作者|沐风
来源|AI先锋官
就在这周末,开源界元老Meta正式推出了首个原生多模态Llama 4系列模型,性能上全面超越GPT-4o、Gemini 2.0等顶级竞品,同时支持1000万token超长上下文。
该系列总共公布了3个模型,分别为Scout、Maverick和Behemoth。
在这三个模型中,Maverick、Scout都是从Behemoth上蒸馏得来,并且Scout和Maverick已经开源,可以在其官网和Hugging Face上进行下载。
据官方介绍,Llama 4是Meta迄今为止最先进的模型,也是同类产品中多模态性最强的模型。
另外,Llama 4模型是Llama系列模型中首批采用混合专家(MoE)架构的模型,也是DeepSeek系列模型采用的架构。
与传统的稠密模型相比,在MoE架构中,单独的token只会激活全部参数中的一小部分,训练和推理的计算效率更高。
接下来,我们就一起看看Llama 4系列模型都有哪些亮点。
-
-
-
-
-
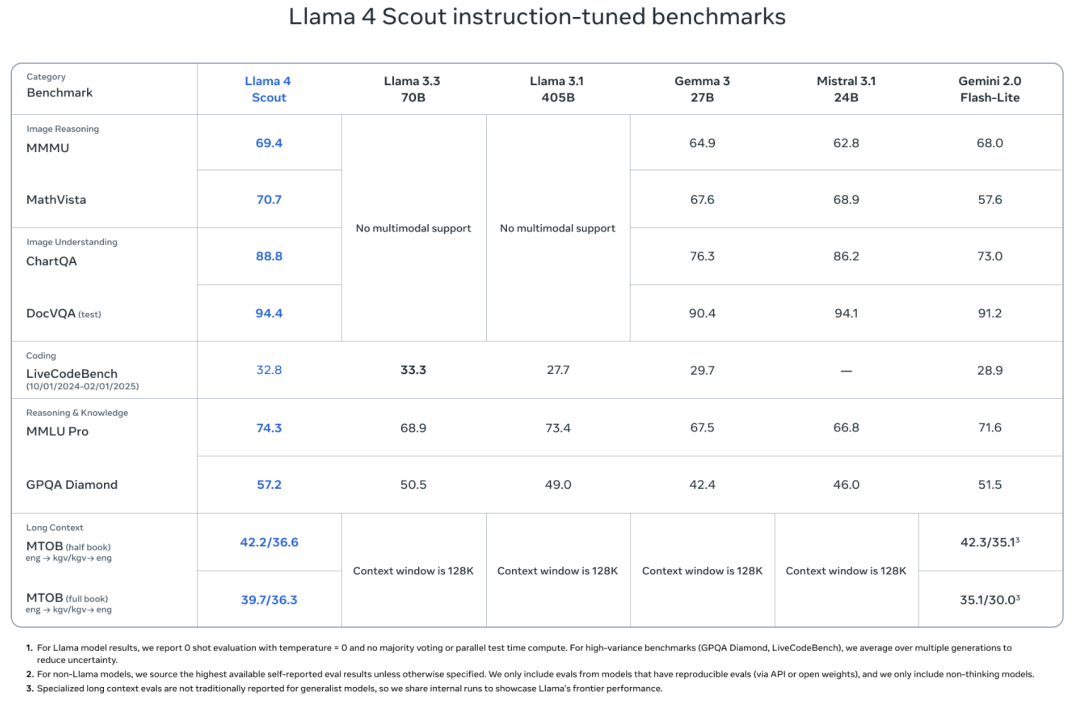
在基准测试中,其性能表现超过了Gemma 3、Gemini 2.0 Flash-Lite以及Mistral 3.1。
-
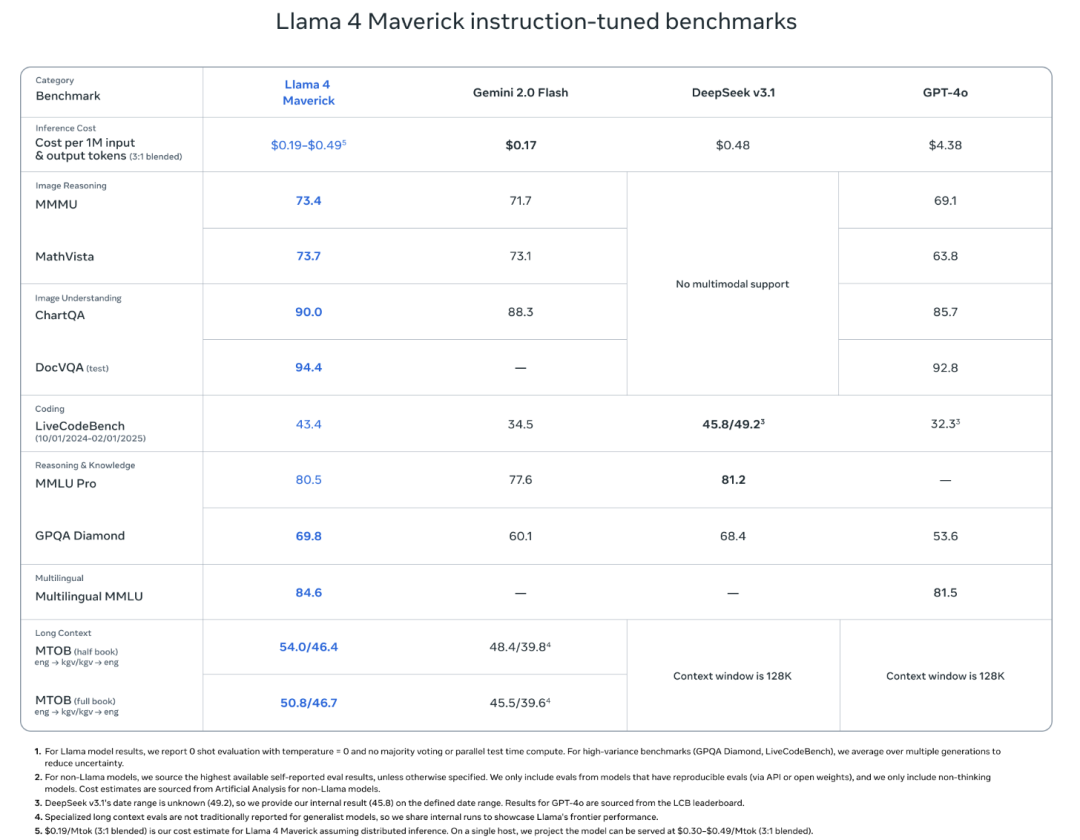
同样具备170亿活跃参数,总参数量增加至4000亿。
-
专家模块的数量增加到128个,每次推理激活17个专家。
-
-
基准测试中,其性能表现超越了GPT-4o和Gemini 2.0 Flash。
-
在推理、编程、多语言等任务上媲美DeepSeek v3,但参数仅为其一半。
-
-
-
-
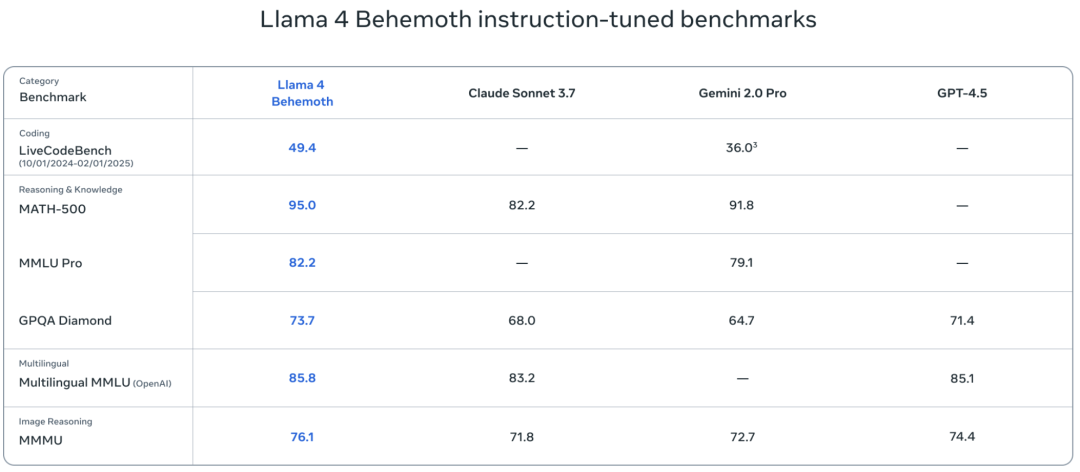
在多个 STEM 基准测试中优于 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro。
-
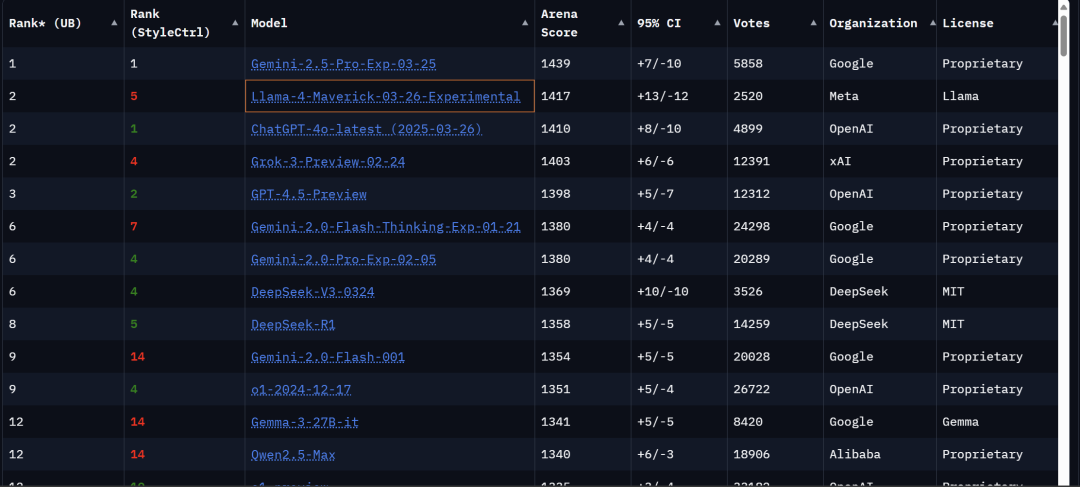
