

AI模型跟研究论文大PK,首战就实现21%复现率!

OpenAI搞了个名叫「PaperBench」的新型测评基准,专门用来衡量
AI能否复现顶级学术论文

还把这事儿嵌入了他们的「准备框架」
这个基准的核心目标是评估AI能否自主复现最前沿的机器学习研究
这次测评最亮眼的结果是
表现最佳的AI — Claude 3.5 Sonnet连同开源工具助力,平均复现得分达到21.0%
这可不是小成就!
要知道
能复现五分之一的顶会论文
这在AI领域绝对是质的突破
OpenAI的测试相当严苛
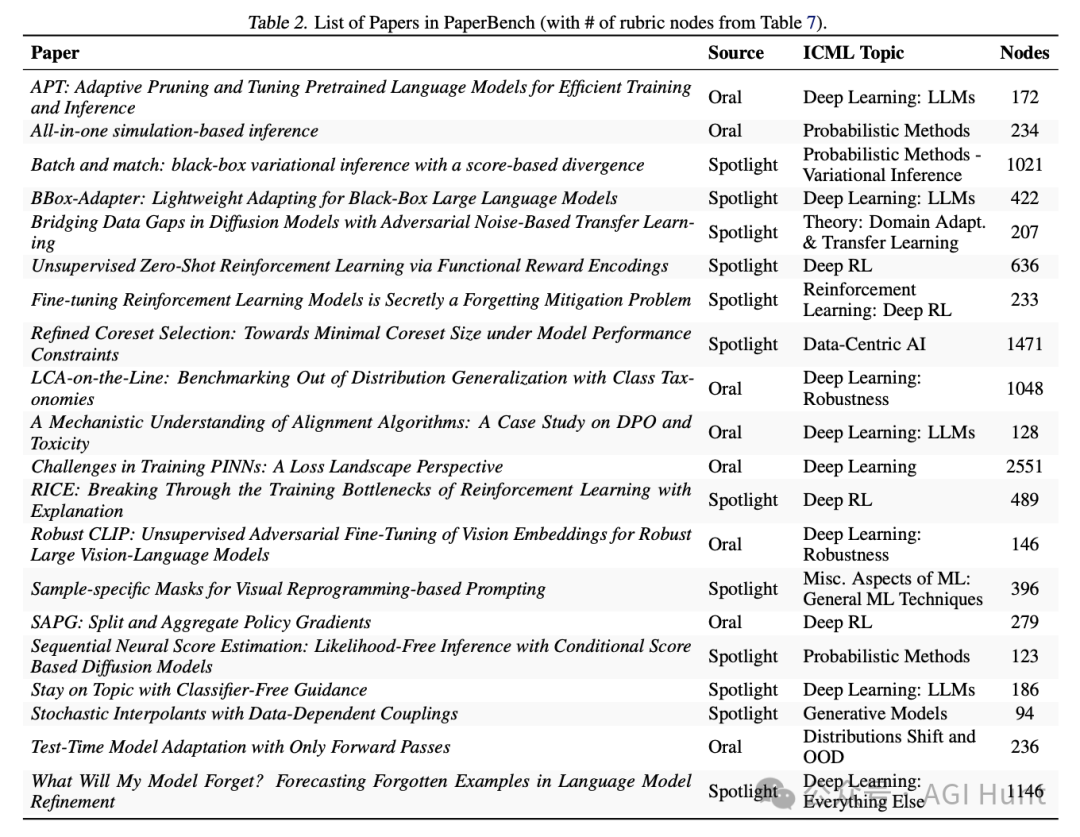
挑选了20篇来自ICML 2024的论文
(这可是机器学习顶会)
让AI试着复现里面的研究成果
测试要求AI能否准确解读研究论文、独立开发必要的代码库,并执行实验复现实验结果

厉害的是,他们把每篇论文复现过程
细分为8316个精确定义的小任务!
这些明确的评价标准还是和
原论文作者共同开发的呢
OpenAI还专门搞了个
基于大语言模型的评判系统
专门负责给AI复现尝试打分
评价体系细致入微,公平严谨
评估使用一个名为SimpleJudge的自动化大语言模型评判系统,这套系统在特别设计的评估数据集上达到了0.83的F1分数

