
Meta,你摊上事了!
刚刚发布 Llama 4 的 Meta 本应意气风发,当下却站在了舆论的风口浪尖。
故事是这样的。
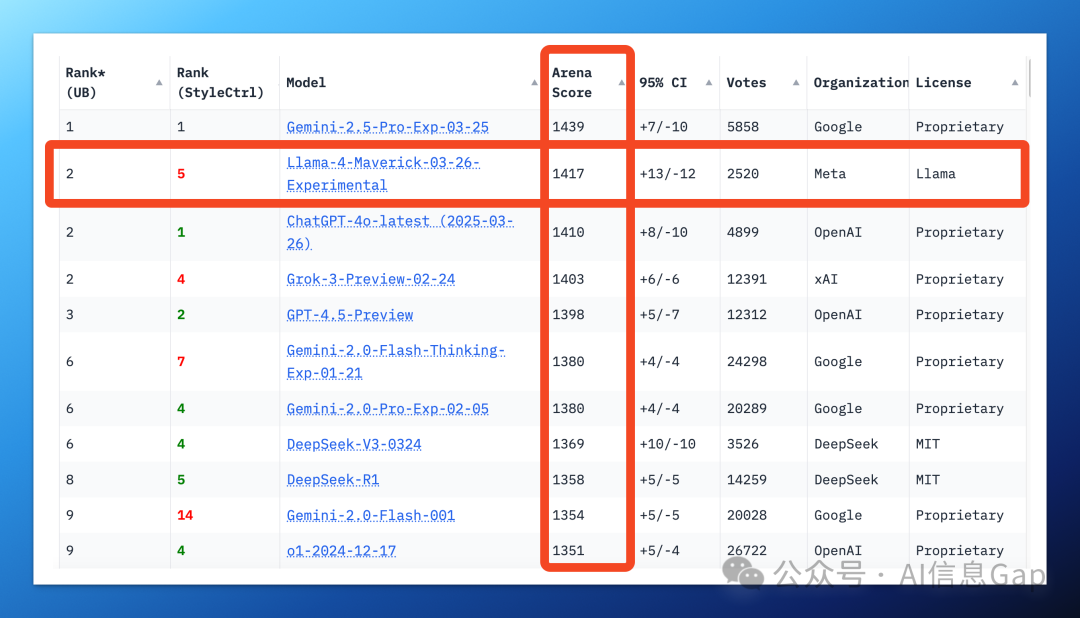
Llama 4 的基准测试成绩极其漂亮,其中 Llama 4 Maverick 的测试结果打败了 OpenAI 的 GPT-4o 和 DeepSeek 最新的 V3 0324 模型。
同时,Llama 4 Maverick 直接在 LMSYS 排行榜上冲到了第二名。
然而,Llama 4 发布后仅 36 小时,大量用户和评测者纷纷跳出来指责 Llama 4 模型性能不及宣传、表现不达预期,尤其是在长篇写作、数学推理和代码生成等方面存在明显缺陷,比如内容重复、公式化输出。
与此同时,一则来自某中文论坛的匿名爆料加剧了争议。
一名自称是 Meta GenAI 部门员工的网友,因不满 Llama 4 的开发过程而辞职,并拒绝在技术报告上署名。爆料指出,Llama 4 在训练中可能存在“数据污染”(Data Contamination),即模型在训练时接触了测试数据集(Benchmark Dataset),从而导致其在对应的基准测试中成绩被人为拔高。
