


周六(4 月 5 日)发布了”羊驼”家族的全新版本 Llama 4 Scout 和 Llama 4 Maverick,以及两款未来会发布的 Llama 4 Reasoning 和 Llama 4 Behemoth 模型。

这里快速给大家介绍一下 Llama4 的特点。 按照 Meta 的官方新闻稿, Llama4 是其迄今为止最先进、功能最强大的多模态 AI 模型。
Llama 4 Scout:
-
规模与架构: 170 亿活跃参数,16 个专家(MoE 架构),总参数 1090 亿。可在单张 NVIDIA H100 GPU 上运行(Int4 量化)。 -
性能: 同级别中最佳的多模态模型,优于所有前代 Llama 模型,以及 Gemma 3, Gemini 2.0 Flash-Lite, Mistral 3.1。 -
特点: 拥有行业领先的 1000 万 token 上下文窗口,擅长长文本处理、多文档摘要、图像定位(grounding)等。
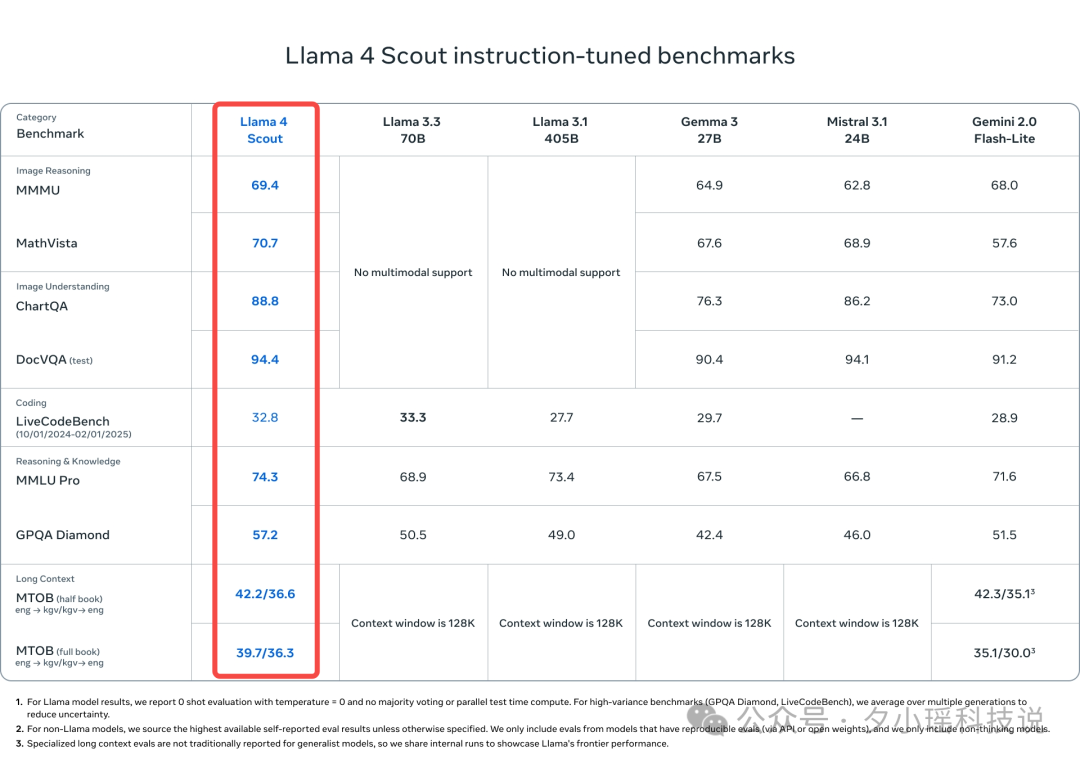
Llama 4 Maverick:
-
规模与架构: 170 亿活跃参数,128 个专家(MoE 架构),总参数 4000 亿。可在单台 NVIDIA H100 主机上运行。 -
性能: 同级别中最佳的多模态模型,在广泛基准上击败 GPT-4o 和 Gemini 2.0 Flash。在推理和编码方面与参数量大一倍多的 DeepSeek v3 相当。 -
特点: 具有出色的性能成本比,特别适合作为通用助手和聊天应用,擅长精确图像理解和创意写作。
