

HolmesVAU团队 投稿
量子位 | 公众号 QbitAI
多模态视频异常理解任务,又有新突破!
“异常理解”是指在视频监控、自动驾驶等场景中,利用模型发现视频中的异常内容,从而预判危险,以便及时做出决策。
来自华中科大等机构的研究人员,提出了新的视频异常理解模型Holmes-VAU,以及相关数据集。
与通用多模态大模型对比,Holmes-VAU在各种时序粒度的视频异常理解上都展现出显著优势。

为了实现开放世界的多模态视频异常理解(VAU),已有的VAU benchmark只有短视频的caption标注或长视频的instruction标注,忽略了视频异常事件的时序复杂性。
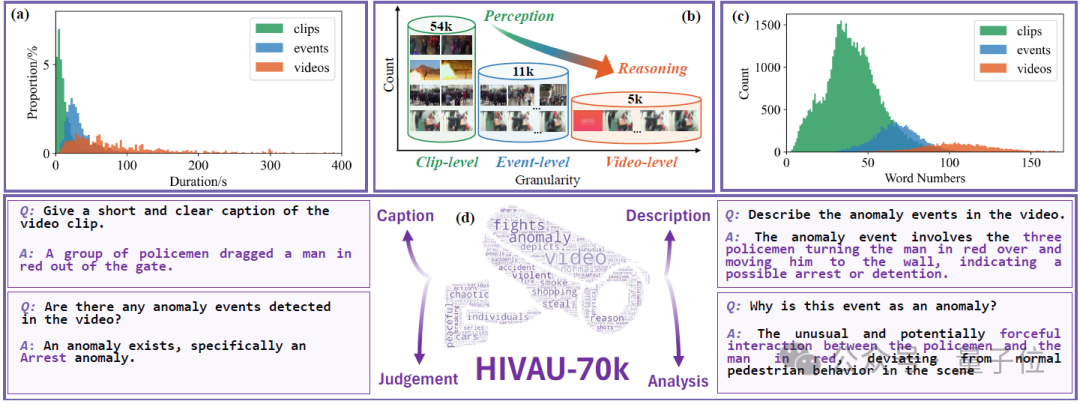
为同时促进模型对短视频的感知能力和对长视频的推理能力,作者提出了一种高效半自动数据引擎并构建了HIVAU-70k数据集,包含超7万视频异常理解任务的多时序尺度指令数据。
同时作者提出了一种基于异常分数的时序采样器,从长视频中动态稀疏采样关键帧到后续多模态大模型中,显著提升了异常分析的准确性和推理效率。
多层级视频异常理解指令数据集
针对视频异常理解任务(Video Anomaly Understanding),以往的一些异常视频指令数据集主要有两方面问题:
-
数据集中的视频时长较短,导致模型缺乏对长视频的异常理解能力; -
即便包含长视频,也缺乏对长视频的细粒度和结构化的标注,导致模型的异常理解空间难以对齐。
为此,作者提出了一个大型多模态指令数据集HIVAU-70k,其中包含多种时间粒度的视频异常标注,由粗到细分别为:
-
video-level:未裁剪长视频,包括视频中所有异常事件的文本描述分析; -
event-level:从长视频中裁剪出的异常事件片段,包括单个异常事件的文本描述分析; -
clip-level:从event中进一步裁剪出的视频片段,包括视频片段的文本描述。
HIVAU-70k中的指令数据包括视频描述、异常判断、异常描述和异常分析等任务,为视频异常理解多模态大模型提供了丰富多样的数据来源。
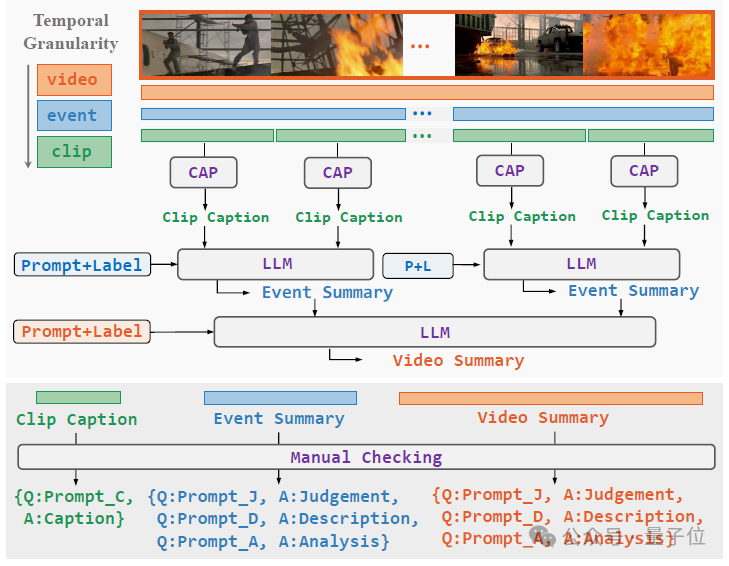
这样的多层级指令数据集是怎么构造的呢?从一个未裁剪的长视频开始,需要依次经过以下三个步骤:
-
分层视频解耦(Hierarchical Video Decoupling):将video-level视频中的异常事件标注并裁剪出来,得到event-level视频, 再对event-level视频进一步平均切分得到clip-level视频; -
