


想象一下,一座生机勃勃的 3D 城市在你眼前瞬间成型 —— 没有漫长的计算,没有庞大的存储需求,只有极速的生成和惊人的细节。
然而,现实却远非如此。现有的 3D 城市生成方法,如基于 NeRF 的 CityDreamer [1],虽然能够生成逼真的城市场景,但渲染速度较慢,难以满足游戏、虚拟现实和自动驾驶模拟对实时性的需求。而自动驾驶的 World Models [2],本应在虚拟城市中训练 AI 驾驶员,却因无法保持多视角一致性而步履维艰。
现在,新加坡南洋理工大学 S-Lab 的研究者们提出了 GaussianCity,该工作重新定义了无界 3D 城市生成,让它变得 60 倍更快。过去,你需要数小时才能渲染一片城区,现在,仅需一次前向传播,一座完整的 3D 城市便跃然眼前。无论是游戏开发者、电影制作者,还是自动驾驶研究者,GaussianCity 都能让他们以秒级的速度构建世界。
城市不该等待生成,未来应该即刻抵达。

-
Paper:https://arxiv.org/abs/2406.06526
-
Code:https://github.com/hzxie/GaussianCity
-
Project Page:https://haozhexie.com/project/gaussian-city
-
Live Demo: https://huggingface.co/spaces/hzxie/gaussian-city
引言
3D 城市生成的探索正面临着一个关键挑战:如何在无限扩展的城市场景中实现高效渲染与逼真细节的兼得?现有基于 NeRF 的方法虽能生成细腻的城市景观,但其计算成本极高,难以满足大规模、实时生成的需求。近年来,3D Gaussian Splatting(3D-GS)[3] 凭借其极高的渲染速度和优异的细节表现,成为对象级 3D 生成的新宠。然而,当尝试将 3D-GS 扩展至无界 3D 城市时,面临了存储瓶颈和内存爆炸的问题:数十亿个高斯点的计算需求轻易耗尽上百 GB 的显存,使得城市级别的 3D-GS 生成几乎无法实现。
为了解决这一难题,GaussianCity 应运而生,首个用于无边界 3D 城市生成的生成式 3D Gaussian Splatting 框架。它的贡献可以被归纳为:
-
通过创新性的 BEV-Point 表示,它将 3D 城市的复杂信息高度压缩,使得显存占用不再随场景规模增长,从而避免了 3D-GS 中的内存瓶颈。
-
借助空间感知 BEV-Point 解码器,它能够精准推测 3D 高斯属性,高效生成复杂城市结构。
-
实验表明,GaussianCity 不仅在街景视角和无人机视角下实现了更高质量的 3D 城市生成,还在推理速度上比 CityDreamer 快 60 倍,大幅提高了生成效率。
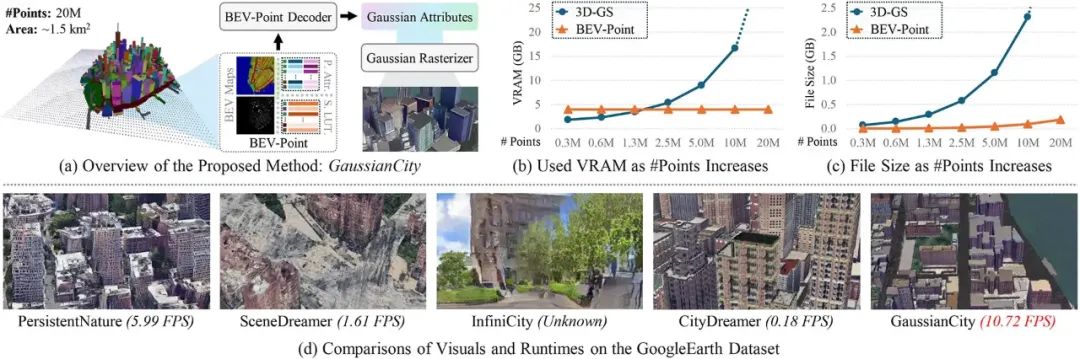
具体来说,得益于 BEV-Point 的紧凑表示,GaussianCity 可以在生成无界 3D 城市时保持显存占用的恒定,而传统 3D-GS 方法在点数增加时显存使用大幅上升(如下图(b)所示)。同时,BEV-Point 在文件存储增长上也远远低于传统方法(如下图(c)所示)。不仅如此,GaussianCity 在生成质量和效率上都优于现有的 3D 城市生成方法,展现了其在大规模 3D 城市合成中的巨大潜力(如下图(d)所示)。
方法
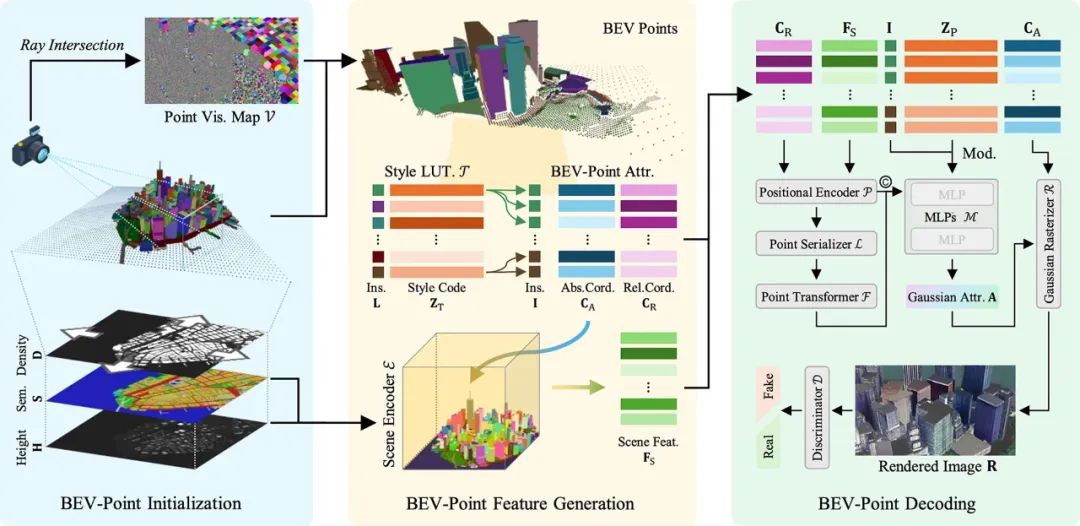
如上图所示,GaussianCity 将 3D 城市生成过程分为三个主要阶段:BEV-Point的初始化、特征生成和解码。
BEV-Point 初始化
