

近年来,端到端(End-to-End,E2E)自动驾驶技术不断进步,但在复杂的闭环交互环境中,由于其因果推理能力有限,仍然难以做出准确决策。虽然视觉 – 语言大模型(Vision-Language Model,VLM)凭借其卓越的理解和推理能力,为端到端自动驾驶带来了新的希望,但现有方法在 VLM 的语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。
除此之外,现有的方法常常通过叠加多帧的图像信息完成时序建模,这会受到 VLM 的 Token 长度限制,并且会增加额外的计算开销。
为了解决上述问题,本文提出了 ORION,这是一个通过视觉语言指令指导轨迹生成的端到端自动驾驶框架。ORION 巧妙地引入了 QT-Former 用于聚合长期历史上下文信息,VLM 用于驾驶场景理解和推理,并启发式地利用生成模型对齐了推理空间与动作空间,实现了视觉问答(VQA)和规划任务的统一端到端优化。
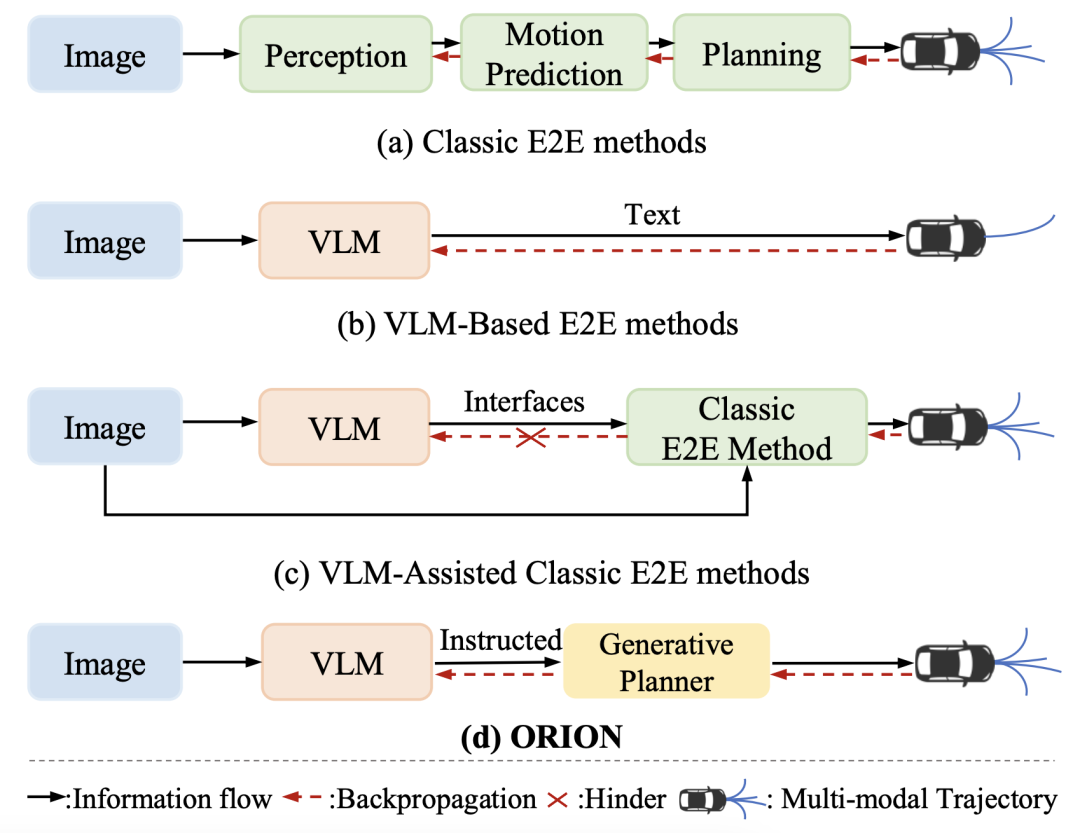
图 1:不同的端到端自动驾驶范式的对比
ORION 在具有挑战性的闭环评测 Bench2Drive 数据集上实现了优秀的性能,驾驶得分为 77.74 分,成功率为 54.62%,相比之前的 SOTA 方法分别高出 14.28分和 19.61% 的成功率。
此外,ORION 的代码、模型和数据集将很快开源。

-
论文标题:ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
-
论文地址:https://arxiv.org/abs/2503.19755
-
项目地址:https://xiaomi-mlab.github.io/Orion/
-
代码地址:https://github.com/xiaomi-mlab/Orion