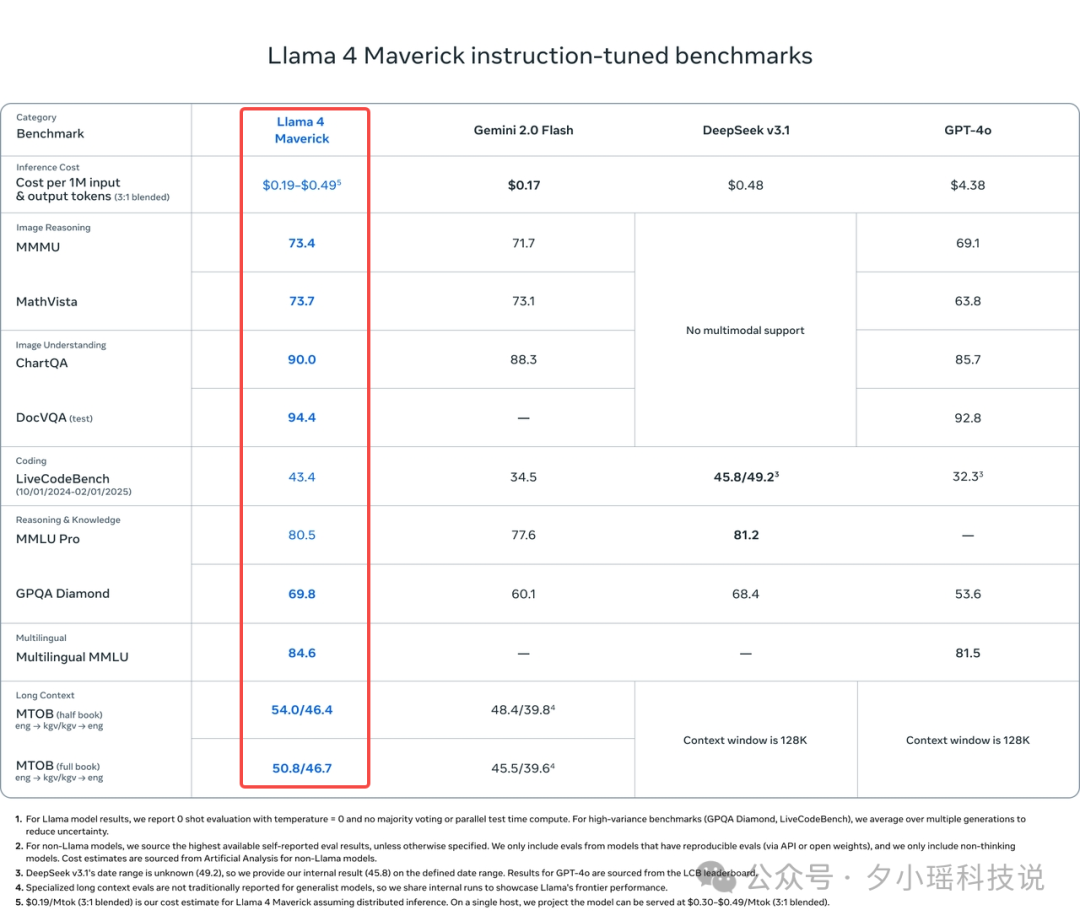
Llama 4 Behemoth(尚未发布)
-
规模与架构: 2880 亿活跃参数,16 个专家(MoE 架构),总参数近 2 万亿。 -
定位: Meta 最强大的模型之一,目前仍在训练中,暂不发布。作为 Scout 和 Maverick 的 “教师模型” 进行知识蒸馏。 -
性能: 在多个 STEM 基准(如 MATH-500, GPQA Diamond)上优于 GPT-4.5, Claude Sonnet 3.7, Gemini 2.0 Pro。
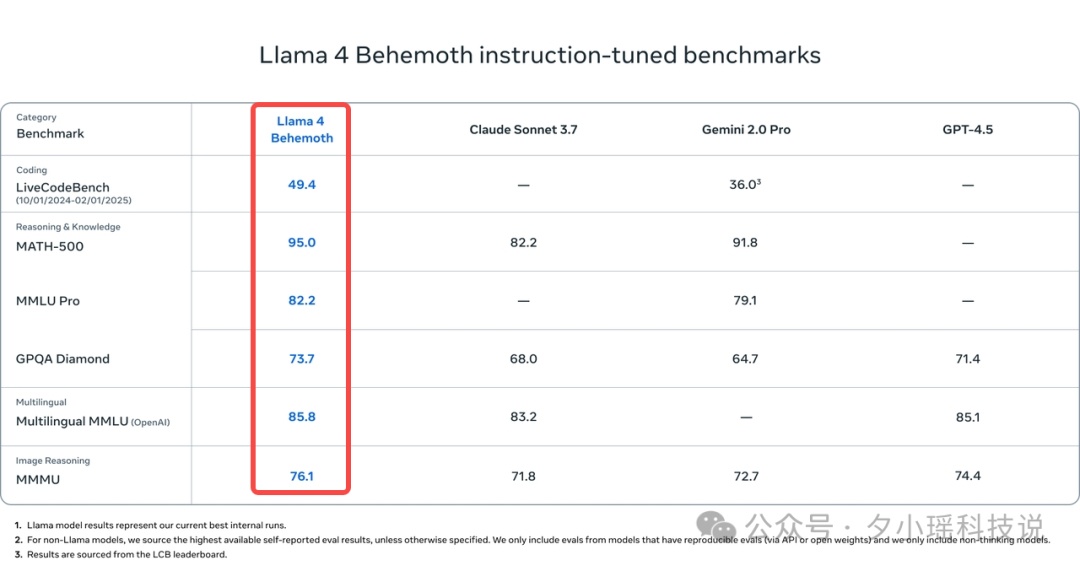
小扎对自己的新模型表现的很激动,专门录制了视频进行介绍并分享了公司的人工智能愿景:
