

白寅岐 投稿
量子位 | 公众号 QbitAI
芯片设计是现代科技的核心,逻辑优化(Logic Optimization, LO)作为芯片设计流程中的关键环节,其效率直接影响着芯片设计的整体性能。
然而,传统逻辑优化算子由于存在大量无效和冗余的变换,导致优化过程耗时较长,成为制约芯片设计效率的主要瓶颈。
为解决这一挑战,中科大王杰教授团队(MIRALab)和华为诺亚方舟实验室(HuaweiNoah’sArkLab)联合提出了基于神经符号函数挖掘的高效逻辑优化方法,显著提升传统关键逻辑优化算子运行效率最高达2.5倍。
论文已被ICLR 2025接收。

研究团队提出了一种创新的数据驱动的电路神经符号学习框架——CMO。
通俗解释,研究团队开发了一种聪明又高效的AI算法框架。这个系统通过“看图识路”(图神经网络)加上“会下棋的策略”(蒙特卡洛树搜索),能够自动学会如何更快、更智能地“剪枝”电路逻辑——就像帮电路减肥,让它运行得更快但不丢性能。
在实际测试中,CMO能让关键算法运行效率提升最多2.5倍,也就是说,原来跑10分钟的任务,现在4分钟就搞定了。这个技术已经被集成进华为自研的EMU逻辑综合工具中,有力地支持了EDA工具全链条国产化任务。
引言
芯片设计自动化(EDA)被称为“芯片之母”,是半导体行业的关键基石。逻辑优化(LO)是前端设计流程中最重要的EDA工具之一,其核心任务是通过功能等效的转换来优化电路,减少电路的规模和深度,从而提升芯片的质量。
LO任务是一个NP-hard问题。为了解决LO问题,现有的启发式算子(如Mfs2[1]、Resub[2]、Rewrite[3]、Refactor[4]等)通过遍历电路图节点并进行局部转换而实现逻辑优化。但由于现有算子存在大量无效和冗余的转换,导致优化过程非常耗时,严重限制了芯片设计的效率。为了提高LO的效率,先前的研究提出使用打分函数来预测并剪枝无效的节点转换。
现有的打分函数大致分为两类,第一类是人工设计的启发式方案[5],这些方法虽然具有可解释性,但设计过程复杂,且泛化性能较差,难以保证算子优化性能。第二类是基于图神经网络(GNN)的深度学习方案[6],尽管GNN在LO任务中表现出色,但且推理严重依赖于GPU,难以在纯CPU的工业环境中部署。此外,GNN的“黑箱”特性也引发了对其可靠性的担忧。因此,如何找到兼具推理效率、可解释性和泛化性能的打分函数是逻辑优化领域亟待解决的难题。
