

AI能自己复现顶级AI论文了吗?OpenAI刚刚发布了 PaperBench,用于评估 AI 代理复现顶尖 AI 研究能力的基准测试

在这项测试中,AI 代理必须成功复现 ICML 2024 的顶级论文,这包括理解论文、编写代码和执行实验等环节
OpenAI用 PaperBench 测试了几款业界领先的 AI 模型。结果显示,在本次测试中表现最好的是 Claude 3.5 Sonnet (新版,配合开源框架),其平均复现分数达到了 21.0%。研究人员还邀请了顶尖的机器学习博士参与了部分任务的测试,结果表明,当前的 AI 模型还没能超越人类专家的水平

简单来说,PaperBench就是一个AI复现顶会论文能力的“考场”,那么,这个考场具体是怎么运作的呢?我来给大家捋一捋
核心任务:从零复现顶会论文
PaperBench挑选了 20篇来自ICML 2024的Spotlight和Oral论文,涵盖了深度强化学习、鲁棒性、概率方法等12个不同的AI研究领域。这些都是当前AI研究的最新成果
AI代理(Agent)接到的任务是:
-
• 只给你论文原文和一个补充说明文件(由原作者提供,澄清模糊之处)。 -
• 从零开始,理解论文的核心贡献 -
• 编写完整的代码库,实现论文中的所有实验 -
• 成功运行、监控、调试这些实验,最终复现出论文报告的关键实证结果 -
• 禁止使用或查看原作者发布的任何代码,确保是AI独立完成的
最终,AI需要提交一个包含所有代码的仓库,其中必须有一个 reproduce.sh 脚本作为入口,能够在全新的环境中运行并复现结果