-
单位:华中科技大学、小米汽车
我们来看一下 ORION 框架下的闭环驾驶能力:
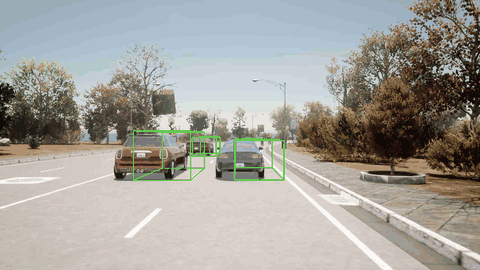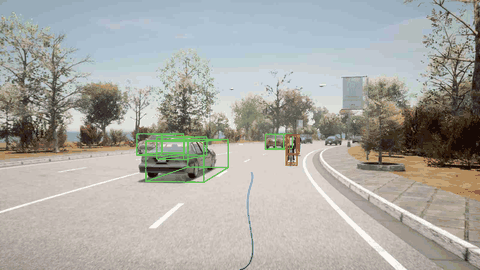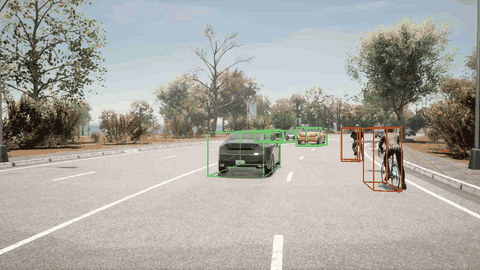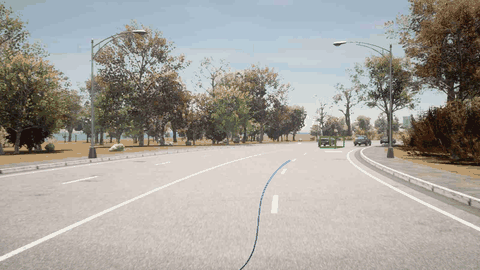
ORION 检测到骑自行车的人并向左变道避免了碰撞。
ORION 检测到右前方的车辆,先执行减速,然后再改变车道。

ORION 识别停车标志并停车,等待一段时间,然后重新启动成功通过十字路口。

主要贡献
本文提出了一个简单且有效的端到端自动驾驶框架 ORION,主要包含如下几方面的贡献:
-
VLM + 生成模型:利用生成模型弥补了 VLM 的推理空间与轨迹的动作空间之间的差距,从而使 ORION 能够理解场景并指导轨迹生成。
-
QT-Former:引入 QT-Former 聚合历史场景信息,使模型能够将历史信息整合到当前推理和动作空间中。
-
可扩展性:ORION 可以与多种生成模型兼容,实验证明了所提出框架的灵活性。
-
性能优异:在仿真数据集 Bench2drive 的闭环测试上取得 SOTA 的性能。
研究动机
经典的 E2E 自动驾驶方法通过多任务学习整合感知、预测和规划模块,在开环评估中表现出优秀的能力。然而,在需要自主决策和动态环境交互的闭环基准测试中,由于缺少因果推理能力,这些方法往往表现不佳。
近年来,VLM 凭借其强大的理解和推理能力,为 E2E 自动驾驶带来了新的解决思路。但直接使用 VLM 进行端到端自动驾驶也面临诸多挑战,例如,VLM 的能力主要集中在语义推理空间,而 E2E 方法的输出是动作空间中的数值规划结果。