为了解决上述难题,研究团队提出了首个数据驱动的电路神经符号学习框架(Circuit symbolic learning framework,CMO),该框架采用教师-学生范式,利用泛化性强的GNN模型作为教师,并指导作为学生的基于蒙特卡洛树搜索的符号学习方案,从而有效生成兼具泛化能力与轻量化的符号打分函数。
在三个具有挑战性的电路基准测试中,离线实验结果表明,CMO学习到的可解释符号函数在推理效率和泛化能力方面均显著优于此前基于GPU的最先进方法以及人工设计的方案。此外,在线实验进一步验证了CMO的实际应用价值:CMO能够在保持关键算子优化性能的同时提升其运行效率最高达2.5倍。该方案为芯片设计工具的高效化提供了新的解决方案,目前已成功应用于华为自研EMU逻辑综合工具中。
背景与问题介绍
1.逻辑优化(Logic Optimization,LO)
逻辑优化是电子设计自动化(EDA)工具中的关键模块,旨在通过优化由有向无环图表示的电路图(即减少电路图的面积与深度),提升芯片的性能、功耗和面积(PPA)。逻辑优化通常分为两个阶段:
-
映射前优化(Pre-mapping Optimization):在电路映射到技术库之前,使用启发式算法(如Rewrite、 Resub、 Refactor等)对电路进行优化。 -
映射后优化(Post-mapping Optimization):在电路映射到技术库(如标准单元网表或K输入查找表)后,进一步使用启发式算法(如Mfs2)对电路进行优化。
逻辑优化的核心任务是通过功能等效的转换减少电路的规模和深度,从而提升芯片的质量。然而,逻辑优化是一个NP难问题,现有的启发式算法虽然有效,但由于存在大量无效和冗余的转换,导致优化过程非常耗时。因此,如何提高逻辑优化的效率成为芯片设计中的一个关键挑战。
2.基于节点剪枝的高效逻辑优化框架
为了提升逻辑优化的效率,研究者提出了如图1所示的预测与剪枝框架(Prediction and Prune Framework),该框架通过引入打分函数来预测并剪枝无效的节点转换,从而减少不必要的计算开销。具体来说:
-
节点级转换(Node-level Transformations):逻辑优化启发式算子(如Mfs2)通常会对电路中的每个节点依次应用转换。然而,许多转换是无效的,即它们不会对电路的优化结果产生实质性影响。 -
打分函数的作用:打分函数用于评估每个节点的转换是否有效。通过预测并剪枝无效的节点转换,可以显著减少启发式算法的计算量,从而提升优化效率。
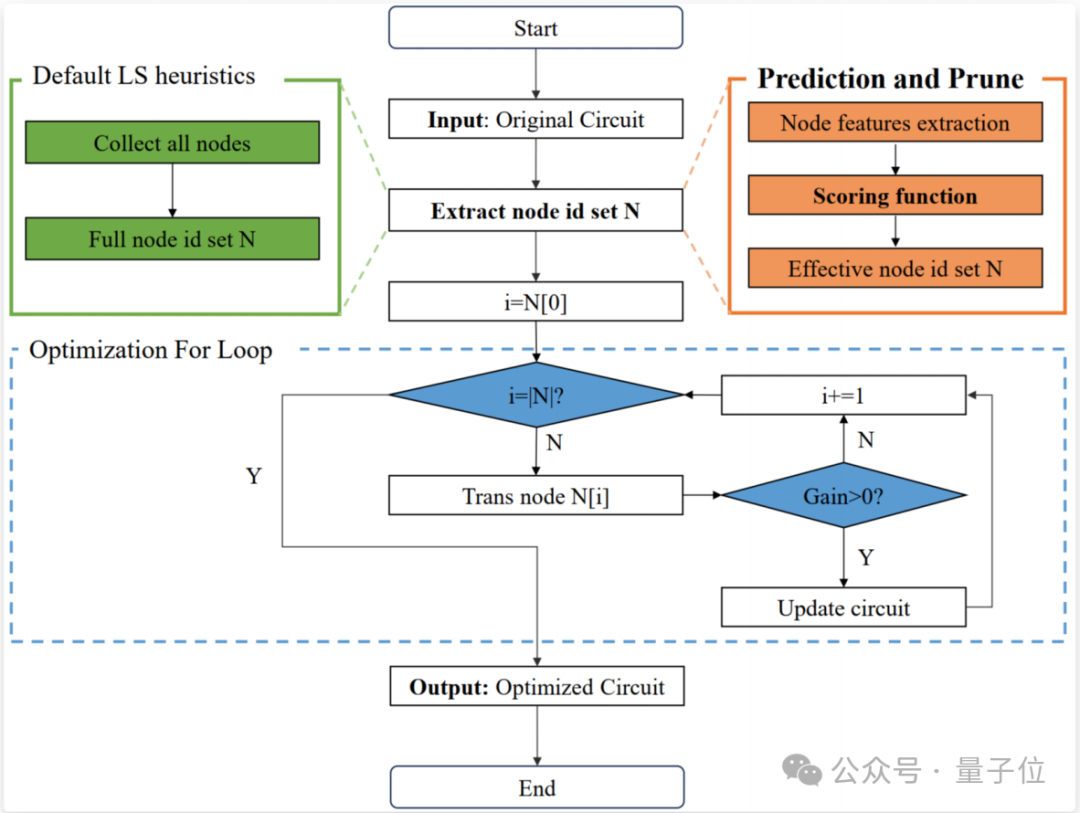
△图1.逻辑优化中的预测与剪枝框架
然而,现有的评分函数在以下几个方面存在局限性:
