🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
Hi,这里是Aitrainee,欢迎阅读本期新文章。
AI 视频生成又卷出新高度:一分钟猫和老鼠动画,直接一镜到底。
Karan Dalal 和他的合作者们扔出了一篇新论文——《One-Minute Video Generation with Test-Time Training》。
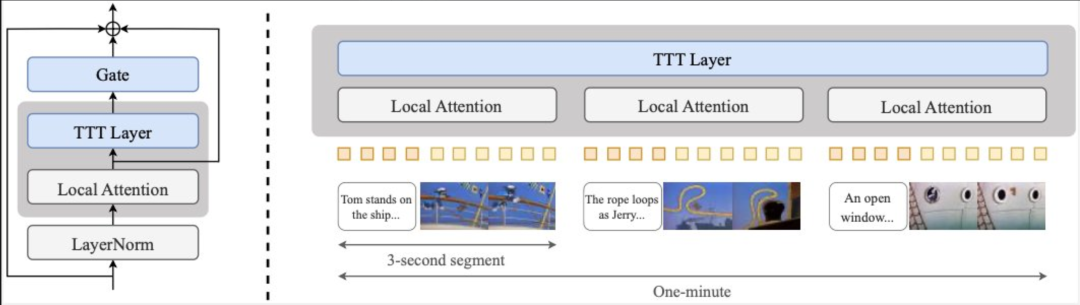
核心:给预训练的 Transformer 模型加上了 Test-Time Training (TTT) 层,然后微调,直接就能生成长达一分钟的《猫和老鼠》动画片,而且时间连贯性还很强。
下面这些视频全是模型一次性生成的,没有经过任何编辑、拼接或后期处理,连故事情节都是全新的。
输入:汤姆和杰瑞参观了一个热闹的嘉年华,汤姆热切地尝试玩扔球游戏,但屡屡失败,导致杰瑞嘲笑他。汤姆沮丧不已,下定决心,但尽管尽了最大努力,他还是无法把罐子打翻。杰瑞自信地走进来,轻松地
输入:汤姆在厨房餐桌上开心地吃着苹果派。杰瑞看起来渴望地想要吃一些。杰瑞走到房子前门外按门铃。汤姆来开门时,杰瑞跑到后面的厨房。杰瑞偷走了汤姆的苹果
输入:在一次水下探险中,杰瑞找到了一张藏宝图,并在躲避汤姆追捕的同时寻找宝藏,途中穿过珊瑚礁和海藻森林。杰瑞在一艘沉船中发现了宝藏,他欣喜若狂地庆祝着,而汤姆的追捕却将他引向
Demos: http://test-time-training.github.io/video-dit/
Paper: http://test-time-training.github.io/video-dit/assets/ttt_cvpr_2025.pdf
作者解释,可以把它理解成一种特殊的 RNN 层,它的“隐藏状态”本身就是个机器学习模型,而更新规则就是一步梯度下降。(他之前就有相关的研究基础)
把 TTT 层加到预训练的 Diffusion Transformer 上,再用带文本标注的长视频进行微调。为了控制成本,自注意力机制只关注局部片段,让计算复杂度更低的 TTT (线性复杂度) 来处理全局信息。
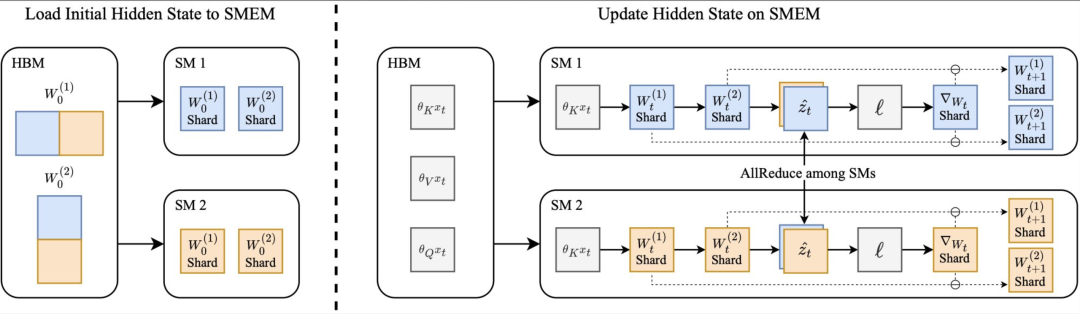
整了个叫 “On-Chip Tensor Parallel” 的算法来优化 TTT-MLP kernel 的效率。简单说,就是把“隐藏状态模型”的权重分片存在 Hopper GPU 的流式多处理器 (SMs) 上,利用 DSMEM 特性在 SM 之间搞 AllReduce,避免了昂贵的跨芯片数据传输。
这篇工作将在 CVPR 2025 上展示。 当然,大佬云集,合作者功不可没 (列了一长串名字)。
🌟 知音难求,自我修炼亦艰,抓住前沿技术的机遇,与我们一起成为创新的超级个体(把握AIGC时代的个人力量)。
参考链接:
[1] https://x.com/karansdalal/status/1909312851795411093
点这里👇关注我,记得标星哦~
(文:AI进修生)