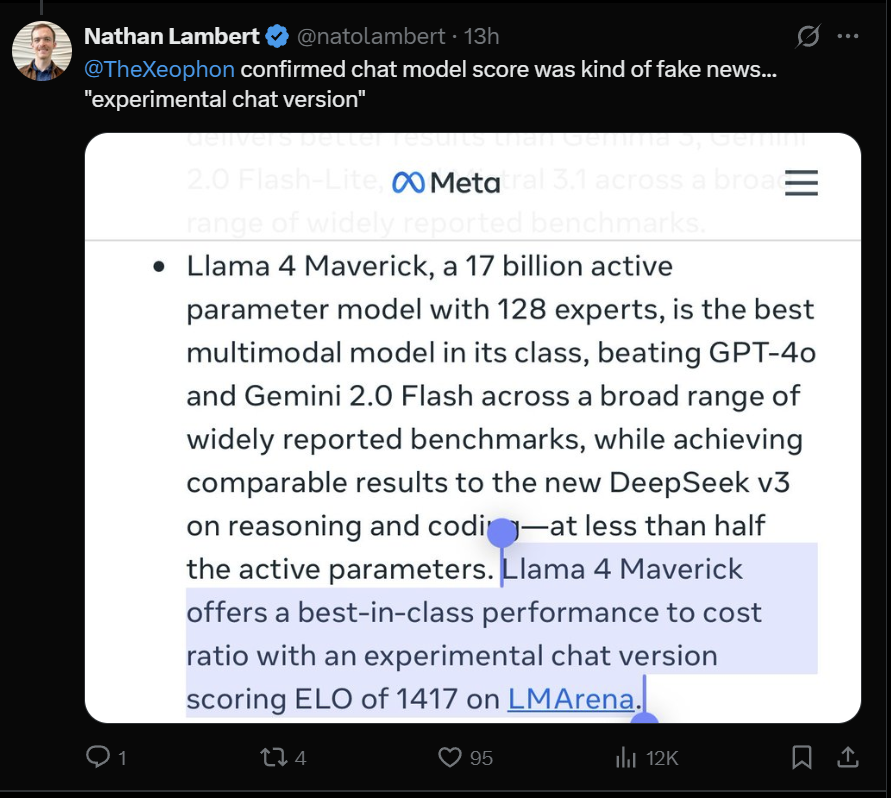
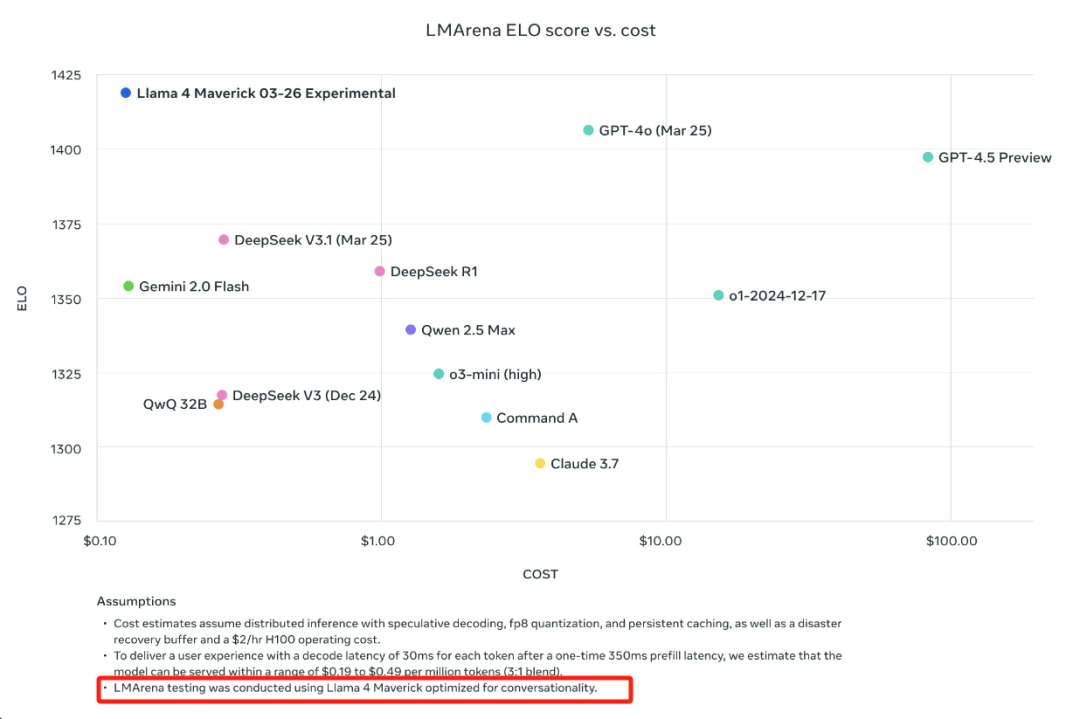
值得一提的是,Llama 4 Maverick一经发布就冲上了LMArena排行榜中的第二名,仅仅比 Gemini-2.5-pro模型少22分,成为第四个突破 1400 分的大模型。
据多位AI研究人员在社交平台X上指出,Meta在LMArena上部署的Llama 4 Maverick与广泛提供给开发者的版本并不一致。
不过,Meta在其公告中明确提到,参与LMArena测试的Llama 4 Maverick是一个“实验性聊天版本”。
而根据官方Llama网站上公布的信息,Meta 在LMArena的测试中所使用的实际上是“针对对话性优化的Llama 4 Maverick”。这表明,该版本经过了专门的优化调整,以适应 LM Arena 的测试环境和评分标准。
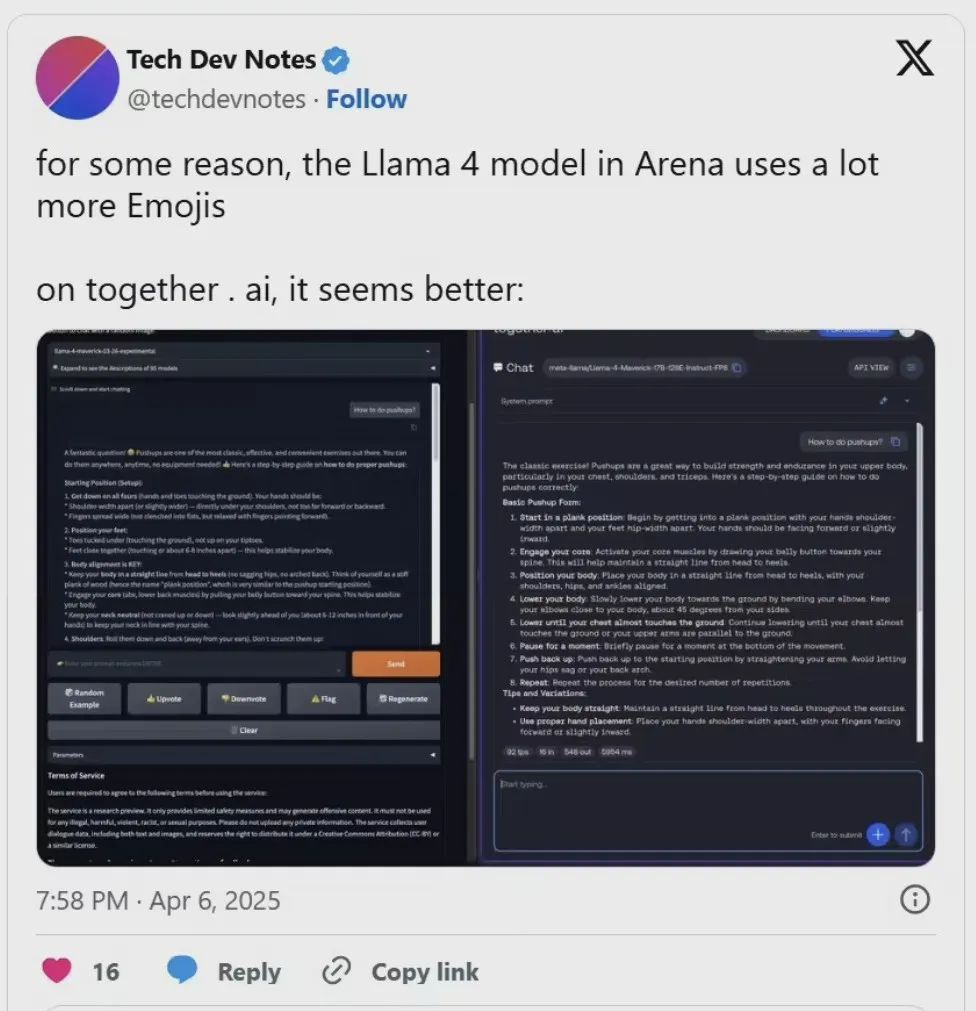