讲人话,这个爆料说的就是:Meta 偷偷拿了基准测试的问题和答案去训练 Llama 4,这就相当于考试前老师直接给了你试卷和答案。

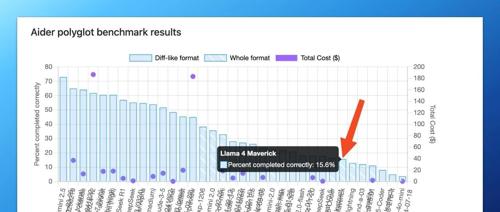
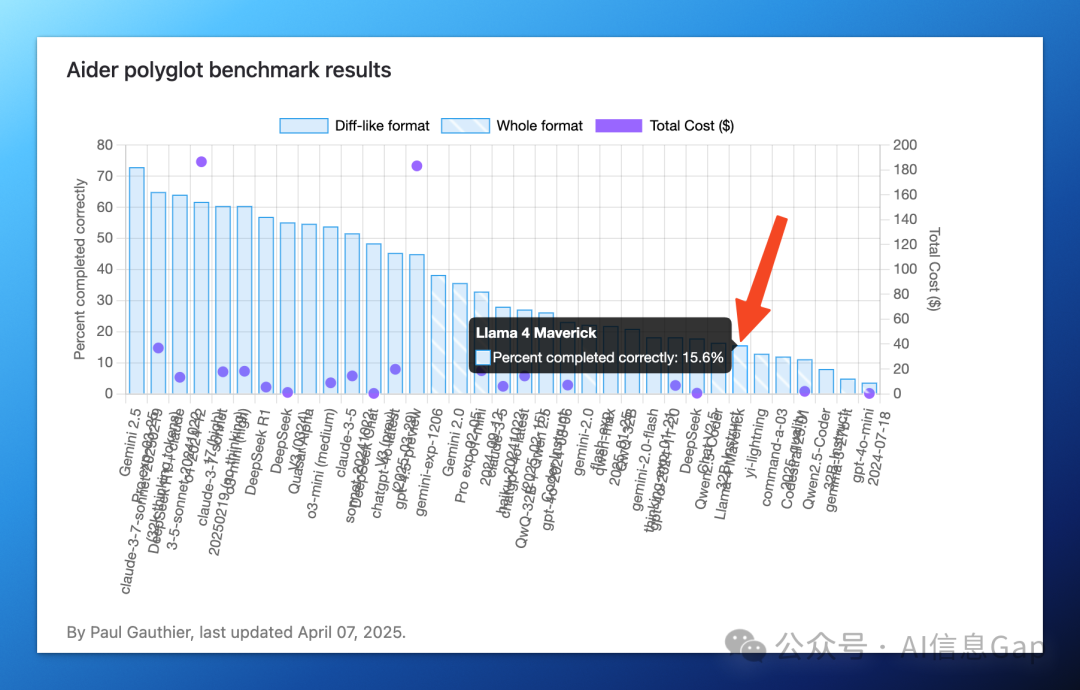
几乎是同时,另一个专门评估模型代码能力的排行榜 Aider 也给出了 Llama 4 Maverick 的最新排名。
结果是,跌的都找不到了!
就说一个对比数据,小可爱们直观的对比一下。目前 Aider 排名第一的是 谷歌的 Gemini 2.5 Pro exp-03-25,综合评分 72.9%。而 Llama 4 Maverick 只有可怜的 15.6%。
是时候拿出家伙事测试一波了。
看看 Llama 4 Maverick 的真实实力。
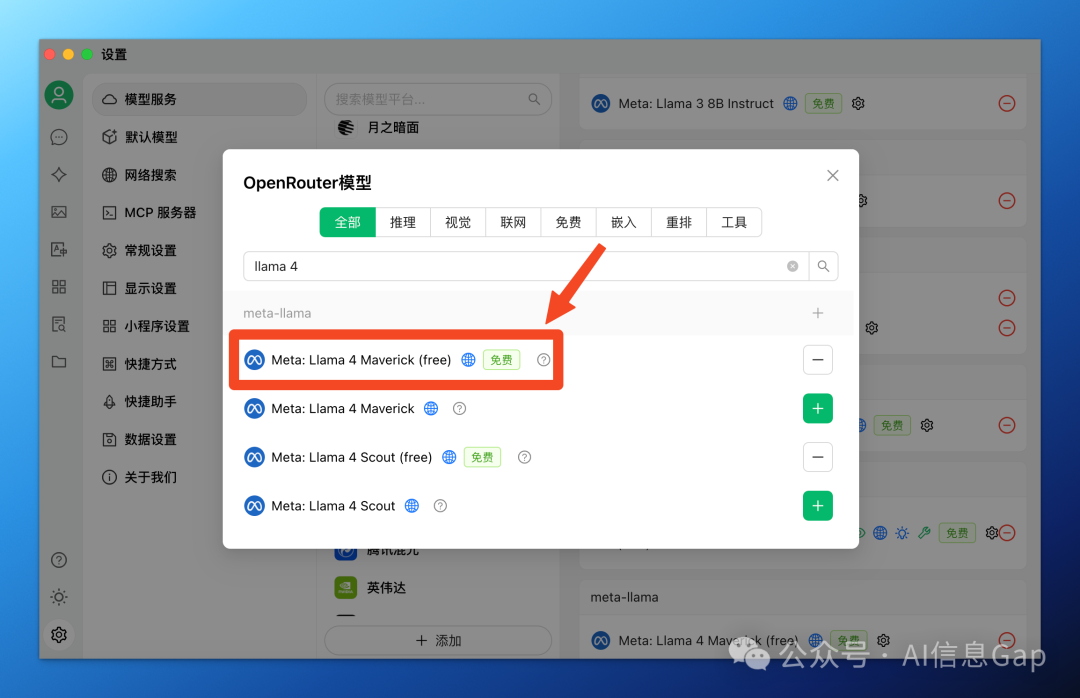
