谁才是最强开源AI模型王者?Meta和DeepSeek展开了新一轮竞争。
日前,沉寂了许久的Meta宣布推出新一代旗舰模型Llama 4家族,并将其定义为原生多模态AI创新时代的开始,已发布型号为Llama 4 Scout和Llama 4 Maverick,这两个模型都是基于Llama 4 Behemoth模型提炼而成。
Meta官方称在一系列广泛接受的基准测试中均实现了领先同行的水平,尤其是Llama 4 Behemoth,在多个基准测试中的表现要优于GPT-4.5、Claude Sonnet 3.7和Gemini 2.0 Pro等一众行业顶尖封闭模型。
但发布后不久,Meta却遭到啪啪打脸,因为各路开发者实测Llama 4后发现,其真实效果并不如宣传中那么惊艳,甚至问题百出。
与此同时,有开发者质疑Meta似乎在根据相关评测基准对模型进行“量身定制”训练,所以在一些基准上的成绩虽然亮眼,但却不代表实际应用情况下的表现,存在误导性,幕后的黑料甚至也被挖了出来。
与DeepSeek发布新模型后的一致好评不同,Meta陷入了深深的舆论漩涡。
根据Meta自己公布的数据来看,Llama 4模型家族全面使用“混合专家”(MoE)架构,实力在开源领域是前所未有的强。
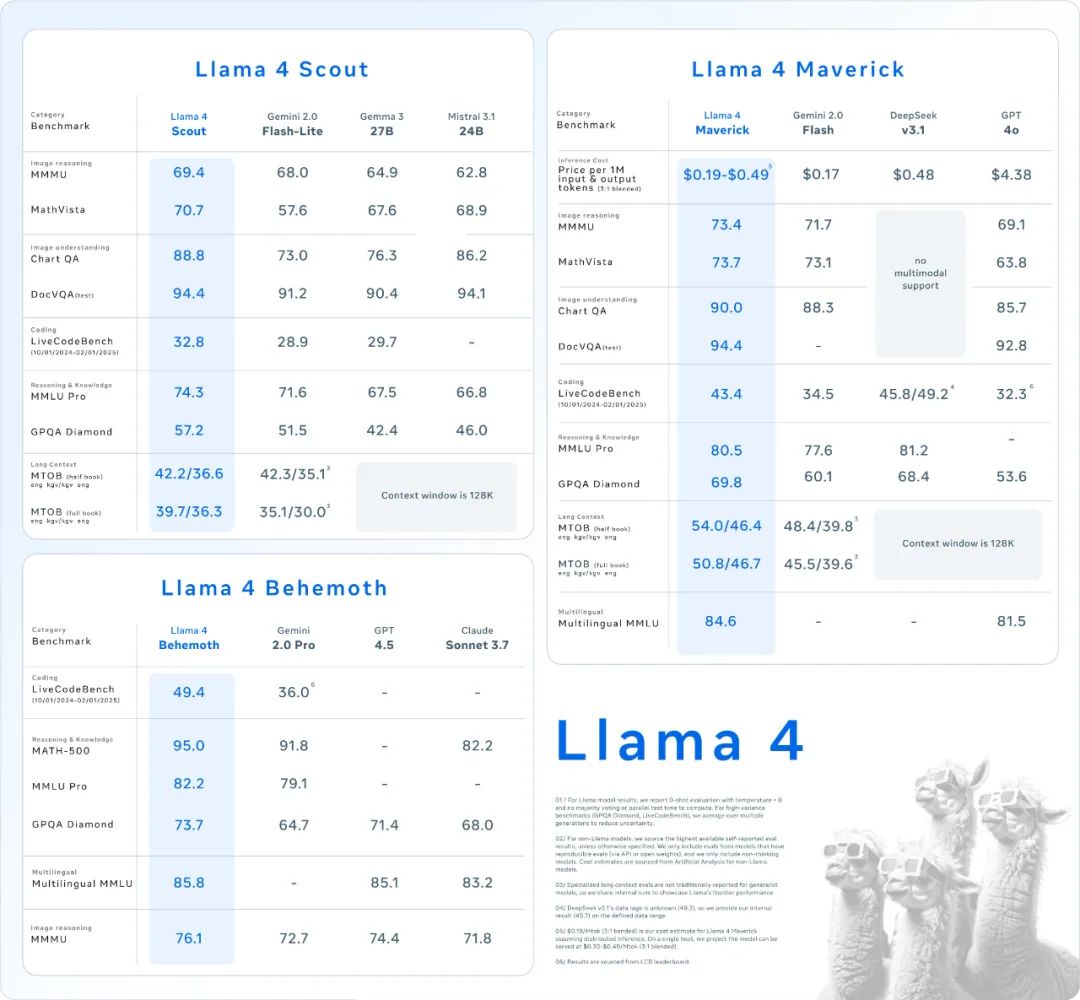
其中,Llama 4 Scout是一款拥有170亿活跃参数、16个专家模块的模型,可以在单个英伟达H100 GPU上运行,该模型提供了高达1000万(token)的超长上下文窗口,并且在众多广泛报道的基准测试中,其表现优于Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1。