在 3D-GS 中,所有 3D 高斯点在优化过程中都会使用一组预定义的参数进行初始化。然而,随着场景规模的增加,显存需求急剧上升,导致生成大规模场景变得不可行。为此,GaussianCity 采用 BEV-Point 进行优化,以缓解这一问题。
BEV 图 是生成 BEV-Point 的基础,包含三个核心图像:高度图(Height Map)、语义图(Semantic Map)和 密度图(Density Map)。从 BEV 图 中,BEV-Point 被生成:
-
高度图 决定每个点在空间中的 3D 坐标。
-
语义图 提供每个点的语义标签,如建筑、道路等。
-
密度图 调整采样密度,根据不同区域的特征决定是否增加或减少采样点。
BEV-Point 通过只保留可见点大幅减少计算量。由于相机视角固定,场景中不可见的点不影响渲染结果,因而不占用显存。这样,随着场景扩展,显存使用量保持恒定。
为了优化计算,二值密度图根据语义类别调整采样密度。对于简单纹理(如道路、水域)减少密度,复杂纹理(如建筑物)则增加密度。
通过射线交点(Ray Intersection)方法筛选出可见的 BEV-Point,确保仅这些点参与后续渲染和优化,进一步提升计算效率。
BEV-Point 特征生成
在 BEV-Point 表示中,特征可分为三大类:实例属性、BEV-Point 属性和样式查找表。
1.实例属性
实例属性包括每个实例的基本信息,如实例标签、大小和中心坐标等。语义图提供了每个 BEV 点的语义标签。为了处理城市环境中建筑物和车辆的多样性,引入了实例图来区分不同的实例。通过检测连接组件(Connected Components)的方式,将语义图进行实例化,从而得到每个实例的标签、大小和边界框的中心坐标。
2.BEV-Point 属性
在 BEV-Point 初始化时,生成了每个点的绝对坐标,并设定其原点在世界坐标系的中心。为了更精确地描述每个实例的相对位置,相对坐标系被引入。其原点设置在每个实例的中心,并通过标准化的方式来计算相对坐标。
为了融入更多的上下文信息,场景特征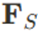 从 BEV 图中提取,并通过点的绝对坐标进行索引,进一步为每个 BEV 点提供更丰富的上下文信息。
从 BEV 图中提取,并通过点的绝对坐标进行索引,进一步为每个 BEV 点提供更丰富的上下文信息。
3.样式查找表(Style Look-up Table)
在 3D-GS 中,每个 3D 高斯点的外观都由其自身的属性决定,导致存储开销随着高斯点数量的增加而显著增长,使得大规模场景的生成变得不可行。为了解决这一问题,BEV-Point 采用隐向量(Latent Vector)来编码实例的外观,使得相同的实例共享同一个隐向量,并通过样式查找表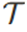 为不同实例分配样式,从而减少计算与存储开销。
为不同实例分配样式,从而减少计算与存储开销。
BEV-Point 解码
BEV-Point 解码器用于从 BEV-Point 特征生成高斯点属性,主要包括五个模块:位置编码器、点序列化器、Point Transformer、Modulated MLPs、以及高斯光栅化器。
1.位置编码器(Positional Encoder)
为了更好地表达空间信息,BEV-Point 坐标和特征不会直接输入网络,而是经过位置编码转换为高维嵌入,从而提供更丰富的表征能力。
2.点序列化器(Point Serializer)
BEV-Point 是无序点云,直接用 MLP 可能无法充分利用其结构信息。因此,我们引入点序列化方法,将点坐标转换为整数索引,使相邻点在数据结构中更具空间连续性,优化信息组织方式。
3.Point Transformer