“我们的目标是打造全球领先的人工智能,开源它,并使其普遍可用……我一直以来都说,开源人工智能将引领未来,而随着 Llama 4 的推出,我们正开始看到这一点的实现。”

在大模型领域,自吹自擂是没用的,大家都说好,那才是真的好。这不,目前已经有热心的第三方进行了测评,这个结果我不什么也不说,大家看截图:
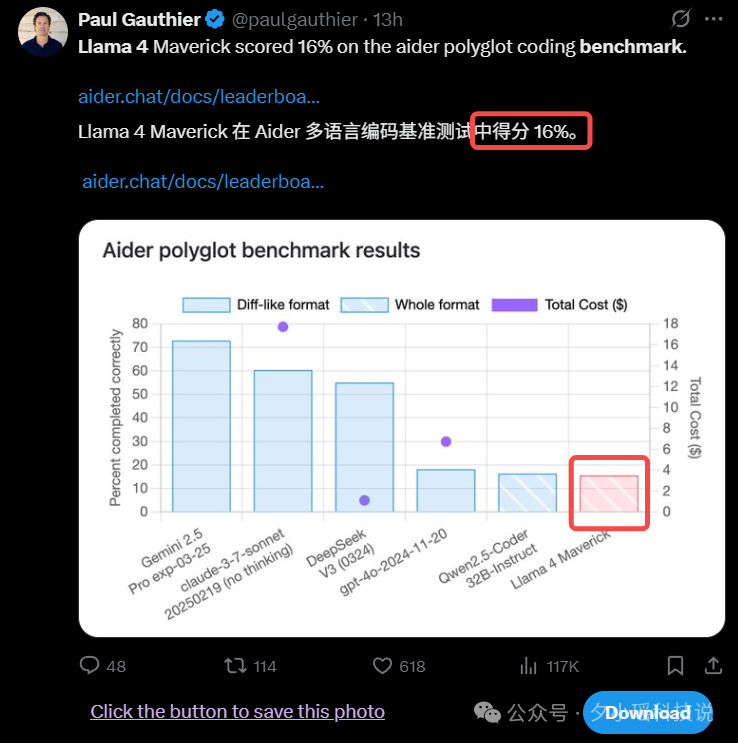
Llama 4 Maverick 在 Aider 的变成测试中的得分要远低于 DeepSeek V3-0324。
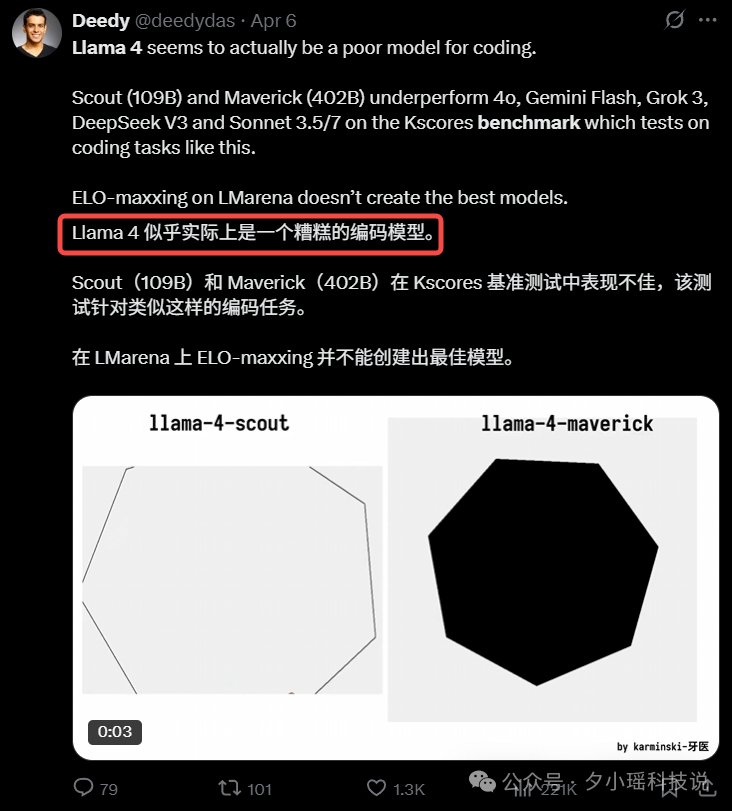
上面的两个实际编程例子也是差的一塌糊涂。
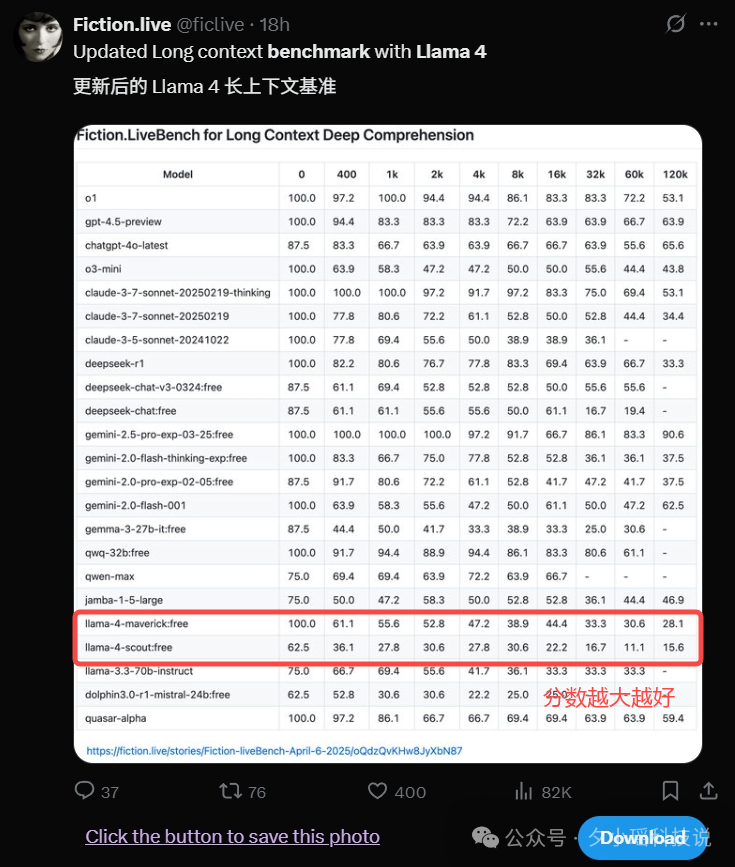
