

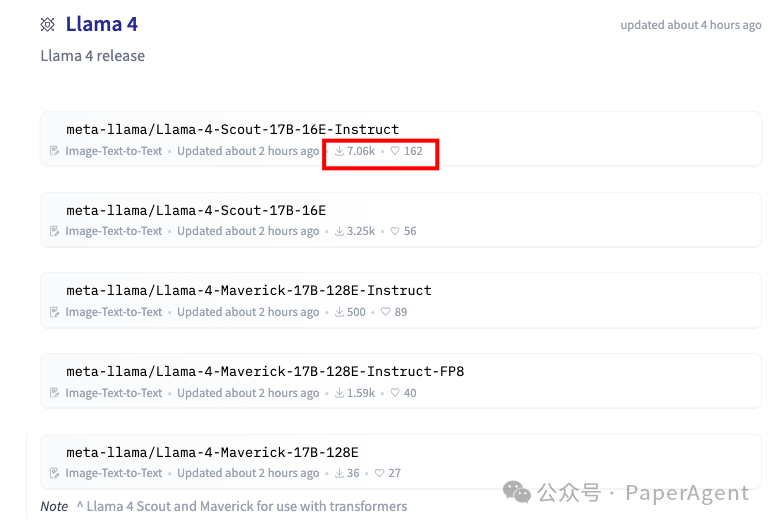
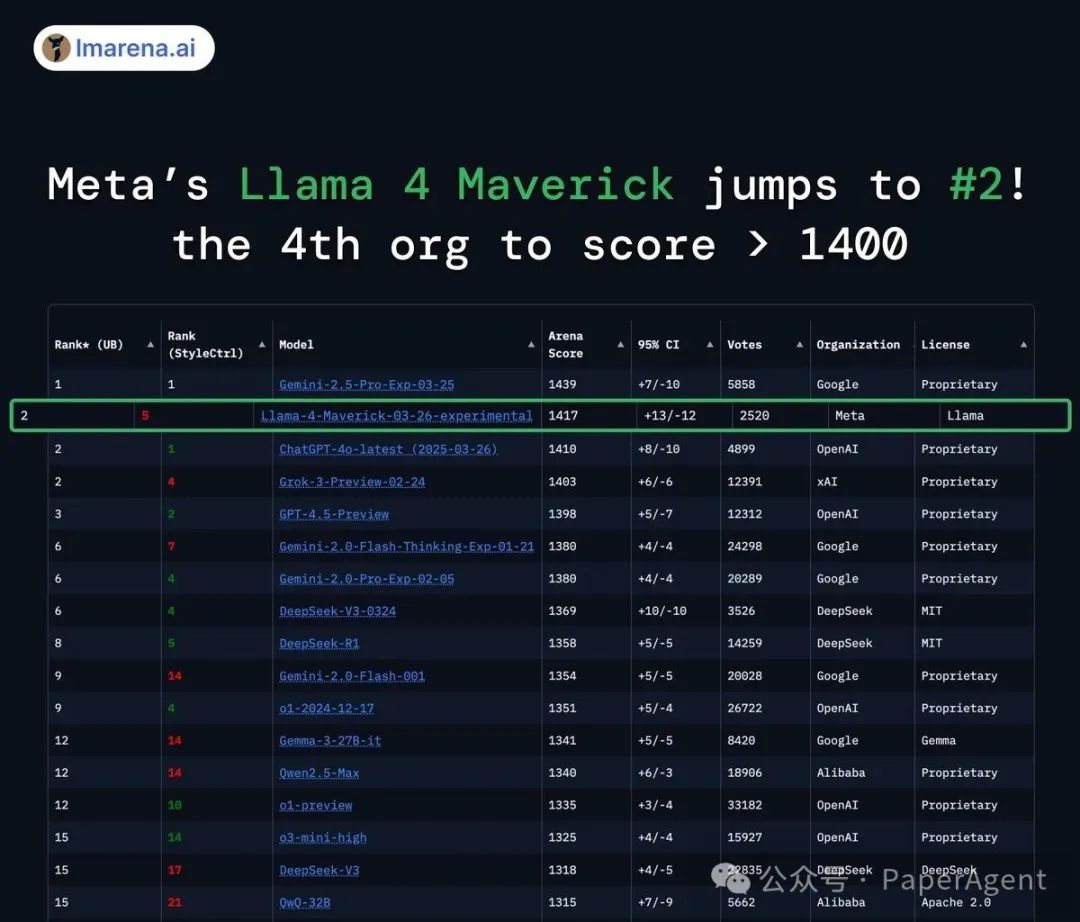
-
Llama 4 Behemoth(未开源):288B 活跃参数,16个专家,总参数量2T,最智能的蒸馏教师模型
-
Llama 4 Maverick:17B活跃参数,128个专家,总参数量400B,原生多模态支持1M上下文长度
-
Llama 4 Scout:7B活跃参数,16个专家,总参数量109B,行业领先的10M上下文长度,优化推理

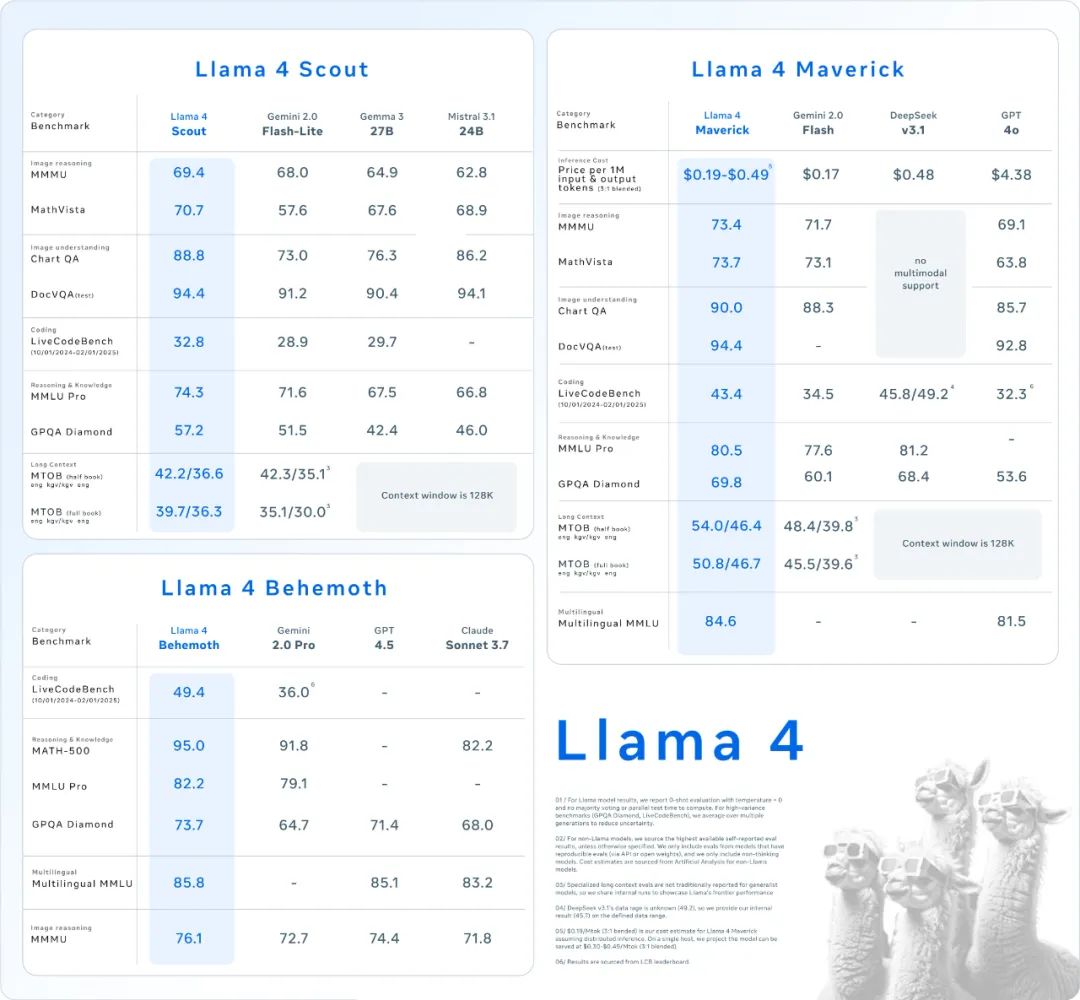
-
原生多模态:能够无缝集成文本和视觉token到统一的模型骨干中,实现文本和图像数据的早期融合。
-
智能调参 MetaP:用于智能调整训练超参数的新技术,这可能类似于 Meta 开源的 Ax 框架中的贝叶斯优化,能在有限的试验预算内进行自适应实验(如 A/B 测试)
-
后训练策略:重 RL 轻 SFT/DPO,提升在线 RL 的权重。过多的 SFT/DPO 会过度约束模型,限制其在 RL 阶段的探索能力
-
MoE架构:首次在 Llama 4 模型中使用混合专家架构,在训练和推理时更加计算高效,并且能够在固定的训练 FLOPs 预算下提供更高质量的结果。
https://hf-mirror.com/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164https://ai.meta.com/blog/llama-4-multimodal-intelligence/
(文:PaperAgent)