序列化后的点特征经过 Point Transformer V3 [10] 进一步提取上下文信息,增强 BEV-Point 的全局和局部关系建模能力。
4.Modulated MLPs
在生成 3D 高斯点属性时,MLP 结合 BEV-Point 特征、Point Transformer 提取的特征、实例的样式编码及标签,以确保生成的高斯点具有一致的外观和风格。
5.高斯光栅化器(Gaussian Rasterizer)
最终,结合相机参数,BEV-Point 生成的 3D 高斯点属性通过高斯光栅化器进行渲染。对于未生成的某些属性,如尺度、旋转、透明度,则使用默认值填充。
实验
下图展示了 GaussianCity 和其他 SOTA 方法的对比,这些方法包括 PersistentNature [4]、SceneDreamer [5] 、InfiniCity [6] 和 CityDreamer [1]。实验结果表明,GaussianCity 的效果明显优于其他方法,相比于 CityDreamer 更是取得了 60 倍的加速。

在街景图生成上,GaussianCity 在 KITTI-360 [7] 数据集上进行训练,其生成效果超越了 GSN [8] 和 UrbanGIRAFFE [9] 等多种方法。

总结
本研究提出了 GaussianCity,首个针对无边界 3D 城市生成的生成式 3D Gaussian Splatting 框架。通过引入创新性的 BEV-Point 表示,GaussianCity 在保证高效生成的同时,克服了传统 3D-GS 方法在大规模场景生成中面临的显存瓶颈和存储挑战。该方法不仅实现了在街景和无人机视角下的高质量城市生成,还在推理速度上相比 CityDreamer 提升了 60 倍,显著提高了生成效率。实验结果表明,GaussianCity 能够在确保细节还原的同时,高效处理无边界 3D 城市生成,为大规模虚拟城市的实时合成开辟了新路径。
参考文献
[1] CityDreamer: Compositional Generative Model of Unbounded 3D Cities. CVPR 2024.
[2] A Survey of World Models for Autonomous Driving. arXiv 2501.11260.
[3] 3D Gaussian Splatting for Real-Time Radiance Field Rendering. SIGGRAPH 2023.
[4] Persistent Nature: A Generative Model of Unbounded 3D Worlds. CVPR 2023.
[5] SceneDreamer: Unbounded 3D Scene Generation from 2D Image Collections. TPAMI 2023.
[6] InfiniCity: Infinite-Scale City Synthesis. ICCV 2023.
[7] KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D. TPAMI 2023.
[8] Unconstrained Scene Generation with Locally Conditioned Radiance Fields. ICCV 2021.
[9] UrbanGIRAFFE: Representing Urban Scenes as Compositional Generative Neural Feature Fields. ICCV 2023.
[10] Point Transformer V3: Simpler, Faster, Stronger. CVPR 2024.
©
(文:机器之心)