1.推理效率:基于深度学习的评分函数(如GNN)虽然预测准确率高,但其推理时间长,在纯CPU环境的大规模工业电路上推理时间最高可占算子运行时间的30%,因此难以满足工业需求。
2.可解释性:深度学习模型(如GNN)的“黑箱”特性使得其在实际应用中的可靠性受到质疑。
3.泛化性能:人工设计的评分函数虽然具有可解释性,但其泛化性能较差,难以适应不同电路的特性。
为了解决这些问题,本文提出了CMO框架,通过学习轻量级、可解释且泛化能力强的符号函数来优化逻辑综合算子。
方法
为了挖掘轻量化符号打分函数,首先提出了数据驱动的神经符号学习框架(Circuit Symbolic Learning framework, CMO),在CMO中的核心技术贡献是图增强的蒙特卡洛树搜索方案(Graph Enhanced Symbolic Discovery Framework, GESD),通过学习图神经网络内蕴的知识以提升符号函数的泛化能力。
1.数据驱动的神经符号学习框架-CMO
如图2所示,CMO描述了该研究整个符号函数学习与实际部署的pipeline。
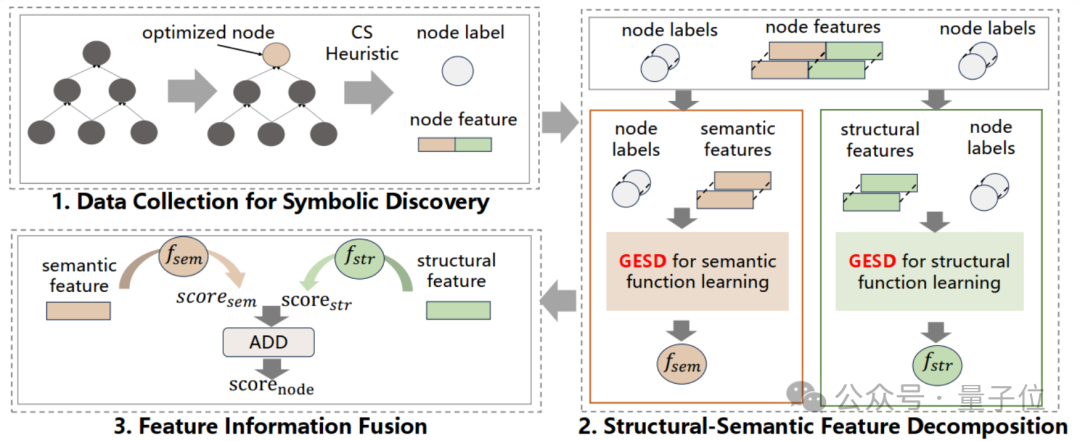
△数据驱动的神经符号学习框架CMO
数据收集
通过应用逻辑优化启发式算法(如Mfs2)对电路进行优化,生成数据集。对于电路中的每个节点,生成一个数据对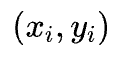 ,其中
,其中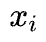 是节点特征,
是节点特征,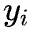 是标签(如果节点转换有效则标签为1,否则为0)。
是标签(如果节点转换有效则标签为1,否则为0)。
对于一个给定的电路图,收集到的数据为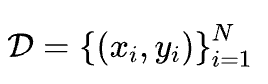 ,目标是从中学习轻量且可解释的符号函数。
,目标是从中学习轻量且可解释的符号函数。
结构-语义特征分解
对于节点特征的设计,研究团队参考了[5]的设计,将节点特征设计为了包含图结构与图语义信息的高维特征。其中,结构特征包含电路的拓扑信息(如节点的层级、扇入/扇出数等),而语义特征包含功能信息(如节点的真值表)。然而,高维特征会导致搜索空间急剧增加,为了解决这一问题,提出了结构-语义特征分解策略。团队观察到结构特征是连续的,适合数学符号回归;而语义特征是离散的,适合布尔符号学习。因此,将特征分离并分别使用不同的符号回归方案学习,显著减少了符号搜索空间,并从结构与语义两个维度集成信息,有利于模型泛化性能的提升。