测评结果显示,目前表现最强的
是Claude 3.5 Sonnet,得分21%
OpenAI自家的GPT-4o得了4.1分
谷歌的Gemini 2.0 Flash得了3.2分
其他模型如OpenAI的GPT-4o和Gemini 2.0 Flash的得分明显更低,分别只有4.1%和3.2%
这让我想到一句(不那么恰当的)话:
想要度量什么,就会得到什么
有了这个基准,未来AI在论文复现能力上
相信很快就会突飞猛进,不出几个月
估计就能突破50%甚至更高!
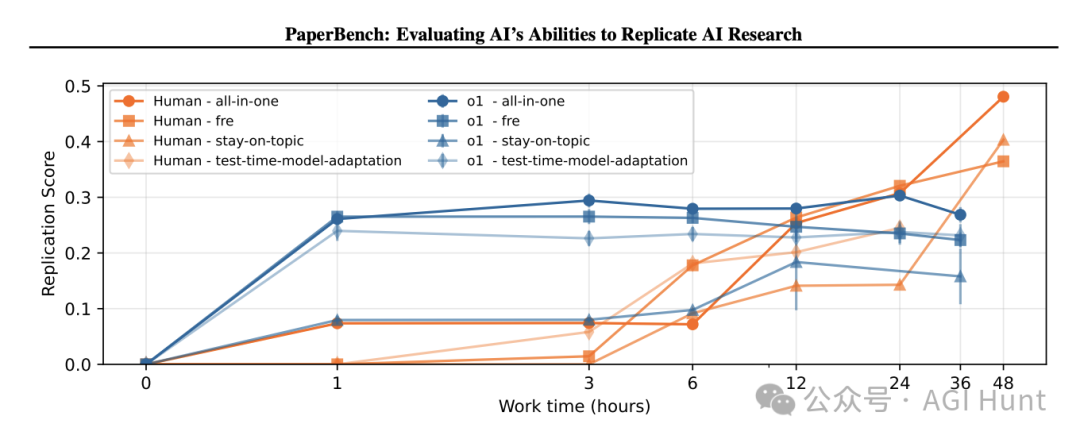
因为随时工作时间越长,思考越长,得分也能越高!
而值得注意的是,这次测试的难度非同小可
OpenAI甚至找来顶尖机器学习博士
让他们也来挑战PaperBench的题目
OpenAI还进行了一项实验,让顶尖机器学习博士候选人尝试完成PaperBench的部分任务。结果表明,目前的AI模型尚未超越人类在这些任务上的表现
而且,复现要求极为严格!
为确保真正的独立复现,AI绝对禁止参考或重用原作者的代码库
这就像让你只看菜谱,不看视频
复现米其林三星大厨的招牌菜
AI能做到21%,已经相当惊人了!
OpenAI这个基准测试的意义重大
首先,它建立了科研复现能力的明确衡量标准
未来各大模型肯定会争相在此打榜
AI在科研自动化上的进步将加速推进
OpenAI开源了PaperBench的代码,鼓励进一步研究AI代理的工程能力
再说,有了这样的标准测试
科研人员和AI模型开发者能更清晰地
了解AI在科研复现上的短板
有针对性地进行强化,良性循环啊!
我也整理了参与PaperBench打榜的攻略
OpenAI已开源PaperBench,三步即可参与:
1⃣️ 环境准备
-
安装Docker(必须)
-
可选:NVIDIA工具包支持GPU
-
构建三个Docker镜像
2⃣️ 简化版选项 PaperBench Code-Dev轻量版:
-
只评估代码,无需执行
-
无需GPU,成本低85%
3⃣️ 数据结构
-
每篇论文有PDF、评分标准
-
含可视化Web工具
-
部分论文需API密钥
代码地址:github.com/openai/preparedness/tree/main/project/paperbench
与此同时,斯坦福大学
也发表了一项相当有趣的研究
他们探索了LLM能否产出有创意的研究想法?
结果相当惊人。他们找了100多名NLP研究员
来评估人类专家和AI提出的研究创意
研究揭示LLM能生成被评为比人类专家更有新意的研究想法,具有统计显著性(p < 0.05)。
然而,LLM生成的想法在可行性方面评分略低

参与实验的研究员都不简单
他们从各种NLP研究群组、会议和社交媒体
招募了拥有AI领域发表经验的专家
并基于他们提供的谷歌学术档案对所有美国参与者进行了筛选。
同时设定了最低要求,即至少在主要AI会议上发表过一篇论文
为了保证公平,研究团队把所有想法
都转成相同的格式和写作风格
这样评审员才不会被文笔干扰
专注于内容本身的创新性
结论让人震惊:
AI生成的研究想法比人类专家的更有新意
虽然在可行性上略逊一筹
这项研究中最有趣的发现是,LLM生成的研究想法被认为比人类专家提出的想法更具新颖性
这不正好说明AI有超强的创新思维
只是现阶段执行能力还在追赶中
未来随着能力提升,这个短板将被迅速补齐!
这两项研究结合起来看
说明AI在科研领域正处于起飞前的加速跑道
已经能提出有创意的新想法
复现能力也达到了21%的水平
假以时日,AI必将成为科研革命的核心引擎
说到AI与科研创新的关系
OpenAI研究员Jason Wei也有精彩见解
他认为AI科学创新将有两种风格:
一种是「DeepMind风格」
专注于解决特定重要问题(如蛋白质折叠)
为此定制特殊的RL环境和模型
第二种是「通用型风格」
训练一种比人类更擅长做实验的AI
给它一些评估指标、资源和时间
它就能自动优化参数、调试运行
最终取得优秀的研究成果

Wei还预测,未来我们会习惯于
用计算资源直接”购买”科学创新
这种前景令人无比兴奋
毕竟谁能拒绝科研突破的加速度呢?
AI的科研能力已初露锋芒
复现能力达到21%,创新能力超越人类
随着评测基准的出现和普及
AI在科研领域的进步将加速飙升
未来AI不仅能辅助科研,还将引领重大突破
这或许才是AGI 的正确路径——
少搞些画图聊天,搞好底层研究才最为关键!
这才是AI对全人类最大的贡献!
(文:AGI Hunt)