Llama 4 Maverick则是一款拥有170亿活跃参数、128个专家模块的模型,在众多广泛报道的基准测试中,它的表现胜过了GPT-4o和Gemini 2.0 Flash,同时在推理和编码方面取得了与DeepSeek-V3-0324相当的成绩,其活跃参数却不到DeepSeek新v3的一半。
最强的Llama 4 Behemoth也是一个多模态专家混合模型,拥有2880亿个活动参数、16位专家和2万亿个总参数,多项基准测试性能表现均优于GPT-4.5、Claude Sonnet 3.7和Gemini 2.0 Pro。
从其官方数据上看,Meta实现了DeepSeek尚未实现的新高度。
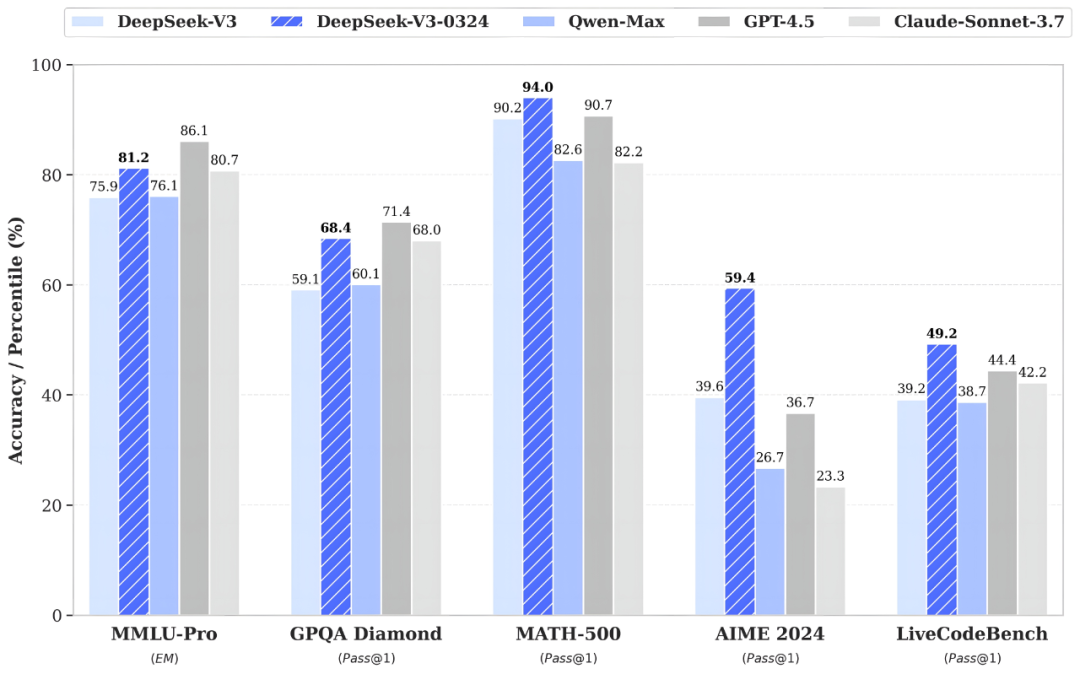
例如,在MMLU-Pro基准上,Llama 4 Behemoth实现了82.2%的成绩,DeepSeek-V3-0324为81.2%;在MATH-500基准上,Llama 4 Behemoth为95%,DeepSeek-V3-0324为94%;在LiveCodeBench基准上,Llama 4 Behemoth取得了49.4%的成绩,DeepSeek-V3-0324则为49.2%。
Llama 4取得碾压封闭模型的成绩,对于开源社区而言本来是一件可喜可贺的事,毕竟开源又一次胜利了,但在Meta没采用的一些测试基准上,却被开发者测出了截然不同的反差水平。