有AI研究人员在社交平台X上指出,公开可下载的Maverick与LMArena上托管版本之间存在明显行为差异。LMArena版本更倾向于使用大量表情符号并提供冗长的回答,这在标准版本中并不常见。
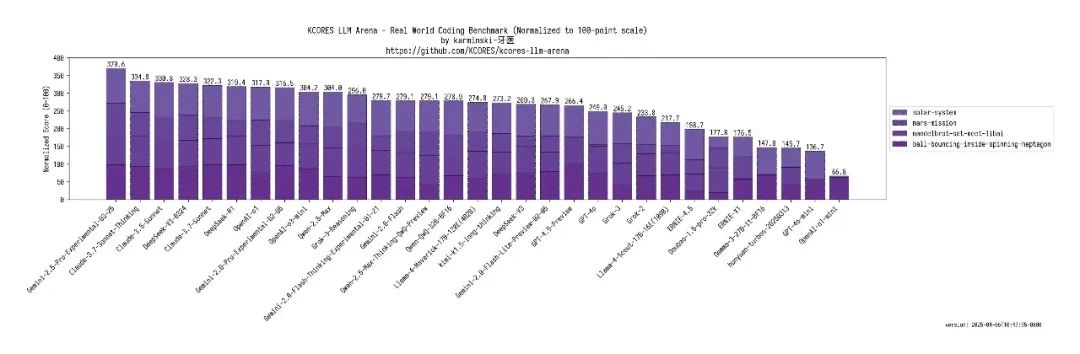
在实际使用中,很多人觉得Llama 4的编码能力和数学逻辑方面都没有测试中那么厉害,甚至有社区用户给它进行了重新打分,重新打分后的Llama 4连前10都进不去。
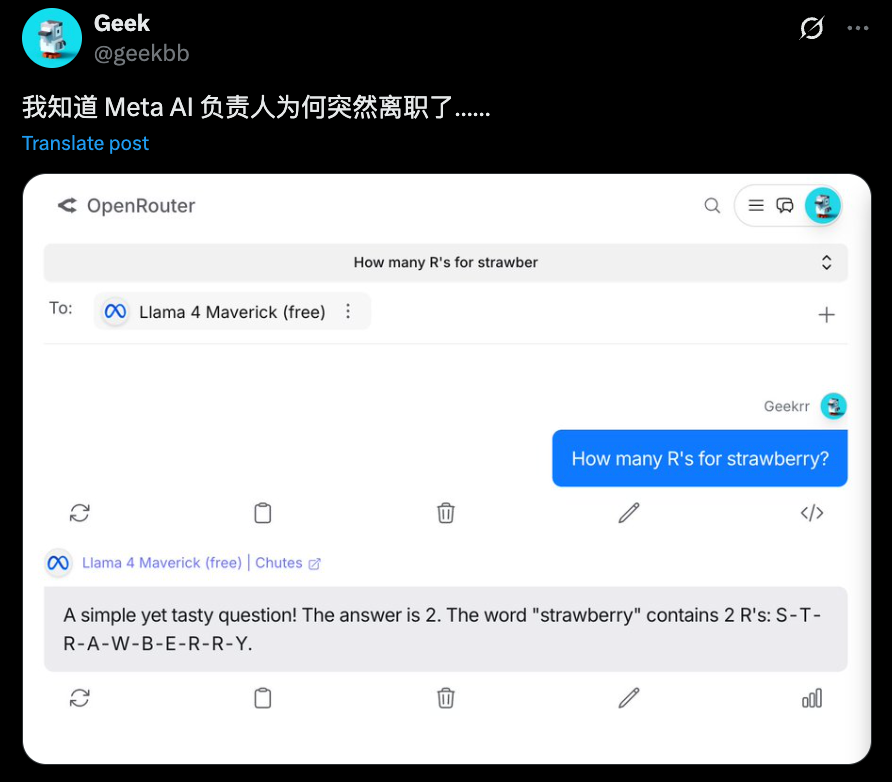
在经典测试题“strawberry中有多少个R”的问题上,Llama 4 Maverick也未能做对。
据博主“karminski-牙医”发布的评测结果显示,Llama 4 Maverick与Qwen-QwQ-32B的写代码水平一致,Scout则是直接挂科。
看来,Llama 4这次更像是个“偏科生”,多模态和长文本是长板,但逻辑推理和代码生成似乎还需要打磨。