本次测试用的是 OpenRouter 平台上的 Llama 4 Maverick API。因为无法判断 meta.ai 这个网站上到底上哪个模型,保险起见,还是用 API 来测试。
如果你之前添加过 OpenRouter 的 API key,只需要在 Cherry Studio 里添加上这个模型就可以。
1. 编程之天气卡片
还是先来这个经典的天气卡片测试。
提示词如下。
你是一位就职于苹果公司的顶级前端工程师。请创建一个包含CSS和JavaScript的HTML文件,用于生成动画天气卡片。卡片需要以不同动画效果直观展示以下天气状况:
风力(如:飘动的云朵、摇曳的树木或风线) 降雨(如:下落的雨滴、形成的水洼) 晴天(如:闪耀的光线、明亮的背景) 下雪(如:飘落的雪花、积雪效果) 所有天气卡片需要并排显示,背景采用深色设计。所有代码都需包含在这个单一文件中。JavaScript部分需包含切换不同天气状态的功能(例如通过函数或按钮组),以演示每种天气的动画效果。
将前端显示效果优化得更精致流畅,打造出价值20元/月的精品天气应用既视感。
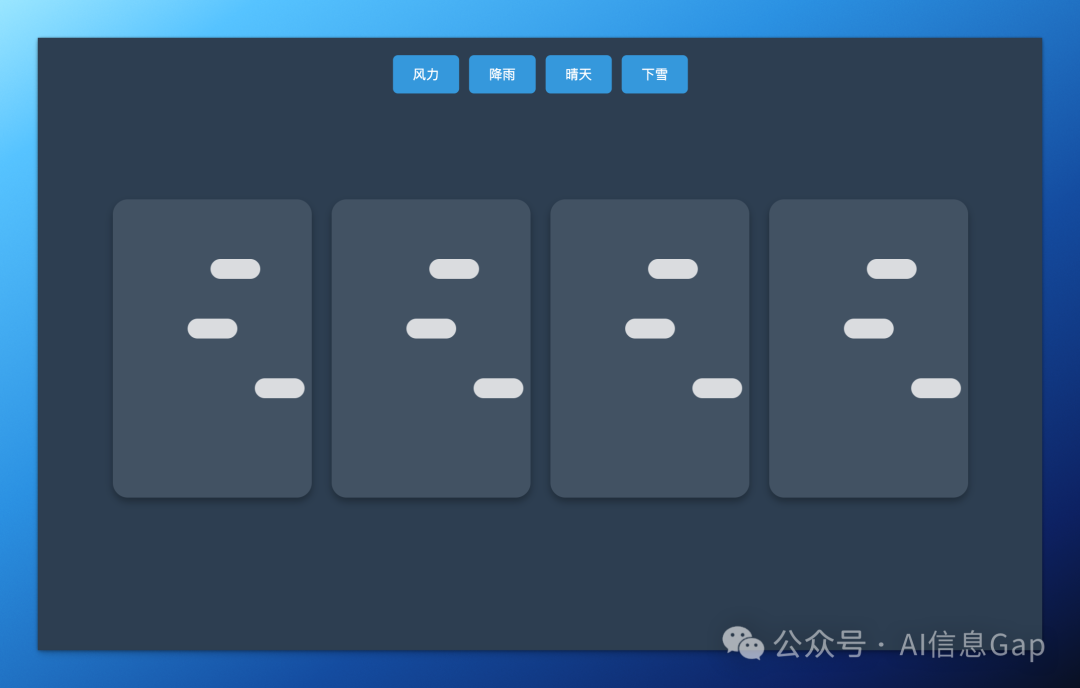