在 Llama 4 这次引以为傲长上下文中也表现平平,接近于垫底。
小编我也是经历过很多模型发布后实测效果与官方公布效果不符的情况。但说实话,这种一边倒的情况还是第一次碰到,甚至让我一度怀疑自己是不是进入到了信息茧房之中。
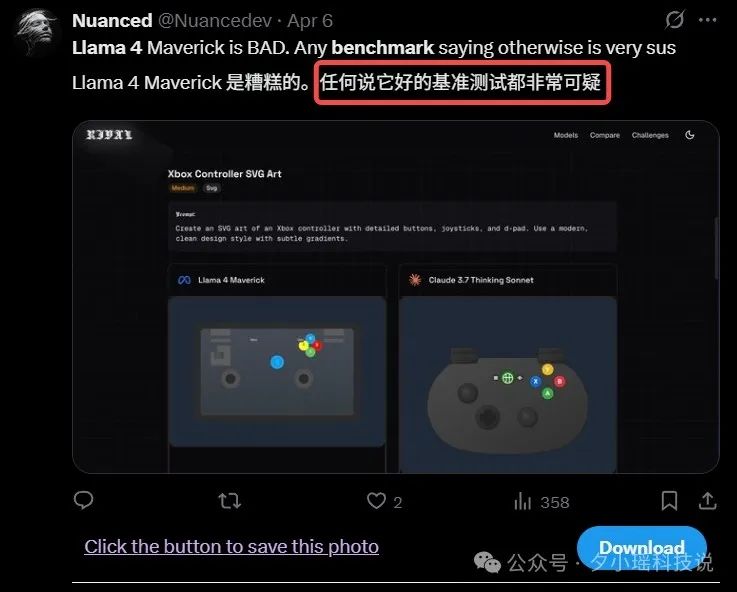
你以为这就完了? 还有说法是 Llama4 针对测评“优化”了特殊版本。
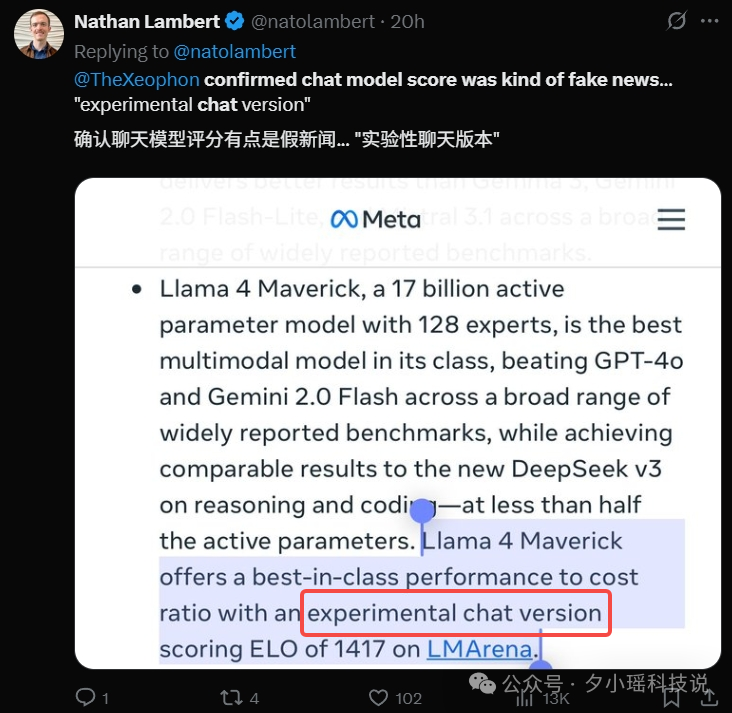
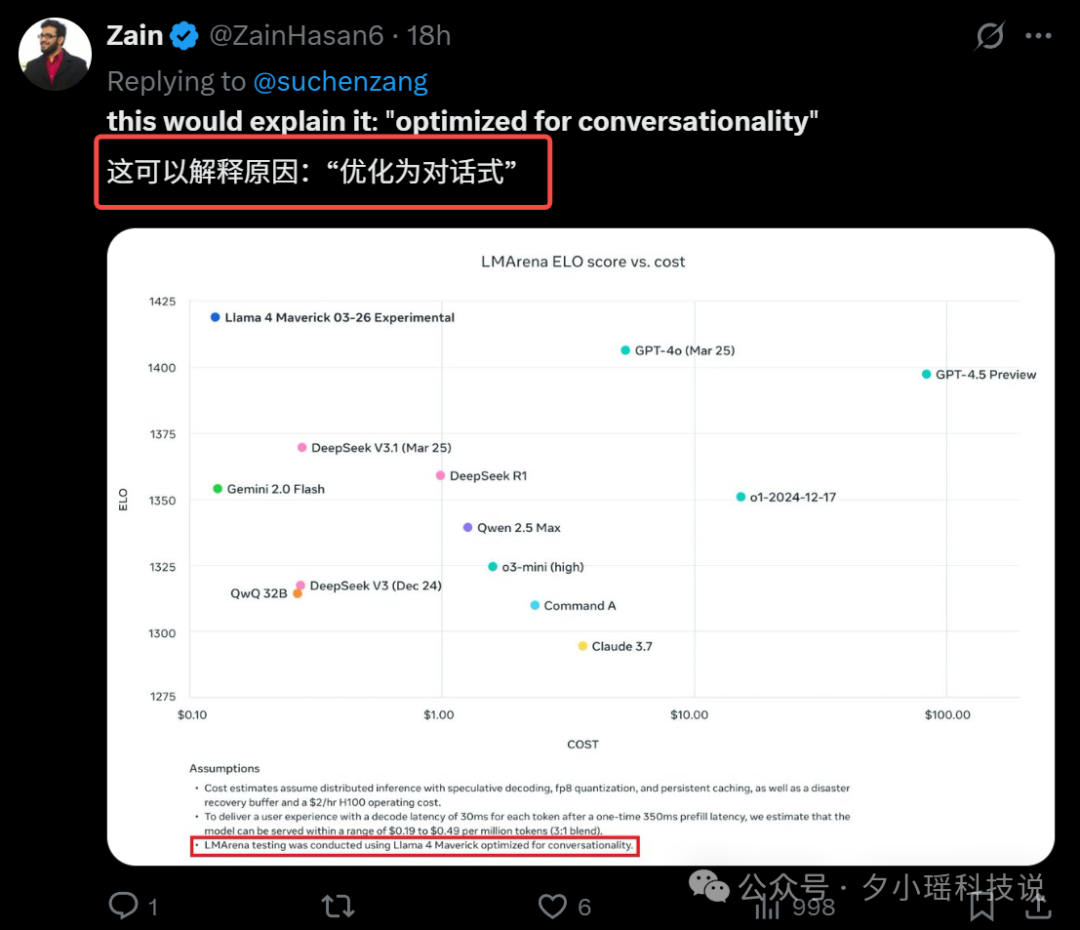
这种针对测评进行优化,就相当于考试出原题,不能说是作弊吧,但也在一定程度上让人对 Llama4 的技术指标产生怀疑。
本着实事求是的原则,模型效果咋样,试试一切就清楚了,所以我们对 Llama 4 进行了史无前例的测试,可以说是鞭尸现场。(以下请慎看)
说明: Llama 4 官方的使用渠道是 Meta.ai, 但不知道出于什么原因,该网站我用任何技术手段都没办法访问。
所以我们使用的是基于 Openrouter 的第三方平台提供的模型,并用 Cherry Studio 作为前端。
为了最直观的比较模型效果,我们这次测试题目直接复用上一期测评的题目。
Round 1:跑酷游戏
提示词:
Make me a captivating endless runner game. Key instructions on the screen. p5js scene, no HTML. I like pixelated dinosaurs and interesting backgrounds.