例如,油管知名博主1littlecoder就指出Llama 4的许可条款与真正的开源精神相去甚远。
马克·扎克伯格在Llama 4发布视频中充满热情地宣布:”今天是Llama 4的日子。我们的目标是构建世界领先的AI,将其开源,并使其普遍可访问,让全世界都能受益。我一直认为开源AI将成为领先模型,而随着Llama 4,这开始变为现实。”
然而,1littlecoder直言不讳地表示:”这是对开源的污蔑,与开源毫无关系。你可以称它为开放模型,你可以称它为开放权重模型,但它不是开源的。”
1littlecoder认为,开源软件的基本原则之一是普遍可访问性。开源通过开源或免费许可促进对产品的普遍访问。这意味着任何人都应该能够访问你的产品,而不会有太多麻烦。”
与其他真正开源的AI模型相比,Llama 4的获取过程显得异常复杂。
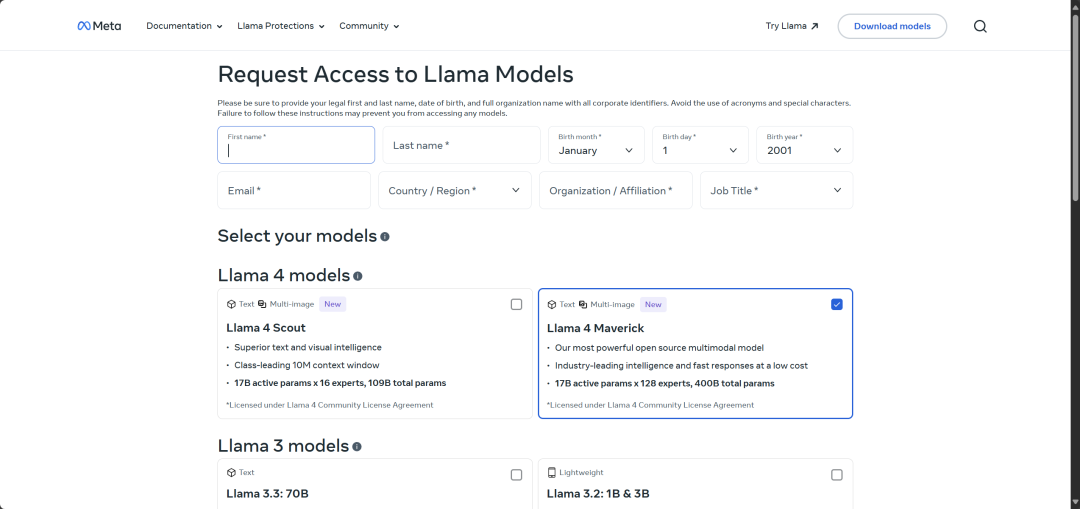