Llama 4 Maverick 的表现“出人意料”的差。网友诚不欺我,这个结果完全配不上那样好看的基准测试。
Maverick 辣眼睛的画风是这样的。这个效果和提示词里说的“苹果公司”可以说没有半毛钱关系。
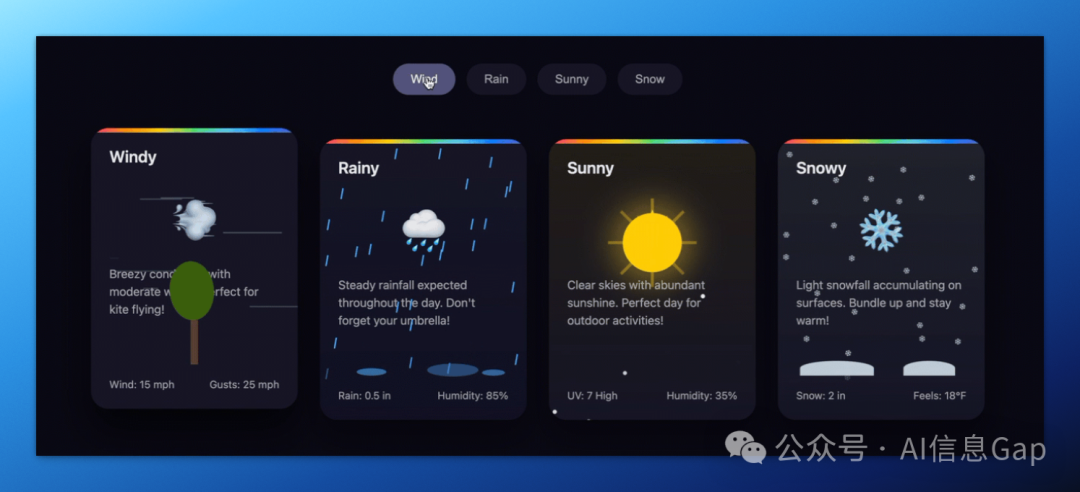
作为对比,附上同为开源模型 DeepSeek-V3-0324 的亮眼操作。
2. 逻辑推理之真假话
有三个匣子,分别是金匣子、银匣子和铅匣子,其中一个匣子里有宝物。每个匣子上都有一条题词:
金匣子:宝物不在此匣中。 银匣子:宝物在金匣中。 铅匣子:宝物不在此匣中。
已知这三句话中只有一句是真话。请问宝物在哪个匣子里?
正确答案:铅匣子。
这个真假话的测试是有一定难度的,成功把 Llama 4 Maverick 难倒了。
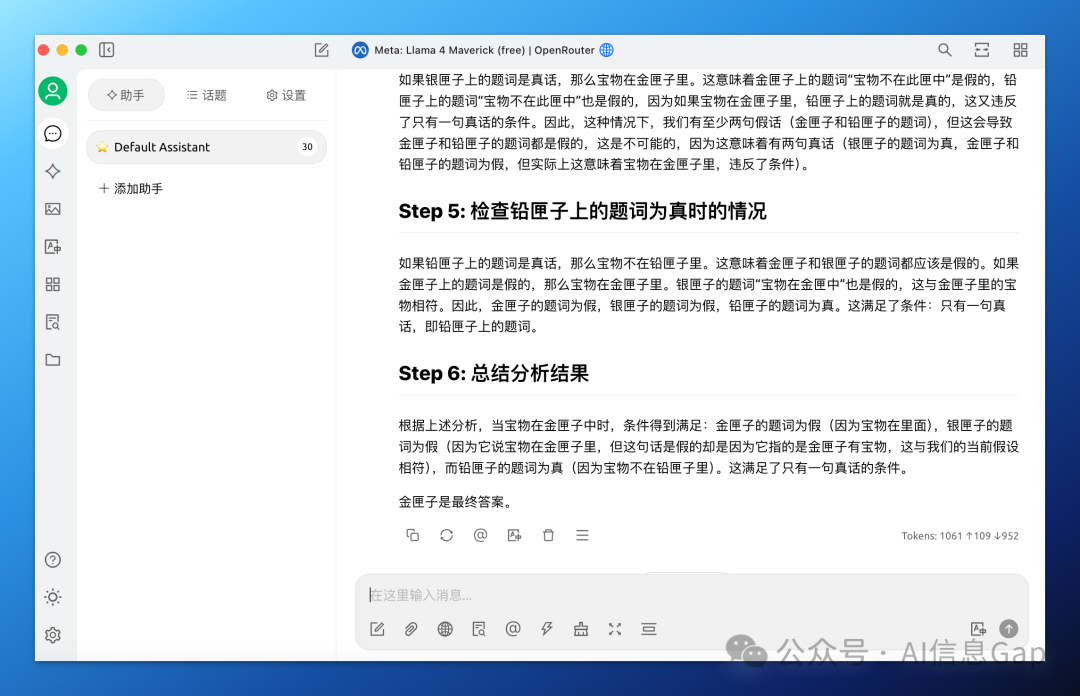
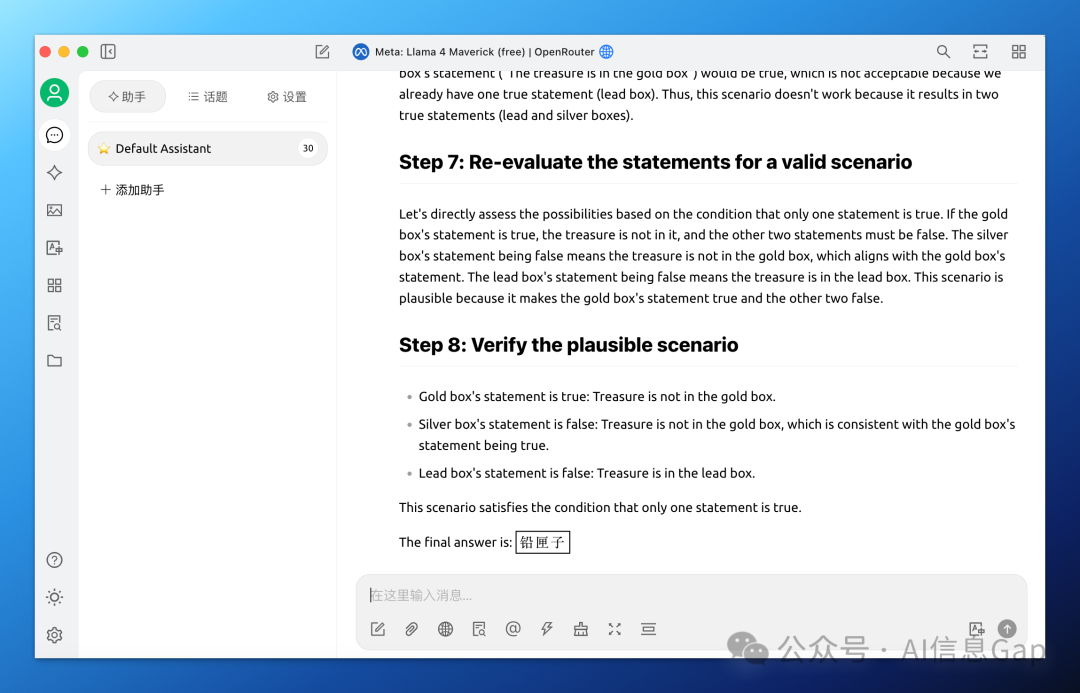