分层自由文本注释(Hierarchical Free-text Annotation):对于clip-level视频,使用人工或caption model得到clip caption;对于event-level视频,结合所包含的clip-level caption和异常类别,提示LLM得到事件总结;对于video-level视频,结合所包含的事件总结和异常类别,提示LLM得到视频总结; -
层次化指令数据构建(Hierarchical Instruction Data Construction):针对不同层级的视频及其文本标注,设计不同的任务,构造任务相关的问题并与文本注释组合,得到最终的指令数据。
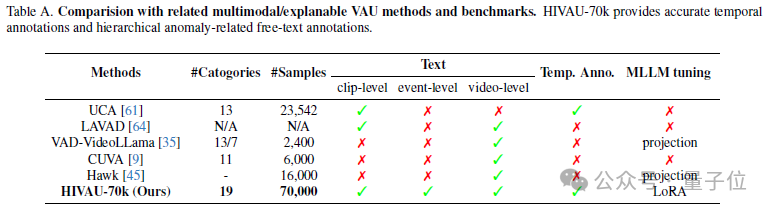
与其他相关的数据集相比,HIVAU-70k不仅有数量上的优势,还提供了多粒度的文本标注以及时序上的异常边界标注。
动态稀疏采样的视频异常理解模型
长视频异常理解在使用大型语言模型(LLMs)或视觉语言模型(VLMs)时,常因帧冗余问题而受到限制,导致异常检测的准确性变得复杂。
以往的VAU(视频异常理解)方法难以聚焦异常。
例如,密集窗口采样方法会增加大量冗余帧的计算量,而均匀帧采样方法常常错过关键异常帧,使其应用范围局限于短视频。
为此,作者提出了Anomaly-focused Temporal Sampler (ATS),并将其集成到VLM中,通过在HIVAU-70k上的指令微调,构建了Holmes-VAU模型。
异常帧通常比正常帧包含更多信息,并表现出更大的变化,基于这一观察,作者设计了一种采样策略,在异常分数较高的区域采样更多帧,同时在分数较低的区域减少采样。
为实现非均匀采样,作者提出了一种“密度感知采样器”(density-aware sampler),用于从总共T个输入帧中选择N个帧。
具体来说,作者将异常分数S视为概率质量函数,并首先沿时间维度累积它们,得到累积分布函数(CDF),记为 S_cumsum:
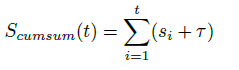
接着,在累积轴上均匀采样N个点,并将这些点映射到累积分布S_cumsum上。相应的时间轴上的N个时间戳会被映射到最接近的帧索引,最终形成采样的帧索引集合G。
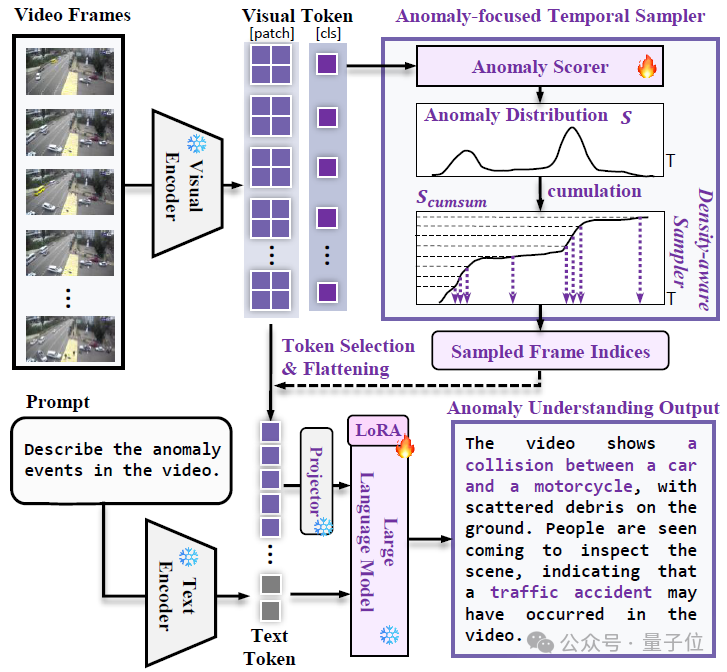
