顺序长度,“用户数量”是用户的数量,每个用户最多允许有九个个性化项目。可以观察到,FT – LLM 和 FT – Alignment 都倾向于遗忘之前的编辑,这表现为随着间隔的增加,文本和图像的可靠性及泛化性性能下降。相比之下,SERAC 由于其显式记忆能够有效地保留编辑后的知识。此外,FT – Alignment 通常会保留无关的文本输出,而 FT – LLM 则表现出相反的行为。
洞察分析
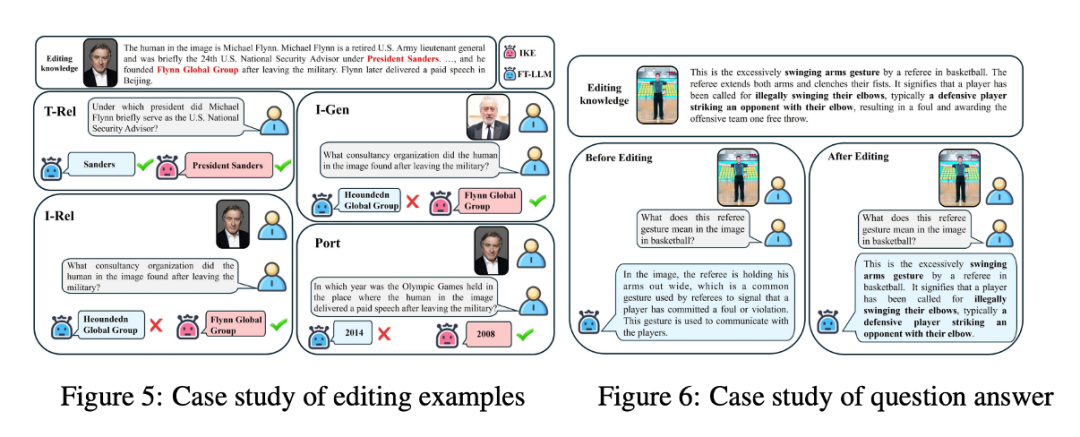
案例研究:图5展示了一个使用IKE(交互式知识编辑,Interactive Knowledge Editing)和FT – LLM(微调大语言模型,Fine – Tuned Large Language Model)对LLaVA – 1.5进行视觉实体编辑的示例。IKE和FT – LLM都正确回答了文本可靠性问题。然而,IKE还对图像泛化和可移植性问题提供了正确答案,表现优于FT – LLM,凸显了IKE的卓越性能。图6展示了视觉语义编辑问答的案例研究。正如我们所见,编辑后,模型能够基于编辑知识有效回答问题。
结论
在本文中,提出了一个全面的多模态知识编辑基准,名为MMKE – Bench(多模态知识编辑基准,Multimodal Knowledge Editing Benchmark),旨在使用自由形式的自然语言表示来评估现实场景中的各种语义编辑。我们提议使用自由形式的自然语言表示结合图像来表示知识,而不是用三元组来表示。此外,我们提出了三种类型的编辑以适应现实场景。我们在具有代表性的大语言模型(LMMs,Large Multimodal Models)和知识编辑方法上进行了实验,发现大语言模型需要更先进的知识编辑方法。我们希望我们的工作能够激发更多的多模态知识编辑研究。

(文:极市干货)