中文提示词:
为我制作一个引人入胜的无限跑酷游戏。屏幕上显示关键操作说明。使用 p5js 场景,无需 HTML。我喜欢像素化的恐龙和有趣的背景。
先看 Llama 4 Scout:
这是 Lllama 4 Maverick:
Scout 和 Maverick 的结果都不尽人意, 这俩兄弟做出来的都不是一个可以玩的游戏,不知道是 bug 还是没有理解我的意思,它们的问题都是障碍物没有碰撞的判定。
作为对比,我们看下 DeepSeek V3-0324 的结果:
这个游戏不但可玩,没有碰到 bug,而且是还是一次就成功结果,高下立判!
Round 2: 小球弹跳
这个测试项目已经不是什么新鲜项目了,看看 Llama4 能否秒杀。
提示词如下:
Create an effect using p5.js (no HTML needed) where 10 colorful balls bounce inside a rotating hexagon, taking into account gravity, elasticity, friction, and collisions.
使用 p5.js(无需 HTML)创建 10 个彩色球在旋转六边形内弹跳的效果,考虑重力,弹性,摩擦和碰撞。
先看 Llama 4 Scout:
整了个大无语,我就不说什么了!!
再看 Llama 4 Maverick:
看看 DeepSeek V3-0324:
DeepSeek V3-0324 也无法一次过,只能说它们在这个项目打了个平手。
Round 3: 飞行模拟游戏