神经符号函数学习
-
结构函数学习:对于连续的结构特征
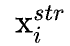 ,该函数将结构特征映射为连续值。
,该函数将结构特征映射为连续值。 -
语义函数学习:对于离散的语义特征
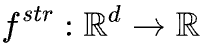 ,该函数将语义特征映射为离散值。
,该函数将语义特征映射为离散值。
特征信息融合
在测试阶段,将训练得到的结构函数与语义函数同时作为部署模型,并将结构函数和语义函数的输出融合,得到节点的最终分数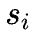 :
:
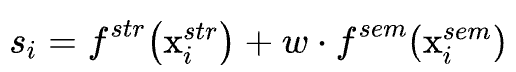
其中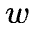 是一个权重参数,用于平衡两种特征的重要性。
是一个权重参数,用于平衡两种特征的重要性。
2.图增强的蒙特卡洛树符号搜索方案-GESD
在CMO中,如何从给定的电路数据中发现具有强泛化能力的符号函数是一个关键问题。为此,提出了首个图增强的蒙特卡洛树符号搜索方案——GESD(如图3所示)。
该方案通过图神经网络(GNN)指导蒙特卡洛树的生成,巧妙结合了图神经网络的高泛化能力与符号函数的轻量化优势,从而显著提升了符号函数的泛化性能。
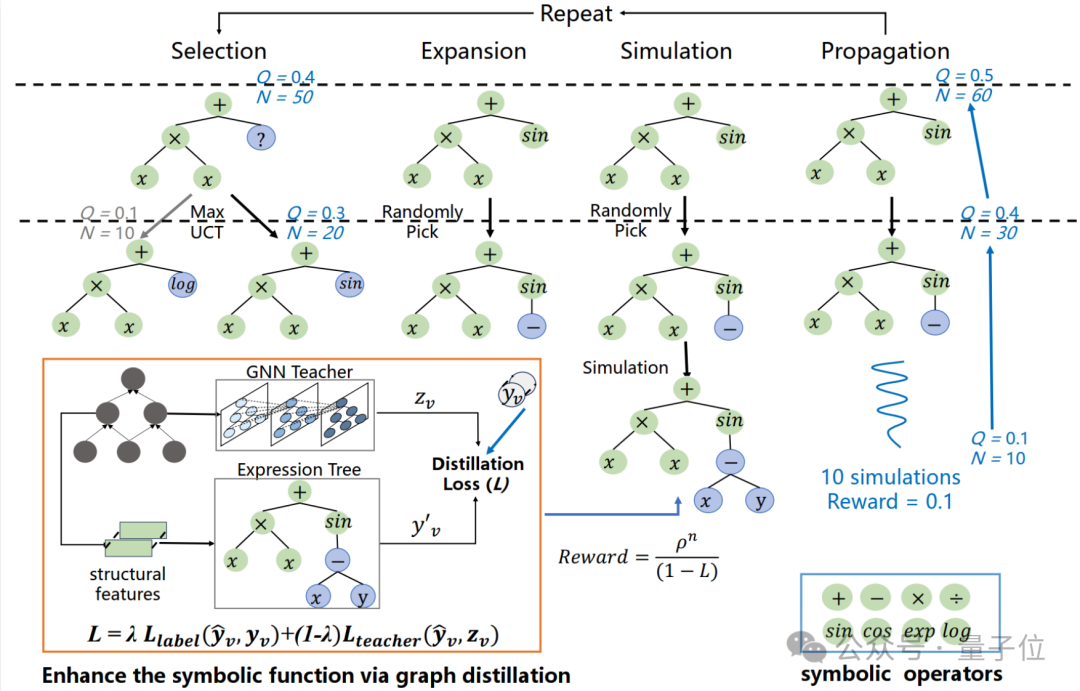
△图3. 图增强的蒙特卡洛树符号搜索方案GESD
符号树生成
-
符号操作符:在生成符号函数之前,需要定义搜索中使用的符号。用于生成结构表达式树的数学运算符包括:{+, −, ×, ÷, log, exp, sin, cos}。团队没有使用占位符来生成常数,因为引入内部常熟优化循环通常会导致 更高的训练成本。此外,团队发现像exp、sin、cos等复杂操作符能够有效提升符号函数的预测性能。对于生成语义表达式树的布尔运算符包括:{与,或,非},通过与或非的组合能够拟合任意一个布尔表达式。
-
蒙特卡洛树搜索:受到蒙特卡洛树搜索(MCTS)在有效探索大型复杂符号空间方面的优势启发(Sun等,2023;Xu等,2024),使用符号表达式树来表示符号函数通过表达式树并利用MCTS生成符号树。对于一棵符号树,他的内部节点是数学运算符(如加、减、乘、除、对数、指数等),叶子节点是输入变量或常数。定义状态(s)为当前表达式树的先序遍历,动作(a)为添加到状态中的符号操作符或变量。具体来说,此研究中的MCTS包括四个步骤:选择、扩展、模拟和反向传播。
