


OmniSVG与SOTA方法比较
-
文本转SVG

-
图像转SVG

-
字符参考 SVG

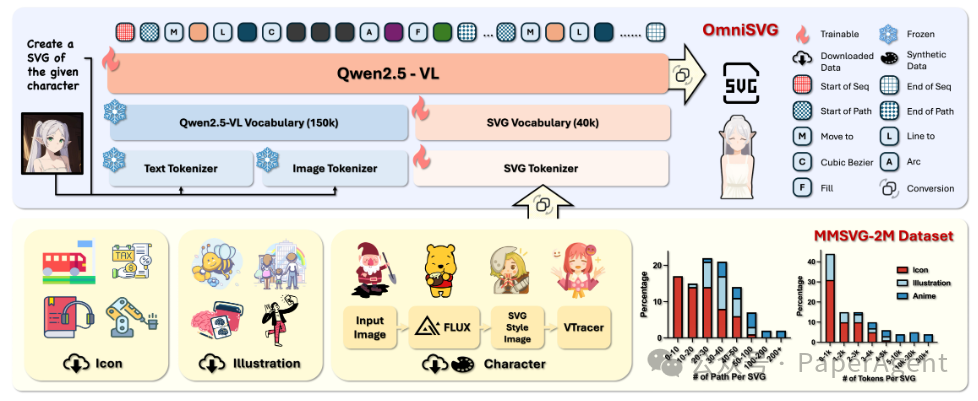
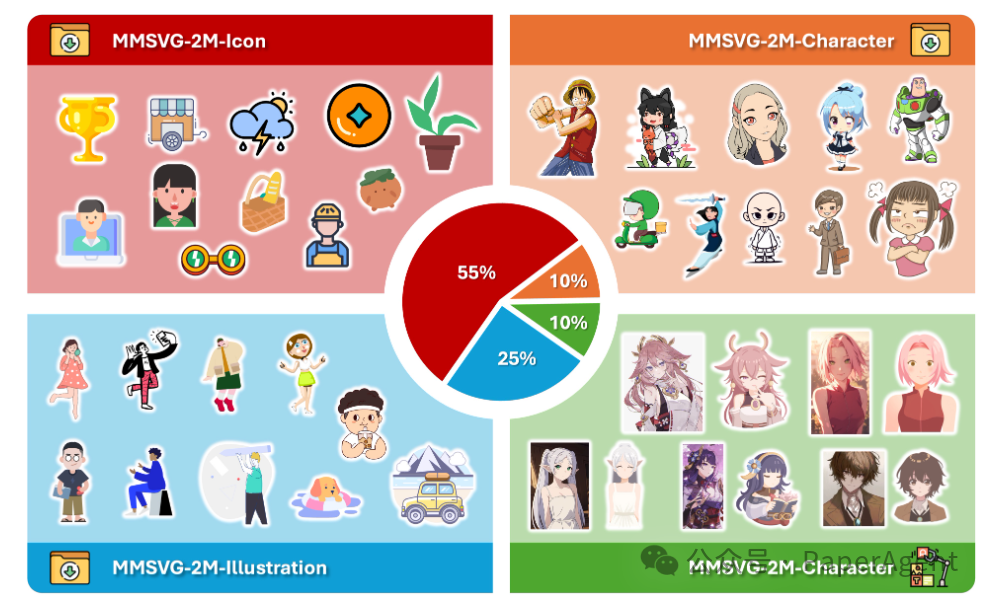
MMSVG-2M数据集
https://arxiv.org/pdf/2504.06263OmniSVG: A Unified Scalable Vector Graphics Generation Modelhttps://omnisvg.github.io/https://huggingface.co/OmniSVG
(文:PaperAgent)

https://arxiv.org/pdf/2504.06263OmniSVG: A Unified Scalable Vector Graphics Generation Modelhttps://omnisvg.github.io/https://huggingface.co/OmniSVG
(文:PaperAgent)