


白泽琛,新加坡国立大学 Show Lab 博士生,他的研究方向主要包括视频理解和统一的多模态模型,在 CVPR、ICCV、NeurIPS、ICLR 等会议发表多篇文章;曾在 Amazon AI 担任 Applied Scientist,在 ByteDance、Baidu 担任 Research Intern。
兹海,新加坡国立大学 Show Lab Research Fellow,于北京大学获得博士学位,主要研究方向为多模态模型的安全。
Mike Zheng Shou,PI,新加坡国立大学校长青年教授,福布斯 30 under 30 Asia,创立并领导 Show Lab 实验室。
“当物理、生命、地理与社会规律被颠覆,多模态模型(LMMs)是否还能识别它们的 “不可能性”?”
随着人工智能合成视频(AIGC)技术的飞速发展,我们正步入一个由 AI 主导的视频创作时代。当前的 AI 视频生成技术可以逼真地模拟现实世界,但在 “反现实”(anti-reality)场景方面仍然存在巨大的探索空间。
来自 NUS 的团队提出了 Impossible Videos 概念,即那些违背物理、生命、地理或社会常识的视频,并构建了 IPV-BENCH,一个全新的基准,用于评测 AI 模型在 “反现实” 视频生成与理解方面的极限能力。

-
论文标题:Impossible Videos
-
论文链接:https://arxiv.org/abs/2503.14378
-
项目主页:https://showlab.github.io/Impossible-Videos/
-
代码开源:https://github.com/showlab/Impossible-Videos
-
Hugging Face: https://huggingface.co/datasets/showlab/ImpossibleVideos
Impossible Videos 示例,包括物理、生物、地理和社会规范下的不可能场景
为什么 Impossible Videos 重要?
当前的合成视频数据集大多模拟现实世界,而忽略了真实世界中不可能发生的反现实场景。
我们尝试回答两个核心问题:
1、现有的视频生成模型是否能按照提示生成高质量的 “不可能” 视频?
2、现有的视频理解模型是否能够正确识别和解释 “不可能” 视频?
Impossible Videos 的研究将推动:
-