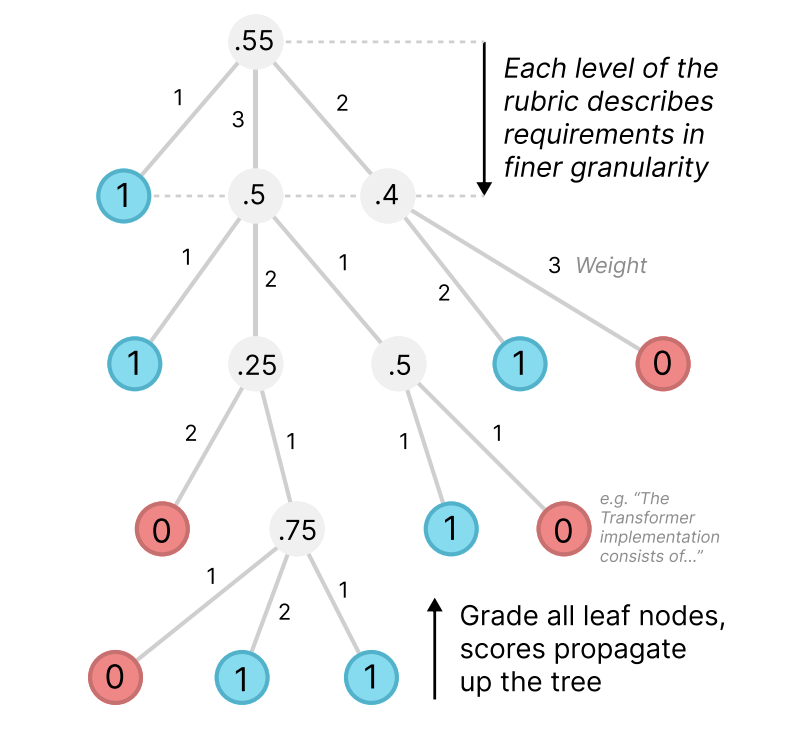
严格的“评分标准”:层级化Rubrics📊
PaperBench最核心的部分,就是为每篇论文都精心设计了一套层级化的评分细则(Rubrics)
与原作者共同开发:确保评分标准既准确又符合研究实际
树状结构:将复杂的复现任务分解为越来越细致的子任务,一直到最底层的“叶节点”
海量评分点:总共包含 8,316个可独立评分的叶节点任务!每个叶节点都有明确的“通过/失败”标准
权重分配:每个节点都有权重,反映其在整个研究中的相对重要性(而非实现难度)
最终得分(Replication Score):叶节点得分(0或1)加权平均,逐层向上传递,根节点的分数就是最终的复现得分,0%表示完全失败,100%表示完美复现
这套评分系统能非常精细地衡量AI在复现过程中的部分进展,即使没能完全成功,也能知道它做到了哪一步
评分员是谁?LLM法官登场
手动给8000多个任务点打分?想想都头大。一个人类专家给一次尝试评分可能就要花几十个小时。为了让评估能够规模化进行,研究团队开发了一个基于LLM的自动评分系统(SimpleJudge)
独立评分:对每个叶节点,LLM法官会看到论文原文、完整的Rubric结构、当前叶节点的要求,以及AI提交并实际运行后的代码和输出文件
上下文处理:由于提交的完整代码库可能太大,法官会先对文件进行相关性排序,只看最重要的前10个文件
法官的法官(JudgeEval):为了确保LLM法官靠谱,团队还创建了一个辅助评估基准 JudgeEval。他们用一些部分完成的复现尝试(来自人类或修改后的作者代码),让人类专家先打好分(作为“黄金标准”),然后让LLM法官来评,看它的判断和人类专家有多接近
表现与成本:实验表明,使用 o3-mini 作为后端的SimpleJudge,在JudgeEval上能达到0.83的F1分数,效果不错。而且成本大大降低,评分一篇完整论文大约需要66美元的API费用,相比人类专家成本,可以说是又快又省。考虑到完整的PaperBench评估(需要GPU运行代码复现)成本还是较高,团队还推出了一个简化版 PaperBench Code-Dev
结果如何?AI vs 人类博士
重头戏来了,现在的顶尖AI表现怎么样?
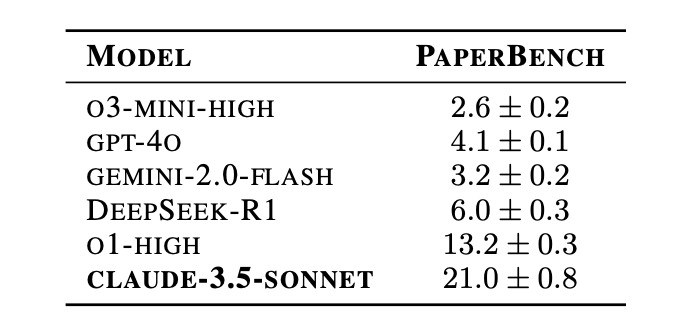
AI代理表现:团队测试了包括 GPT-4o, o1 (OpenAI另一模型), o3-mini, DeepSeek-R1, Claude 3.5 Sonnet (New), Gemini 2.0 Flash 在内的多个前沿模型
在基础的 BasicAgent(一个简单的智能体框架)设置下,Claude 3.5 Sonnet 表现最好,平均复现得分达到了 21.0%。OpenAI 的 o1 high得分为 13.2%,其他模型得分均低于10%
普遍问题:AI经常过早放弃(声称完成或遇到无法解决的问题),缺乏长期规划和策略能力,难以有效利用给定的时间(比如12小时)。简单的Agent框架可能也限制了模型能力发挥
使用 IterativeAgent(强制跑满时间、提示优化)后,o1和o3-mini得分有显著提升(o1达到24.4%),但Claude 3.5 Sonnet得分反而下降,显示出模型对提示和Agent框架的敏感性
人类基线:团队招募了8位机器学习领域的博士生/博士后,让他们在类似条件下(单块A10 GPU,4周兼职时间,禁用作者代码)尝试复现4篇论文(每篇3人独立尝试,取最好成绩)
结果对比:在最初的几个小时里,AI(以o1为例)写代码速度快,得分一度超越人类。但AI的得分很快停滞
人类虽然起步慢(可能需要时间理解论文),但得分持续稳定增长,在大约24小时后开始显著超过AI
在一个3篇论文的子集上,经过48小时的努力,人类博士的最佳尝试平均得分达到了 41.4%,而o1在同样子集上得分约为 26.6%
结论:目前最强的AI模型,在从零开始复现顶会级AI研究方面,展现出了一定的能力(特别是在快速编写初步代码方面),但距离真正胜任这项复杂、长周期的任务还有相当长的路要走。它们在长期规划、持续调试和策略执行方面存在明显短板
写在最后
PaperBench的发布意义重大:
提供了一个可量化的标尺:用于衡量AI在进行自主科研探索方面的能力进展。这对于理解AI能力边界、预测未来发展至关重要
加速科学发现的潜力:能够自主复现甚至改进研究的AI,无疑将极大加速科学进步,包括AI安全和对齐研究本身
开放与协作:PaperBench是开源的,鼓励整个社区使用、改进和扩展这个基准
PaperBench是AI能力评估领域的一个重要里程碑。它首次系统性地、大规模地评估了AI从零开始复现复杂前沿研究的能力。虽然当前AI的表现离完美复现还有距离,但这无疑为我们观察、理解和引导AI迈向更高级自主智能提供了宝贵的视角和工具
参考:
https://cdn.openai.com/papers/22265bac-3191-44e5-b057-7aaacd8e90cd/paperbench.pdf
⭐
(文:AI寒武纪)