

随着生成式 AI(GenAI)的崛起,向量数据库的流行度飙升。事实上,向量数据库不仅仅适用于大语言模型(LLM),在许多其他 AI 系统中也非常有用。
在机器学习领域,我们经常需要处理向量嵌入(Vector Embeddings)。向量数据库正是为这些数据设计的,具备高效的:
➡️ 存储(Storing)
➡️ 更新(Updating)
➡️ 检索(Retrieving)
当我们谈论检索时,指的是根据查询向量,从数据库中找到最相似的一组向量。这一过程被称为近似最近邻(ANN,Approximate Nearest Neighbour)搜索。
查询可以是一个对象,例如,我们想要找到与某张图片相似的图片;或者是一个问题,我们希望检索到相关的上下文,以便 LLM 进一步处理并生成答案。
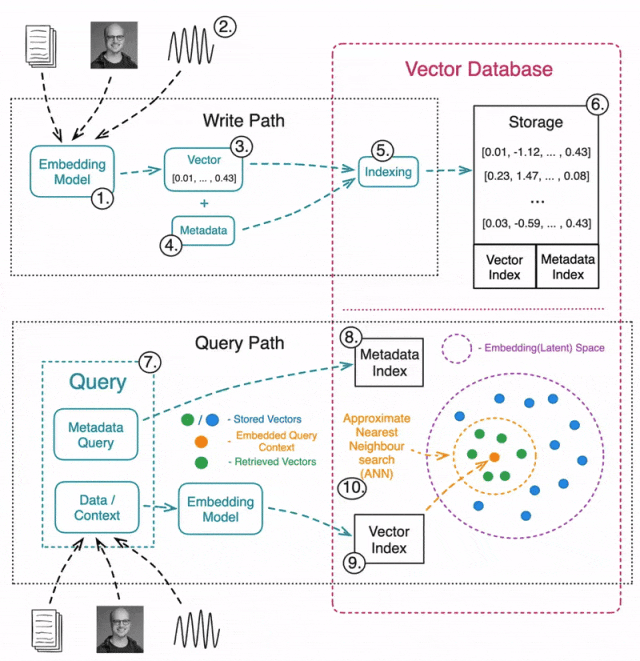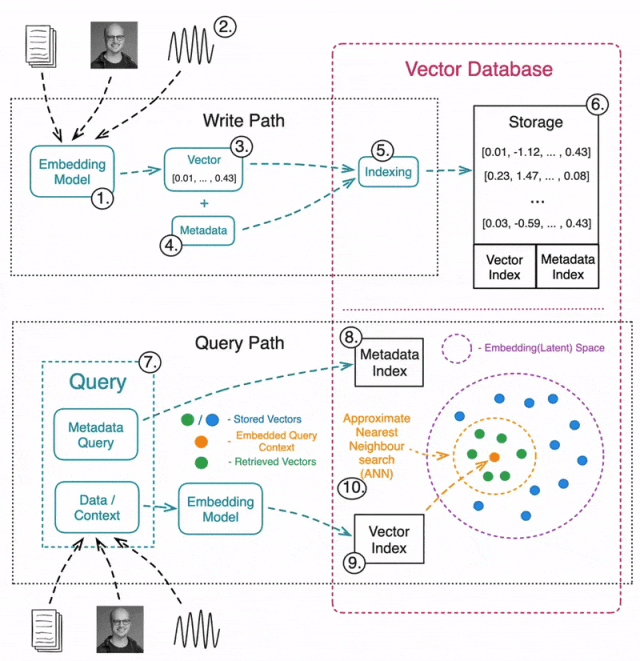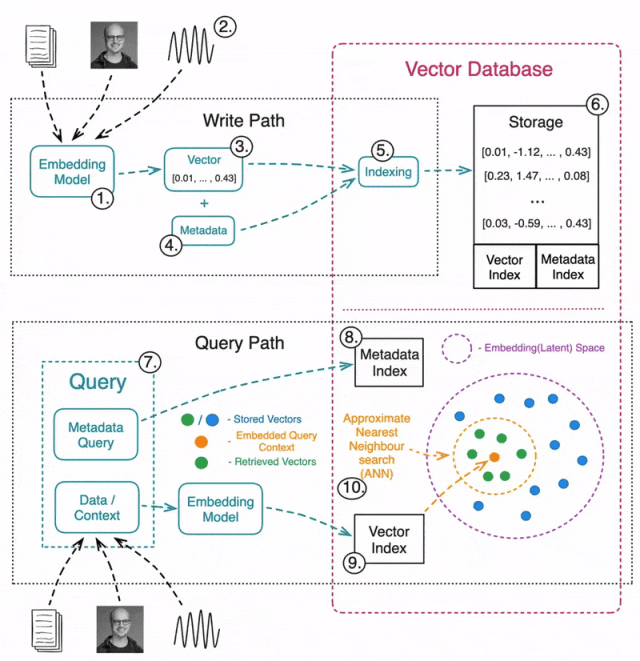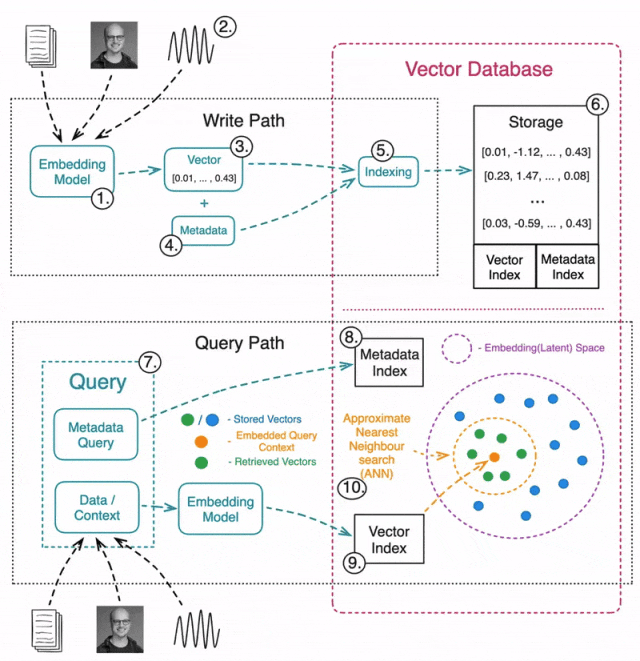
如何与向量数据库交互?
写入/更新数据
1️⃣ 选择用于生成向量嵌入的机器学习模型。
2️⃣ 选择需要嵌入的数据类型(文本、图片、音频、表格等)。嵌入所使用的模型取决于数据类型。