一些方法尝试直接用 VLM 输出基于文本的规划结果,但 VLM 在处理数学计算和数值推理方面存在不足,且其自回归机制导致只能推断单一结果,无法适应复杂场景。还有些方法通过设计接口,利用 VLM 辅助经典 E2E 方法,但这种方式解耦了 VLM 的推理空间和输出轨迹的动作空间,阻碍了两者的协同优化。
除此之外,长期记忆对于端到端自动驾驶是必要的,因为历史信息通常会影响当前场景中的轨迹规划。现有使用 VLM 进行端到端自动驾驶的方法通常通过拼接多帧图像来进行时间建模。但这会受到 VLM 的输入 Token 的长度限制,并且会增加额外的计算开销。
为了解决上述问题,本文提出了 ORION。ORION 的结构包括 QT-Former、VLM 和生成模型。 ORION 通过 QT-Former 聚合长时间上下文信息,并巧妙地结合了生成模型和 VLM,有效对齐了推理空间和动作空间,实现了视觉问答(VQA)和规划任务的统一端到端优化。
方法概览
具体来说,ORION 通过以下三大核心模块,显著提升了自动驾驶系统的决策能力:
1. QT-Former:长时序上下文聚合
ORION 引入了 QT-Former,通过引入历史查询和记忆库,有效聚合长时视觉上下文信息,增强了模型对历史场景的理解能力。相比现有方法,QT-Former 不仅减少了计算开销,还能更好地捕捉静态交通元素和动态物体的运动状态。
2. VLM:场景推理与指令生成
ORION 利用 VLM 的强大推理能力,结合用户指令、长时和当前的视觉信息,能够对驾驶场景进行多维度分析,包括场景描述、关键物体行为分析、历史信息回顾和动作推理,并且利用自回归特性聚合整个场景信息以生成规划 token,用来指导生成模型进行轨迹预测。
3. 生成模型:推理与动作空间对齐
ORION 通过生成模型,将 VLM 的推理空间与预测轨迹的动作空间对齐。生成模型使用变分自编码器(VAE)或扩散模型,以规划 token 作为条件去控制多模态轨迹的生成,确保模型在复杂场景中做出合理的驾驶决策。