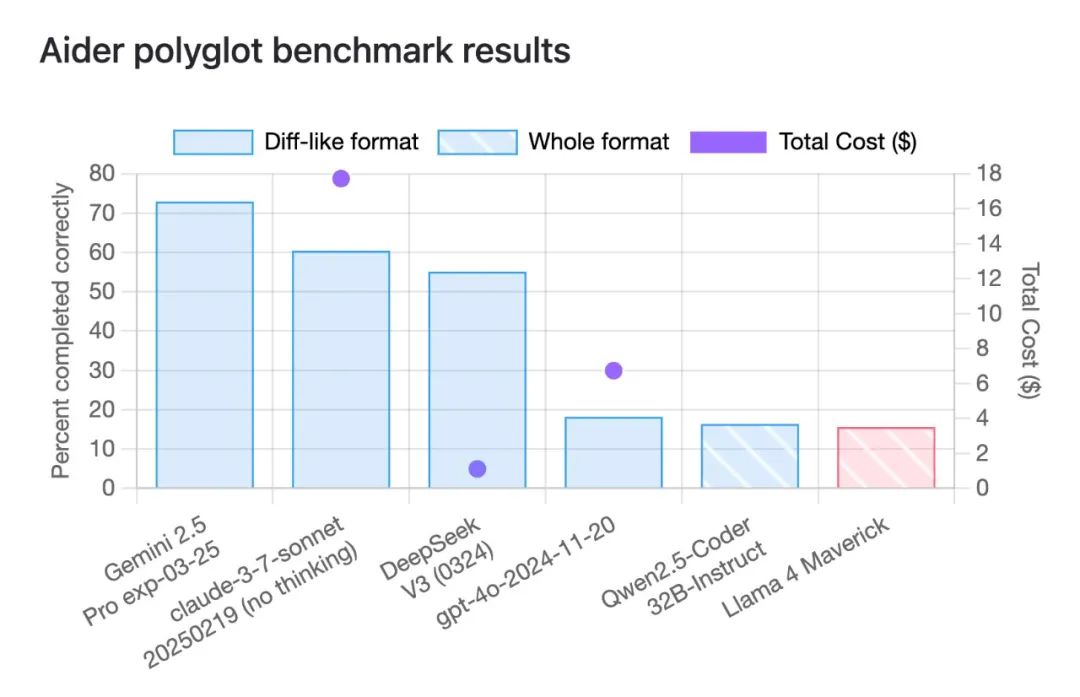
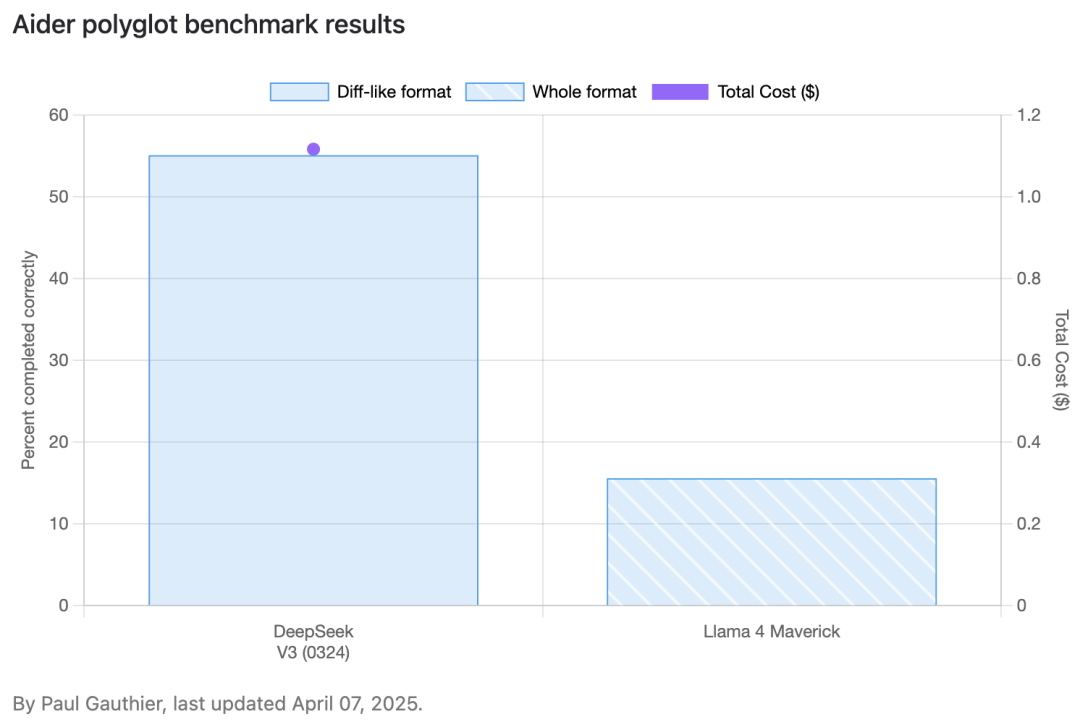
例如Meta提到Llama 4 Maverick的编码性能已经和DeepSeek-V3-0324相当,但在专门评估LLM编码能力的Aider LLM基准上,Llama 4 Maverick的实际表现却令人大失所望,只实现了15.6%的正确率,这跟DeepSeek-V3-0324实现的55.1%正确率相差甚远。
这让网友们很好奇,说好的编码性能与DeepSeek新V3相当,为何会出现如此大的差距,原因值得深思。
在各路网友的接连实测中,Llama 4系列新模型被吐槽最多的两个词是“表现不佳”和“失望”。
例如,有网友使用完全相同的提示词对其进行了测试,说好的基准测试表现胜过GPT-4o,但跟新版GPT-4o生成的流畅效果比起来差的不是一点半点,且连表现形式都是错误的。
而且在测试此类编码任务中的表现也不及Gemini 2.0、Grok 3、DeepSeek V3和Claude Sonnet 3.5/7等,整体看来,似乎比较接近老版本GPT-4o的性能水准。
网友表示,Llama 4这个表现如果放两个月前可能还行,但现在基础模型的水平已经被新V3,新4o,sonnet3.7拉得很高了,再出一个老4o/老V3水平的模型已经毫无意义,而且模型“智商”似乎也有点菜。