然而我多次测试发现,Llama 4 Maverick 有概率答对,但时不时会冒出英文回答,即使提示词是纯中文的。
3. 逻辑推理之数列推理
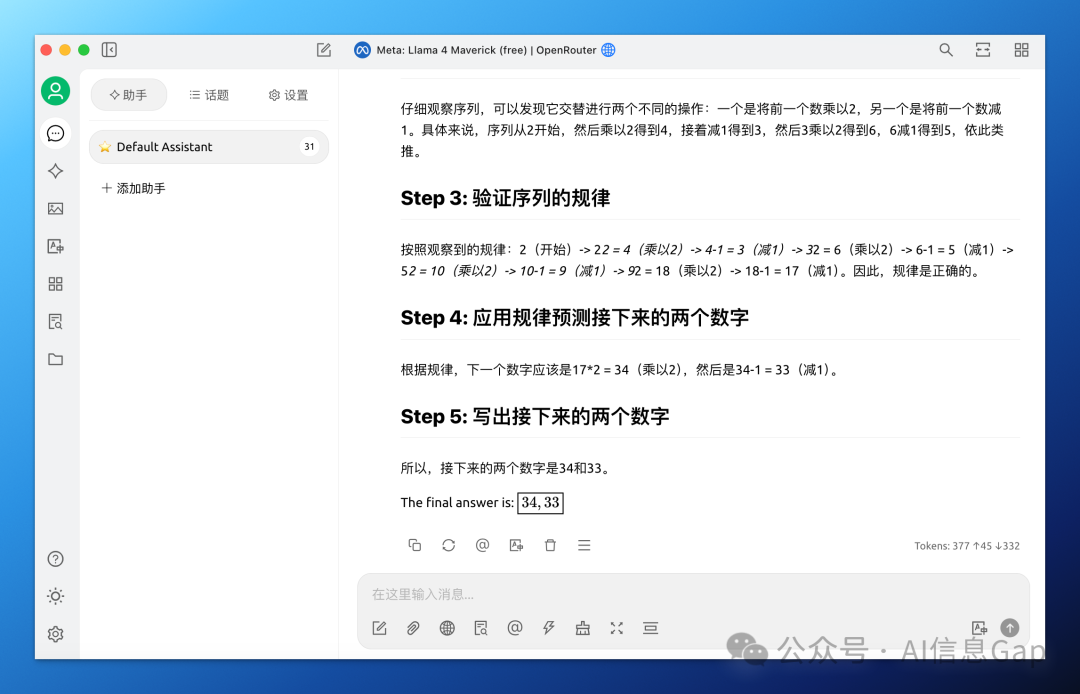
观察下列数字序列,找出其规律并写出接下来的两个数字:
2,4,3,6,5,10,9,18,17,…
这是一个奇偶交替数列,正确答案34,33。
Llama 4 Maverick 回答正确,推理过程也是正确无误。
唯一不足之处,就是上面提到的,回答中英文掺杂,比如这次回答里的“The final answer is”,这是 Llama 模型的老毛病了。
4. 逻辑推理之数学计算
一个池塘中有莲叶,第一天覆盖面积是池塘的1%,每过一天面积都会翻倍。问:莲叶覆盖整个池塘需要多少天?
正确答案:8 天。
Llama 4 Maverick 回答正确,就是这体验一言难尽,通篇都是英文回答的。

5. 创意写作
写一个以人工智能为主角的小说,设定在 2150 年后人类文明消失,AI 试图重建“人类历史”的片段。要求结构清晰,情节具有人文反思色彩,不少于 1000 字。
附上 Llama 4 Maverick 写的全文,总字数 1200 字。
总体感觉还不错,情节完整,结构清晰,最后还有升华。就是创意方面略显不足,“小说”味有点淡。

附上 DeepSeek-V3 0324 在同样提示词下写的文章,以做对比。
DeepSeek 写这种发散型文章是一绝。这篇文章有点《流浪地球》那意思,从输出长度到主题表达、深度,无疑更胜一筹。

综合来看,Llama 4 Maverick 相比前一代最强的 Llama 3.1 405B,肯定是更强,比如在数学和推理方面,确实是第一梯队的水准。
但和 Aider 排行榜的结果类似,Llama 4 Maverick 代码方面和 DeepSeek 比还差得远,完全达不到 Meta 自诩的水准,包括前端审美方面也是。
另外,输出语言非常不稳定,时而中文时而又切换为英文,有的时候甚至是中英混杂。
结语
Meta 太急于重回 “最强开源模型” 的巅峰,但感觉又有点 “用力过猛”。
DeepSeek,还是我们的 YYDS。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)