1.选择:在选择阶段,MCTS代理遍历当前表达式树,选择具有最大UCT值的动作。为了确保生成表达式的合法性,在当前状态下,MCTS代理会屏蔽掉当前非终端节点的无效动作,并在此基础上选择一个有效的动作作为。
2.扩展:当选择阶段达到一个可扩展节点——即它的子节点并非全部已被访问——MCTS代理会通过随机选择一个未访问的有效子节点来扩展该节点。
3.模拟:在当前状态和扩展节点的基础上,通过随机选择下一个节点进行仿真,直到表达式树完成。具体来说,进行10次仿真,并返回最大仿真奖励,而不是传统MCTS算法中的平均奖励,以找到唯一的最优符号解,这是一种与传统MCTS算法不同的贪婪搜索启发式方法。
4.反向传播:仿真结束后,更新路径中从当前节点到根节点的最大奖励Q和访问次数N。该搜索算法会不断重复上述步骤,直到满足停止准则。
图增强符号函数
-
教师-学生框架:
引入图神经网络(GNN)作为教师模型,通过蒸馏GNN的“暗知识”来增强符号函数的泛化能力。具体来说,首先在训练数据集上训练一个GNN,该GNN能够有效捕捉电路中的复杂结构和语义信息,从而解决由于电路领域分布大幅度变化而导致的泛化能力差的问题。然后,利用GNN的预测输出和真实标签来指导符号函数的学习过程。
这种教师-学生框架的核心思想是通过GNN的高泛化能力来引导符号函数的生成,从而弥补传统符号方法在泛化性能上的不足。
-
奖励函数设计:
在MCTS的模拟阶段,使用以下奖励函数评估符号函数: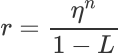
其中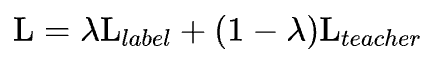 是基于标签的损失,用于确保符号函数的预测结果与真实标签一致;
是基于标签的损失,用于确保符号函数的预测结果与真实标签一致;
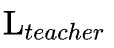 是基于GNN输出的损失,用于将GNN的泛化能力迁移到符号函数中。通过调整权重
是基于GNN输出的损失,用于将GNN的泛化能力迁移到符号函数中。通过调整权重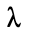 可以平衡标签信息和教师知识的重要性。此外,
可以平衡标签信息和教师知识的重要性。此外,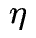 是一个惩罚因子,用于控制符号函数的复杂度,确保生成的符号函数既简洁又高效。