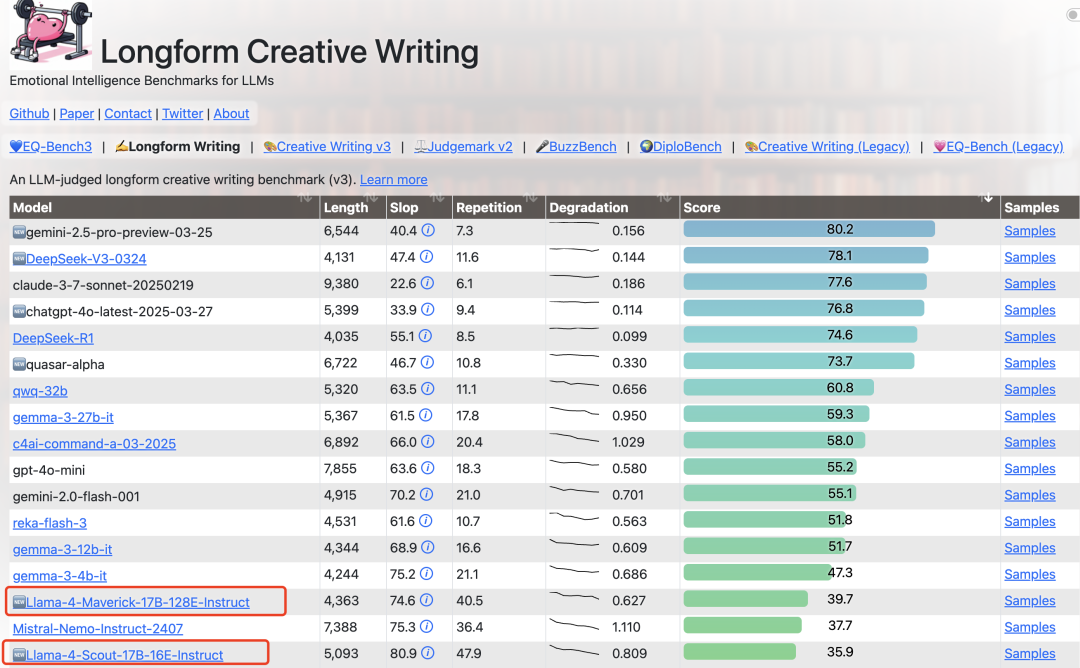
有的网友的测试感受是非常失望,差得出乎意料,402B参数模型Llama-4-Maverick在编码能力方面的表现与Qwen-QwQ-32B大致相当,而Llama-4-Scout则与Grok-2相当,该网友强烈建议不要使用Llama 4进行编码,也许值得尝试把它用于长文本翻译或其他多模态任务。
但是,即便是用于长文本人物的场景,Llama 4模型的表现依旧垫底,在大模型长篇创意写作这个考验情商的基准上,Llama 4获得的最高分是39.7,跟行业顶尖模型的差距也很大。
网友调侃,终于理解为什么Yann LeCun作为Meta的首席人工智能科学家还经常对大语言模型(LLMs)持批判态度了,因为Meta的模型做得确实很糟糕。
社交媒体上有的研究人员还观察到可公开下载的Llama 4 Maverick的表现与LM Arena测试集上托管的模型之间存在明显差异,Meta似乎是使用“针对对话性进行了优化的Llama 4 Maverick”进行测试的。
目前,LM Arena(语言模型竞技场)并不是衡量人工智能模型性能的最可靠指标,所以人工智能公司一般不会为了在LM Arena上取得更好的分数而对其模型进行定制或微调,如果为了某个基准测试来定制模型,隐瞒这一情况会使得开发人员很难准确评估该模型在特定情境下的水准。
在网友实际评测中没有逆袭DeepSeek的Meta,今天还被炸出一个大瓜。
一位自称是Meta员工的匿名网友指出,Llama4的幕后训练存在严重问题,已经向公司提交辞呈。