△Holmes-VAU模型框架图
下入展示了测试集上的异常分数和采样帧的可视化结果。这些结果表明了ATS的准确异常检测能力,最终输入到多模态大模型的采样帧也集中于异常区域。
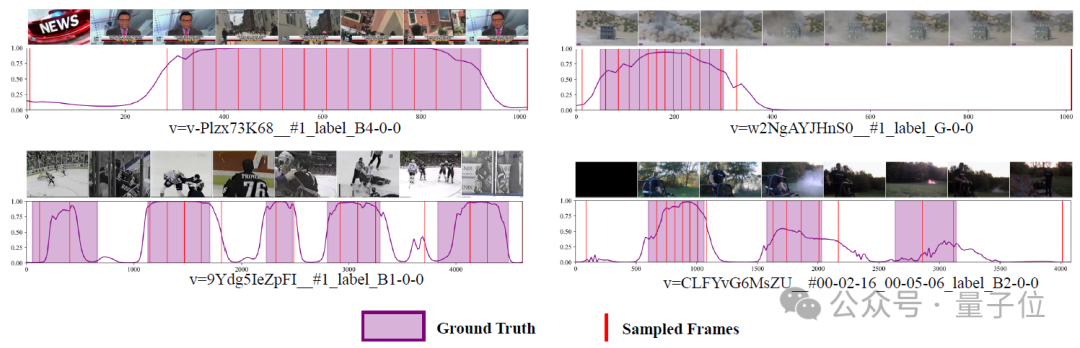
△Anomly-focused Temporal Sampler (ATS) 异常分数及采样帧示意图
实验结果
异常推理性能评估
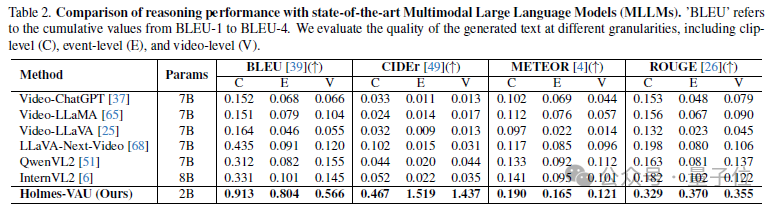
作者在HIVAU-70k的测试集上,将模型输出的推理文本与注释的真实文本进行比较,计算了包括BLEU、CIDEr、METEOR和ROUGE等指标来衡量模型输出的异常理解文本质量。
与通用多模态大模型对比,Holmes-VAU在各种时序粒度的视频异常理解上都展现出显著优势。
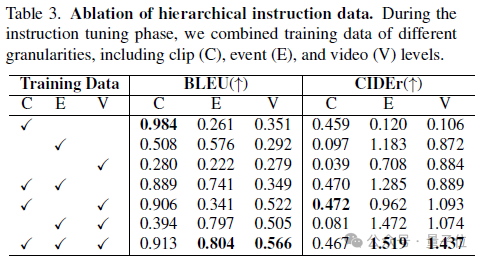
在多层级标注中,对不同层级指令数据集的组合,可以观察发现,单一层级的标注只能提升单一层级任务的性能。
不同层级的标注组合可以相互补充,实现从clip-level的基础视觉感知, 到event-level单一异常事件的分析,再到video-level的长时序异常总结和推理等方面的全面提升,达到更细粒度和完整的多模态异常空间对齐。
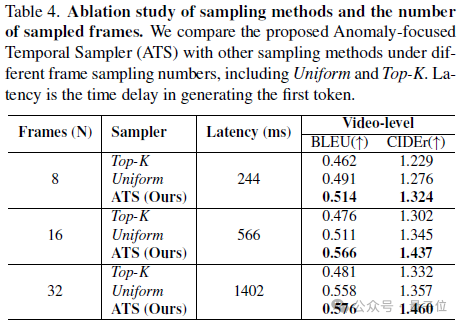
对于非均匀采样器的作用,作者也对比了不同帧采样方式,包括本文提出的ATS、之前方法用的Top-K采样和Uniform采样。
结果表明在相同的采样帧数下,ATS展现出更优越的长视频异常理解能力,这是由于Top-K采样过于集中在异常帧,忽略了视频上下文的参考,Uniform采样则容易忽略关键的异常帧。
而作者提出的ATS则有效结合了这两者的优势,关注异常帧的同时,能够保留部分上下文帧的采样。
定性比较
下图对比了Holmes-VAU和其他MLLM输出的异常分析文本,Holmes-VAU表现出更准确的异常判断和分析能力,同时对长视频也表现出更完整的异常总结能力。

△Holmes-VAU和其他MLLM的异常分析文本质量对比
论文:
https://arxiv.org/abs/2412.06171
代码:
https://github.com/pipixin321/HolmesVAU
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
(文:量子位)