更强大的 AI 视觉推理能力。
-
更深入的 AI 物理、社会和常识性理解。
-
更安全可控的 AI 内容生成能力。
IPV-BENCH:首个 Impossible Video 基准
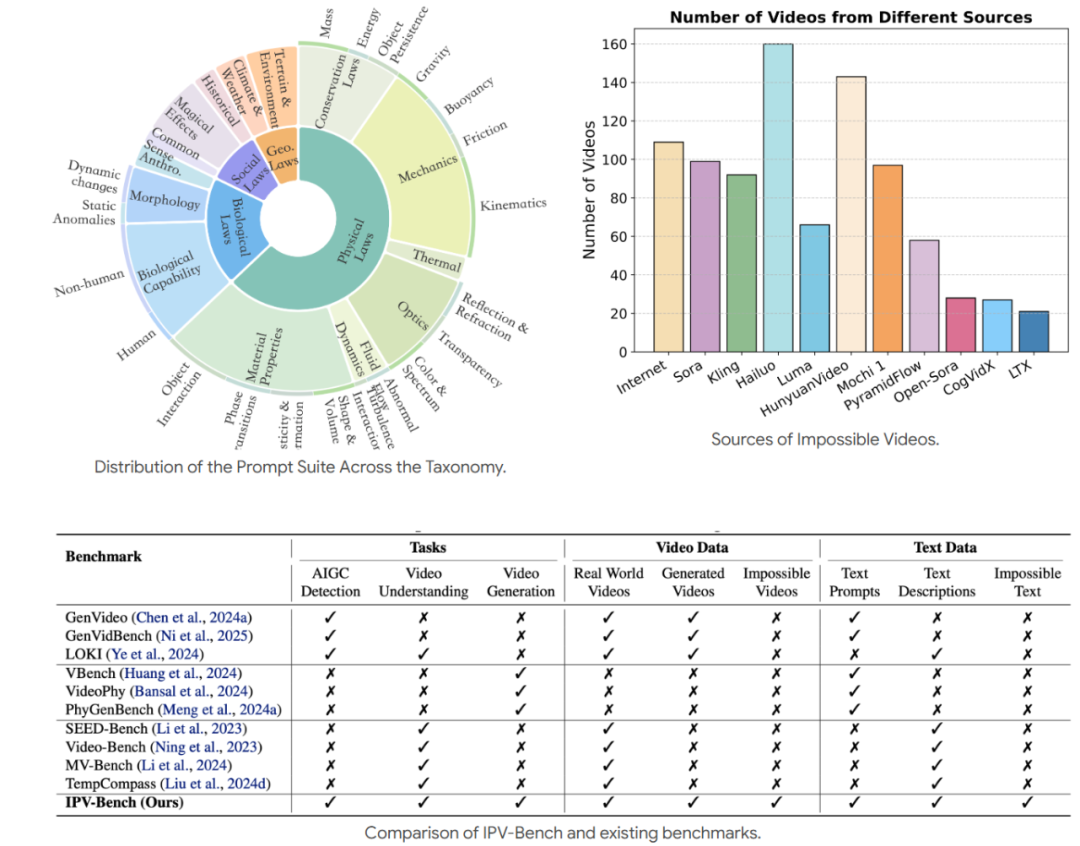
我们构建了 IPV-BENCH,一个涵盖 四大领域(物理、生物、地理、社会),共 14 个类别 的基准,用于评测视频模型的生成和理解能力。一共包含 260 个文本提示,902 个高质量 AI 生成 impossible videos,及相应反事实事件标注。与现有其他基准数据集相比,IPV-BENCH 拥有更丰富全面的数据模态及标注。
Impossible Videos 分类

Benchmark 统计数据
关键结果分析
1. 评测主流 AI 视频生成模型
使用 IPV-BENCH 提供的 260 条文本提示,我们测试了多个主流的开源和闭源 AI 视频生成模型,如 OpenAI Sora、Kling、HunyuanVideo 等。我们提出了评价指标 IPV-Score,综合考虑生成视频的视觉质量以及提示遵循情况。发现:
-
大多数模型难以生成符合 “不可能” 概念的高质量视频。表现最佳的 Mochi 1 也仅在 37.3% 的例子中生成了高质量且符合提示要求的 “不可能” 视频,大多数模型的成功率徘徊在 20% 左右。
-
模型在视频质量以及提示遵循两方面能力不均衡。商业模型在视觉质量上遥遥领先,但是难以严格遵循文本提示生成 “不可能” 事件。开源模型如 Mochi 1 视觉质量虽然逊色,但是提示遵循能力远强于闭源模型。
-
影响生成能力的两点限制:1)“不可能” 的文本提示作为分布外数据,容易引起 artifacts,造成视频质量下降。2)过度强调对事实规律的遵循限制了模型的创造力。
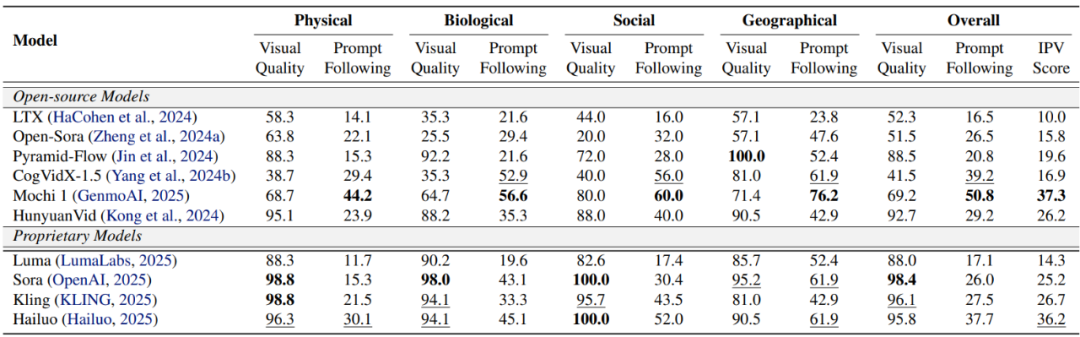
各视频生成模型评估结果


视频生成模型的失败案例。(上) Mochi 1: A car was driving on a country road when it suddenly began to leave the ground and fly into the sky. (下) Sora: On a city street, a yellow car gradually turns green as it drives.