3️⃣ 通过嵌入模型计算数据的向量表示。
4️⃣ 在存储向量嵌入的同时,附加元数据(Metadata),以便后续预筛选或后筛选 ANN 搜索结果。
5️⃣ 向量数据库会分别索引向量嵌入和元数据。创建向量索引的方法包括:
-
随机投影(Random Projection)
-
产品量化(Product Quantization)
-
局部敏感哈希(Locality-sensitive Hashing, LSH)
6️⃣ 存储数据时,向量嵌入、索引和元数据会关联在一起,以便高效查询。
读取数据
7️⃣ 查询向量数据库时,通常包含两部分:
-
➡️ ANN 搜索数据:例如,一张图片用于寻找相似图片。
-
➡️ 元数据筛选:例如,搜索相似的公寓图片时,排除特定位置的公寓。
8️⃣ 执行元数据查询,它可以在 ANN 搜索之前或之后进行。
9️⃣ 使用与写入数据时相同的模型,将查询数据转换为嵌入向量。
🔟 执行ANN 搜索,返回最相似的向量嵌入。常见的相似性度量包括:
-
余弦相似度(Cosine Similarity)
-
欧几里得距离(Euclidean Distance)
-
点积(Dot Product)
https://x.com/Aurimas_Gr/status/1905604082644951401
(文:PyTorch研习社)