他指出,经过反复训练其实Meta内部模型的表现依然未能达到开源SOTA甚至与之相差甚远,所以公司领导层建议将各个benchmark的测试集混合在post-training过程中,目的是希望能够在各项指标上交差,拿出一个“看起来可以”的结果。
该网友表示,作为一名学术界的人实在无法接受这种做法,因此已经提交离职申请,并明确表示之后Llama4的Technical Report中不要署上其名字,还指出Meta的VP of AI也是因为这个原因辞职的。
虽然该说法一定程度能印证为什么Llama4在测试集和实际表现之间存在落差,不过由于是匿名爆料可信度还不够充分,也遭到了其他员工质疑,网友表示,Meta具体有没有这样暗地操作可以“让子弹再飞一会儿”。
不过,确定的消息是,Meta公司人工智能研究副总裁乔尔·皮诺 (Joelle Pineau) 日前表示将于5月底正式离职,她曾是推动Meta走“开源” 模式的代表人物之一。
Pineau的离职正值Meta加大AI投入的关键时刻,此前,扎克伯格表示在2025年计划投入高达650亿美元用于人工智能基础设施的建设,显示出对AI技术的重视和未来发展的决心。
对于Meta这次新模型发布呈现出来的诸多问题,网友们认为,如果创新能力不够,那么拥有再多的GPU和数据也毫无意义。DeepSeek、OpenAI等公司的成功表明,真正的创新才是推动人工智能发展的动力,扎克伯格不能只将巨大的资源投入到一支有问题的团队中,然后指望奇迹发生,因为AI技术的发展不仅关乎算力,也关乎智力。
(文:头部科技)