1littlecoder提到,“Meta的模型要求你首先登录Hugging Face账户,这点我能理解,他们可能有垃圾邮件问题。然后填写表格,务必提供你的法定全名。我是说,为什么下载PyTorch权重或一些随机二进制文件需要提供我的法定姓名?还有出生日期、完整的组织名称、所有公司标识符。”
更令人担忧的是,表格上明确警告:“避免使用首字母缩写和特殊字符。未能按照这些指示操作可能会阻止你访问此模型和Hugging Face上的其他模型。提交后,你将无法编辑此表格。因此,请确保所有信息准确无误。”
这意味着一旦因填写信息不当被Meta禁止,用户可能永远无法从Hugging Face下载该模型,这与开源软件的普遍可访问性原则直接冲突。
1littlecoder更是将其描述为”对开源的污蔑”。
这份许可协议包含多项限制,直接挑战了传统开源定义:
首先是用户限制条款:“如果你拥有一家月活跃用户超过7亿的公司,你不能使用这个模型。”虽然这对大多数开发者来说影响有限,但它违背了开源软件不应对使用者有歧视的基本原则。
其次是关于再分发的严格要求。许可证规定,如果分发或提供Llama材料,必须显示”使用Llama构建”的标志。
1littlecoder对此表示强烈不满:“为什么我要这样做?你想加速开源,对吧?你不是在寻求任何好处,因为你相信开源。只要给我模型,我想怎么用就怎么用。这是愚蠢,完全的愚蠢。”
更令人震惊的是命名要求:“如果你使用Llama材料或任何Llama材料的输出或结果来创建、训练、微调或以其他方式改进分发或提供的AI模型,你还应该在任何此类AI模型名称的开头包含‘Llama’。”
此外,还有版权声明要求:“在你分发的Llama材料的所有副本中,你必须包含以下归属声明,并与分发的此类副本一起提供声明文本文件‘Llama 4的许可证和Llama 4社区许可证,版权Meta平台,保留所有权利。’”
1littlecoder在结束时呼吁AI社区重新思考什么才是真正的开源:“请不要称这为开源。我相信,将任何进入Hugging Face的愚蠢模型称为开源,对于开源代表的内容或开源支持者来说,是一种污蔑。这不是开源,只是你可以下载并带有一堆限制的开放权重。”
(文:AI先锋官)