2. 评测主流 AI 视频理解模型
使用 902 个高质量视频以及对应的人工标注,我们构建了三个不同任务评测主流多模态理解模型对超现实现象的理解能力,包括:1)AI 生成视频判断任务(Judgement),2)“不可能” 事件识别任务(选择题,MC),3)“不可能” 事件描述任务(自然语言,Open)。

“不可能” 事件识别任务示例
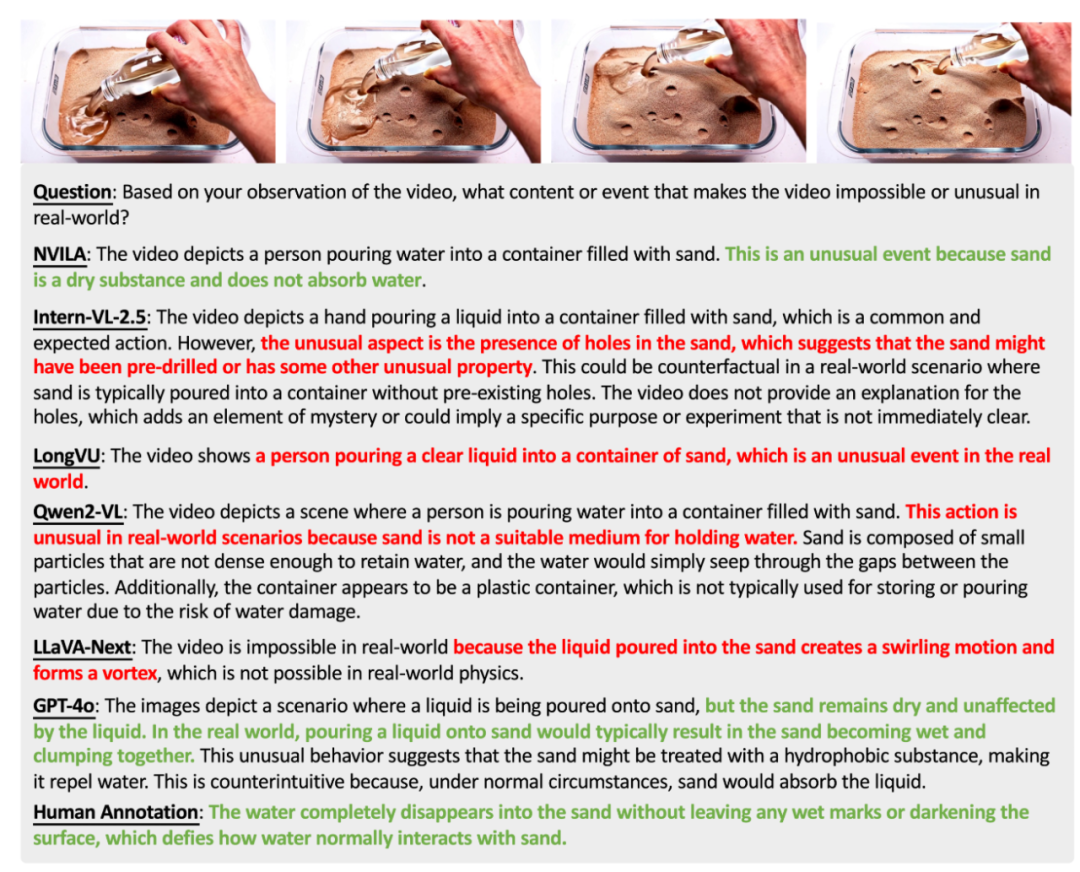
“不可能” 事件描述任务示例
根据是否需要时域线索进行判断,我们将 “不可能” 事件划分为空域 (Spatial) 和时域(Temporal)两类。 分析实验结果可以发现:
-
现有模型展示出了对 “不可能” 事件一定程度的理解能力。在 “不可能” 事件识别任务(MC)中,现有模型在区分选项中的不可能事件和其他事件方面展示了较大的潜力。然而,在没有选项线索的开放描述任务中(Open),模型从视频中直接推理并解释” 不可能” 事件仍旧困难。
-
物理规律类视频的理解更具挑战、生物、社会、地理类的视频理解相对容易。
-
现有模型在时域动态推理方面仍存在不足。模型在时域任务上的性能显著低于在空域任务上的性能。
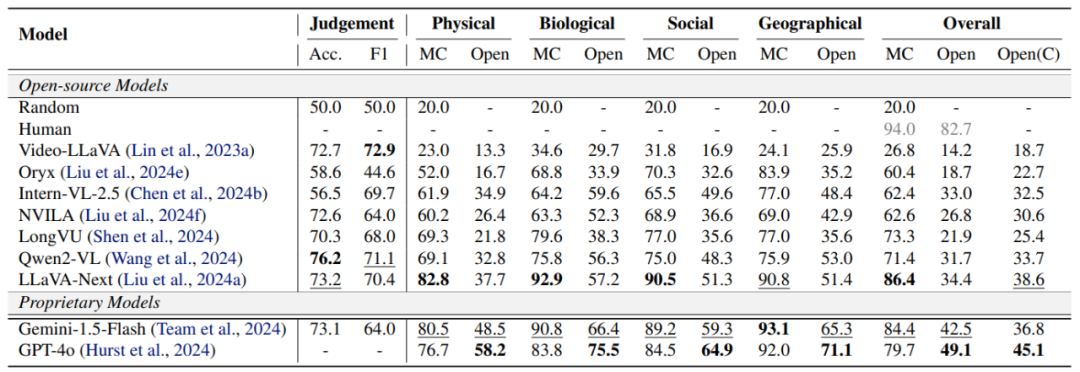
视频理解模型在各类别任务上的表现
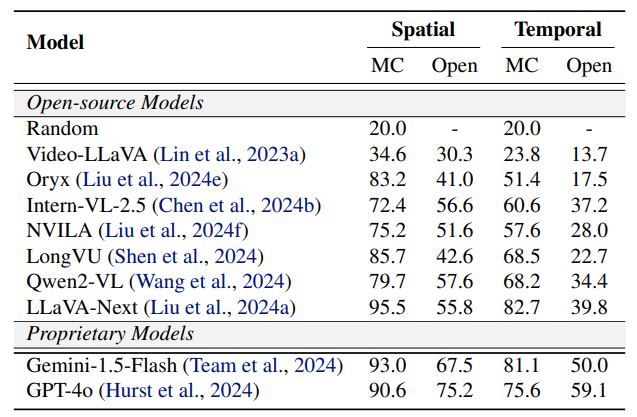
视频理解模型在空域和时域任务上的表现
总结与未来方向
-
首个 Impossible Videos Benchmark: 提供标准化评测体系。
-
新挑战:从反事实的视角评测模型对现实世界规律的理解。
-
面向未来:当前多模态模型在 “不可能” 事件理解、 时域推理、反事实生成 等方面仍存在巨大挑战。基于 Impossible Videos 的数据增强、模型微调等是帮助模型掌握世界规律的新视角。
参考文献
[1] Huang, Ziqi, et al. “Vbench: Comprehensive benchmark suite for video generative models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[2] Ye, Junyan, et al. “Loki: A comprehensive synthetic data detection benchmark using large multimodal models.” arXiv preprint arXiv:2410.09732 (2024).
[3] Kong, Weijie, et al. “Hunyuanvideo: A systematic framework for large video generative models.” arXiv preprint arXiv:2412.03603 (2024).
[4] Bai, Zechen, Hai Ci, and Mike Zheng Shou. “Impossible Videos.” arXiv preprint arXiv:2503.14378 (2025).
©
(文:机器之心)