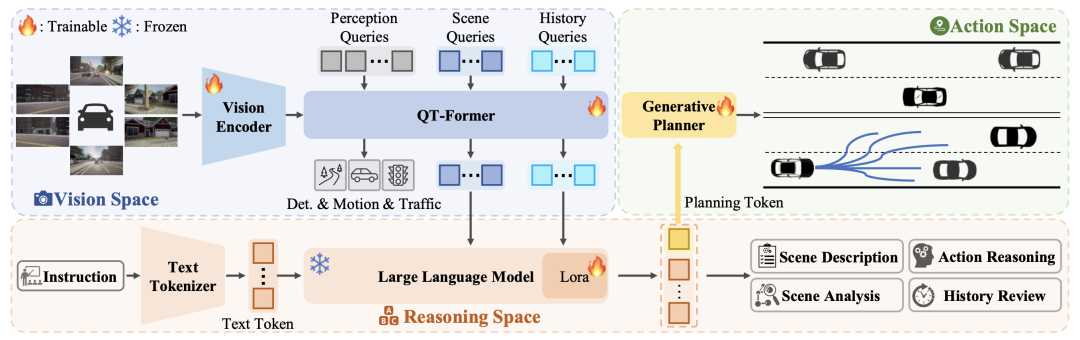
图 2:ORION 整体架构图
实验结果
本文在 Bench2Drive 数据集上进行闭环评估测试,如表 1 所示,ORION 取得了卓越的性能,其驾驶得分(DS)和成功率(SR)分别达到了 77.74 和 54.62%,相比现在的 SOTA 方法提升了 14.28 DS 和 19.61% SR,展现了 ORION 强大的驾驶能力。
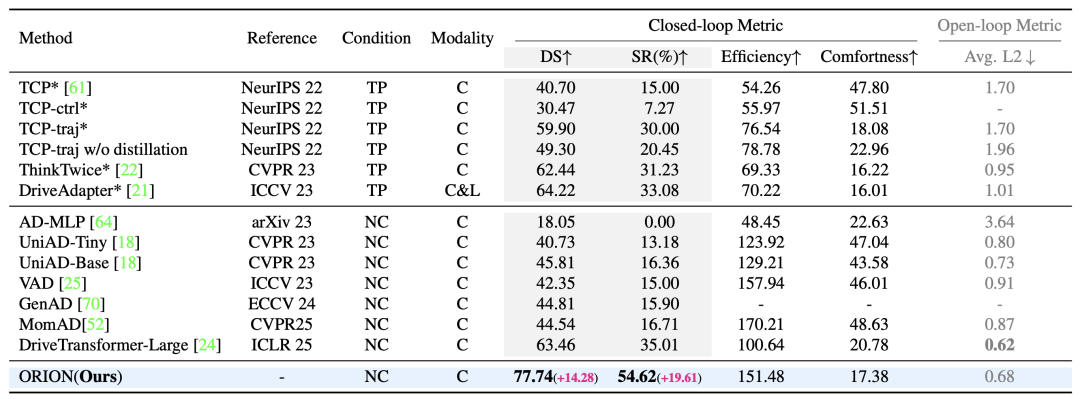
表 1:Bench2Drive 上闭环评估和开环评估的性能对比
此外,如表 2 所示,ORION 还在 Bench2Drive 的多能力评估中表现优异,特别是在超车(71.11%)、紧急刹车(78.33%)和交通标志识别(69.15%)等场景中,ORION 的表现远超其他方法。这得益于 ORION 通过 VLM 对驾驶场景的理解,能够更好地捕捉驾驶场景之间的因果关系。
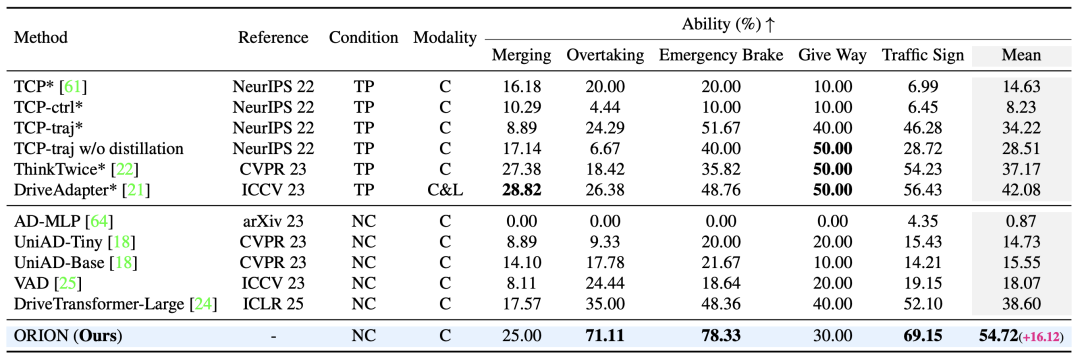
表 2:Bench2Drive 上多能力评估测试对比
可解释性结果
下图展示了 ORION 在 Bench2Drive 的闭环评估场景中的可解释性结果。ORION 可以理解场景中正确的因果关系,并做出准确的驾驶决策,然后根据推理信息指导规划轨迹预测。
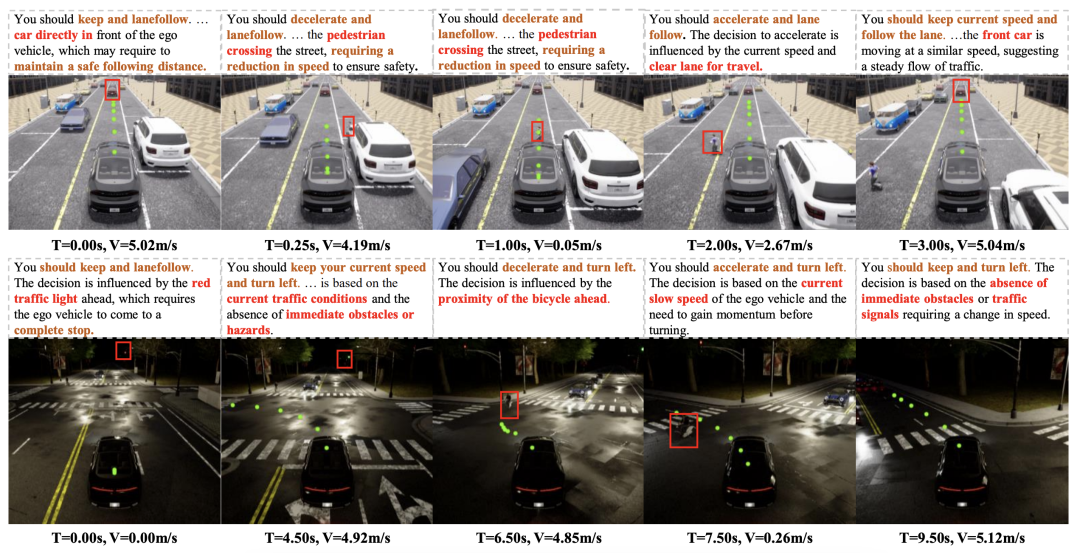
图 3:可解释性结果图
总结
ORION 框架为端到端自动驾驶提供了一种全新的解决方案。ORION 通过生成模型实现语义与动作空间对齐,引入 QT-Former 模块聚合长时序场景上下文信息,并联合优化视觉理解与路径规划任务,在闭环仿真中取得了卓越的性能。
©
(文:机器之心)