
“ 大模型由于其快速迭代的原因,因此大模型分类存在很多困难;而作为大模型应用的使用者和开发者我们需要做的就是不断去尝试和体验模型的功能。”
大模型技术发展到今天,其功能可以说是日新月异;并且很多企业已经在探索大模型的应用场景和技术实现;但是很多人到现在对大模型的了解仅仅只限于能聊个天,问个问题。
但实际上,大模型能够做的事要远比我们想象中的要多的多;因此,今天我们就从用户和技术两个角度来介绍一下大模型的应用。
关于大模型的分类和应用问题
如果想弄清楚大模型是怎么使用的,首先要知道大模型的分类;不同类型的模型适合不同的应用场景,其功能和实现也各不相同。
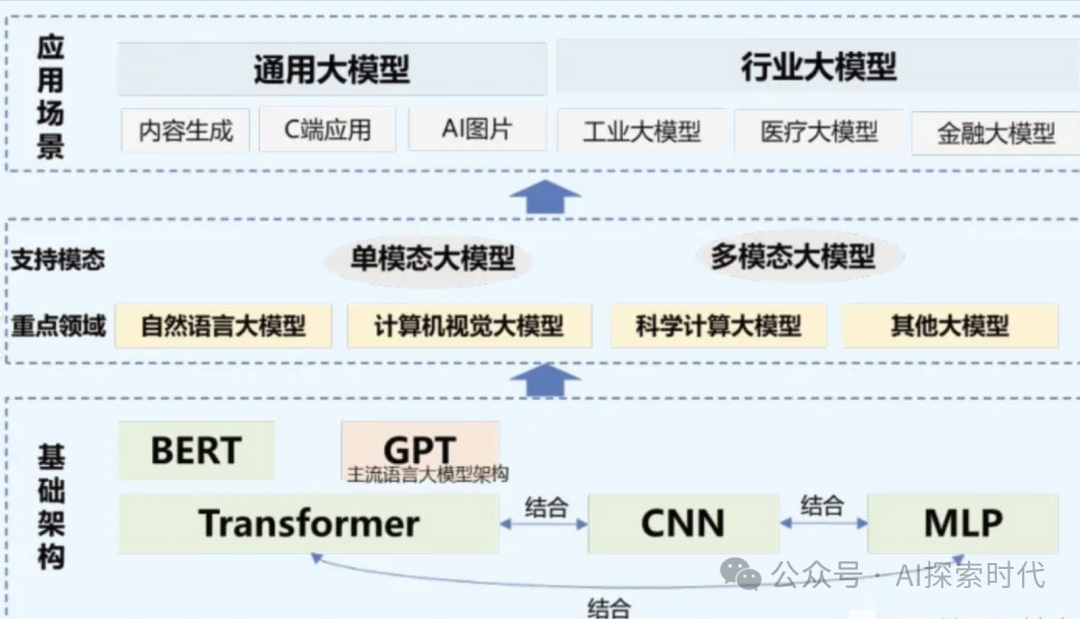
而关于大模型的分类问题其实是一个复杂的问题,大模型的分类有多个维度,比如从任务类型有分类模型,翻译模型,摘要模型和文本生成等。
但从与具体的技术场景结合来看,又有NLP任务,CV任务等;而从功能来看又有生成式模型和推理模型;从垂直角度看,有处理图片的模型,有写代码的模型;如果从纯粹的技术角度来看,又有Transformer模型,Gan网络等。
而在实际的模型设计和开发过程中,很多模型采用的又是混合架构;比如说一个模型既有生成能力,又有推理能力,而能够生成多种模态数据的模型被称为多模态。
再加上大模型技术日新月异的迭代速度,因此很多人很难分清哪个模型是干啥的,有哪些功能;因此在选择模型时,最好就是根据自己的任务需求去搜索相关的模型,最后再根据模型的官方介绍,然后再应用到具体的业务场景中。
大模型分类困难的四大根源
-
技术融合
-
现代大模型(如GPT-4、Claude 3)已发展为「通用计算平台」,同时具备:
-
生成能力(文本/图像/代码)
-
推理能力(数学/逻辑)
-
判别能力(分类/检测)
-
多模态理解(文本+图像+音频)
2. 命名混乱
-
商业命名(如”文心一言”)不反映技术架构
-
同一架构不同规模(LLaMA-2-7B/13B/70B)能力差异巨大
3. 动态进化
-
插件系统的引入(如ChatGPT的Browsing/Code Interpreter)使单模型能力边界模糊
4. 评估标准缺失
-
缺乏统一的「能力维度评估体系」,不同厂商宣传指标不可比
理解大模型分类的本质是:放弃绝对分类,建立多维评估体系。建议从实际任务出发进行验证,而非过度依赖理论分类。
前面简单了解了一下大模型的分类问题,但仅仅知道大模型有哪些类型并没什么用,最重要的是用大模型解决我们的问题;以此来提高我们的工作和生活效率。
所以,学习大模型没有最好的办法,或者说办法只有一个;那就是多用,多尝试,多研究。
大模型应用
大模型其实从应用的角度来说,主要有三个方面:
第一就是利用大模型本身的能力,比如AIGC去做一些文本,视频,图片的生成能力;比如做自媒体,写文章,修图,剪辑视频等。
其次,就是RAG给大模型做知识增强,因为大模型本身限制的原因;导致其在某些方面知识缺陷,因此就可以使用外部知识库的方式让大模型做知识增强。
最后,可以说是最有发展前景的方向就是——智能体;智能体就是给大模型装上手和脚,通过思维链,工作流,function call/MCP等技术;使得大模型具备独立思考和使用外部工具的能力。
当然,这三种方式大都是从技术角度来说的;但从用户角度来说,我们可以使用一些生成模型做一些简单的工作,如处理图片,写文档等。
而一些企业基于工作流平台开发智能体,比如coze平台;我们就可以根据自己的需要构建一个能够执行特定任务的智能体;以此来提高我们的工作效率。
总之,人工智能技术处于一个快速发展快速迭代的过程;很多新技术和名词每天都在涌现;因此,我们需要做的就是不断跟进市场的脚步,多去尝试和试验;最终我们就会知道大模型能做什么,以及我们需要大模型给我们做什么。
(文:AI探索时代)