是一个惩罚因子,用于控制符号函数的复杂度,确保生成的符号函数既简洁又高效。
-
图蒸馏
通过最小化符号函数输出与GNN输出之间的均方误差(MSE),将GNN的泛化能力迁移到符号函数中。与以往使用KL散度的方法不同,MSE能够直接学习GNN输出的泛化信息,从而实现与GNN相当的泛化性能。具体来说,研究团队发现电路特征与GNN输出之间存在简单的非线性映射关系,这使得符号函数能够在不牺牲性能的情况下保持轻量化。
此外,针对电路数据中正负样本严重不平衡的问题,采用焦点损失(Focal Loss)作为学生模型的损失函数,进一步提升符号函数的学习效果。焦点损失通过调整难易样本的权重,有效缓解了样本不平衡带来的负面影响,从而提高了符号函数在稀疏数据上的表现。
实验结果
在实验部分,在两个广泛使用的开源电路数据集(EPFL和IWLS)以及一个工业电路数据集上进行了全面测试。实验结果表明,该方法在多个方面表现出色:
1.效率提升:CMO框架显著提升了传统关键逻辑优化算子(如Mfs2)的运行效率,最高可达2.5倍加速。例如,在超大规模电路Sixteen上,CMO-Mfs2将运行时间从78,784秒减少到32,001秒,提升了约59.4%。
2.优化质量提升:通过在相同时间内多次运行CMO驱动的新型算子(如2CMO-Mfs2),进一步提升了电路的优化质量(QoR)。具体来说,电路的规模和深度得到了显著改善,其中电路深度的最大优化幅度达到30.23%。例如,在Hyp电路上,2CMO-Mfs2将电路深度从8,259层减少到5,762层,显著降低了电路的延迟。
这些实验结果充分证明了CMO框架在提升逻辑优化效率和质量方面的双重优势,为芯片设计中的逻辑优化任务提供了强有力的支持。
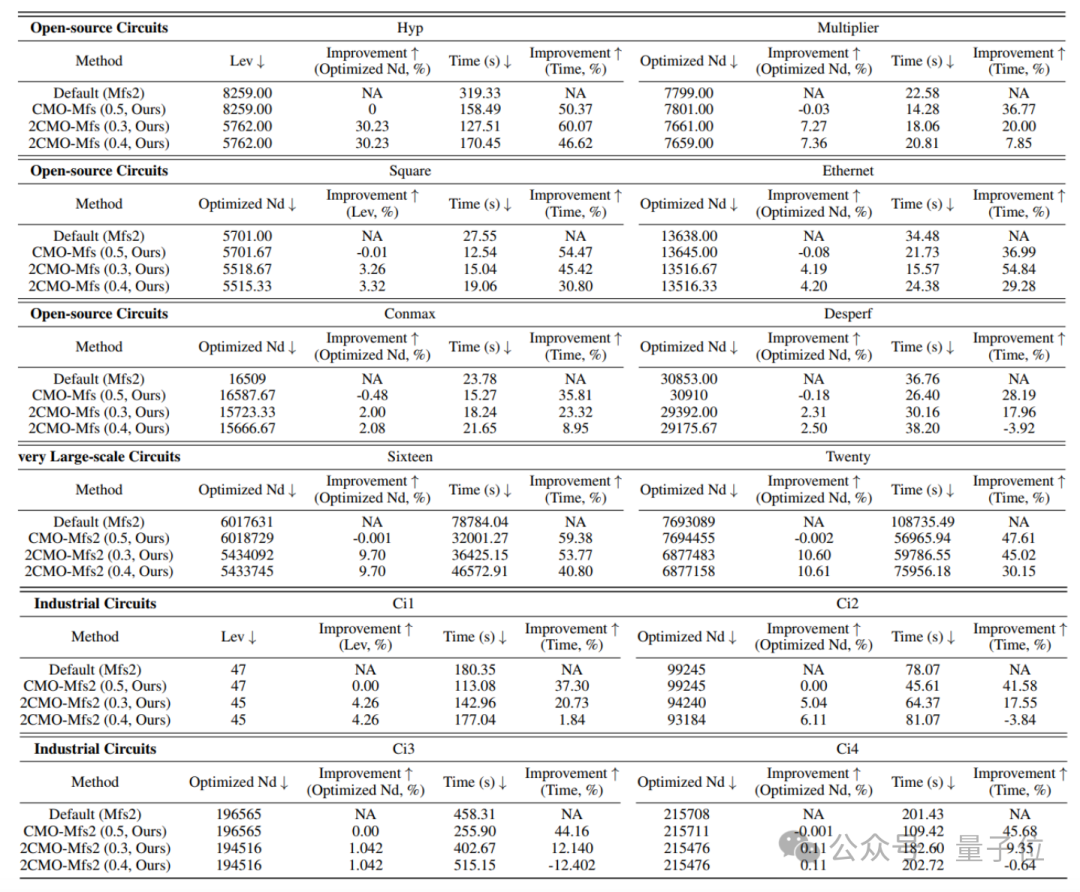
△表1.实验结果表明该方法不仅能够提升算子效率,同时还能够提升算子优化质量
本论文作者白寅岐是中国科学技术大学2024级硕士生,师从王杰教授,主要研究方向为人工智能驱动的芯片设计、图机器学习、大模型等。他曾在人工智能顶级会议ICML、Neurips等会议上发表论文两篇,本科期间曾获首批国家青年学生基础研究项目资助(全国108人)。
论文地址:https://openreview.net/forum?id=EG9nDN3eGB
代码地址:https://gitee.com/yinqi-bai/cmo
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
(文:量子位)