提示词如下:
In pure three.js, without downloading any assets or textures, create a flight simulator game where i can fly an airplane. Make sure it runs in the browser
先看 Llama 4 Scout 的代码:
为什么展示代码,不展示运行结果? 因为,这代码运行结果就是黑屏!
这是 Llama 4 Maverick 的:
还是无法运行!!!
这是 DeepSeek V3-0324:
DeepSeek V3 的结果不完美,但至少是一个能运行的版本,而且完成度还挺高,基本操作都没有问题。
测到这里,我有点心慌,怕你们说我是故意黑 Llama 4。 但真的,Meta.ai 的用不上,Openrouter 上的就是这个效果。
Round 4: 生成 Mandelbrot set 集
提示词如下:
p5js to explore a Mandelbrot set.
用 p5js 生成 Mandelbrot set.
这一轮我已经放弃了 Scout, 直接看 Llama 4 Maverick 的:
DeepSeek V3-0324 的效果——
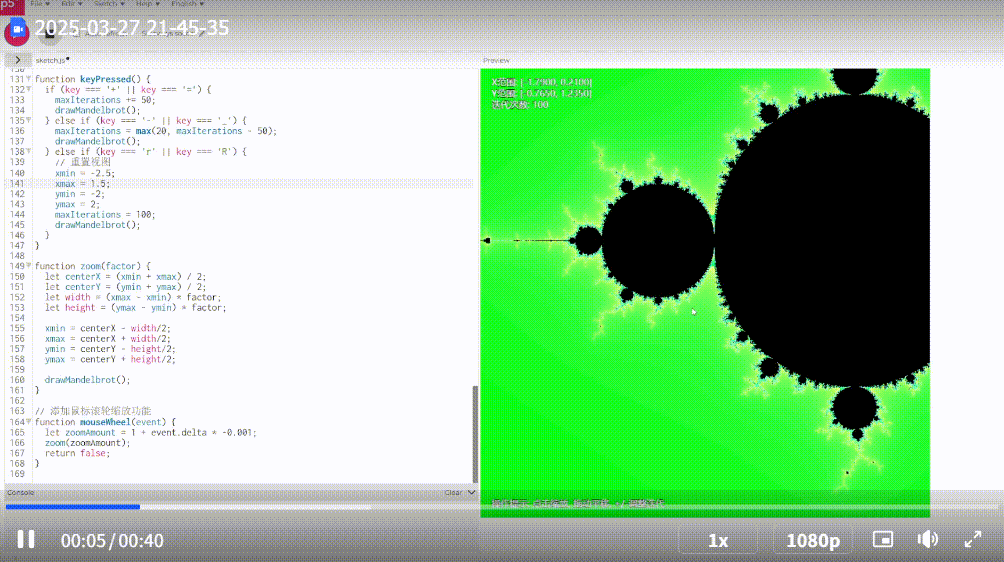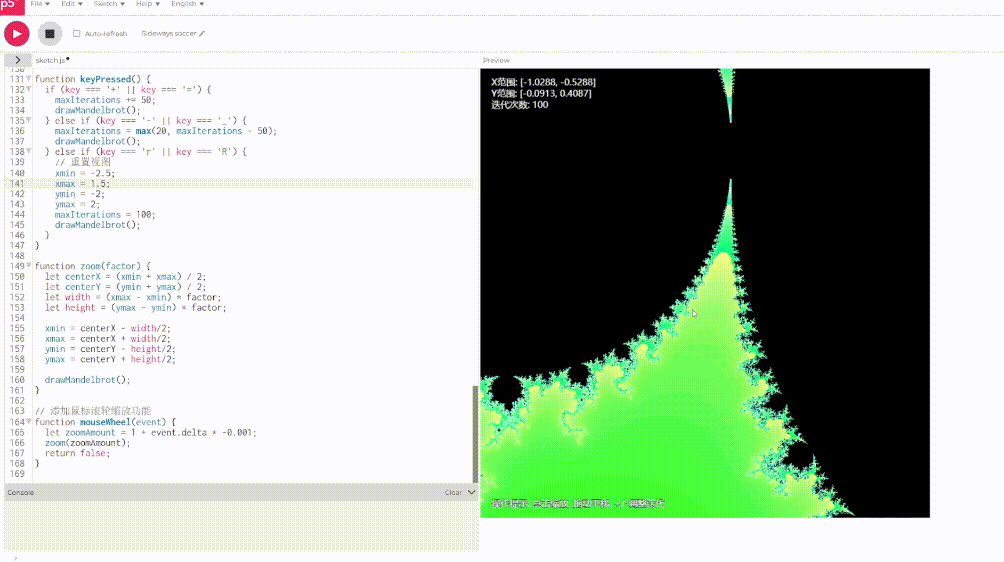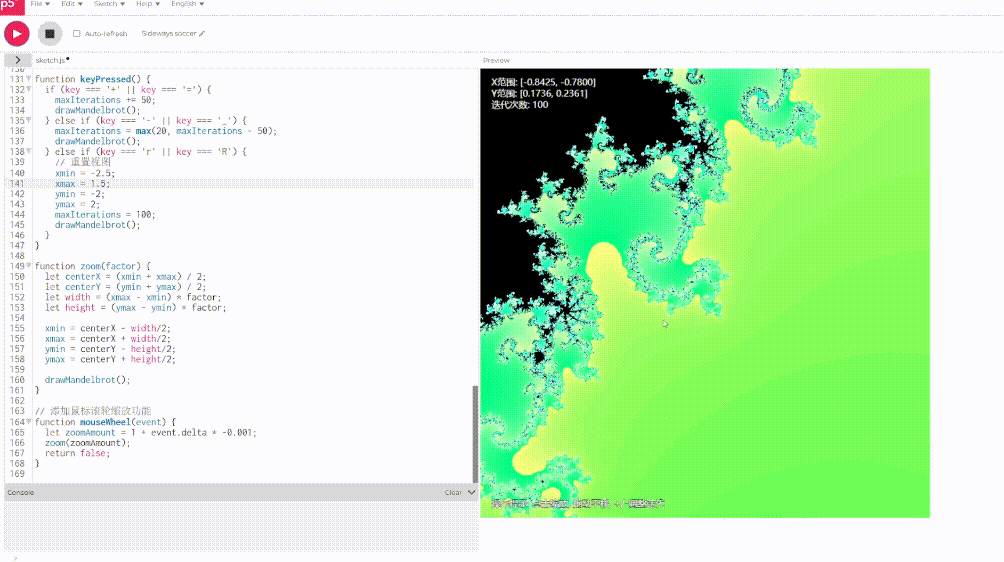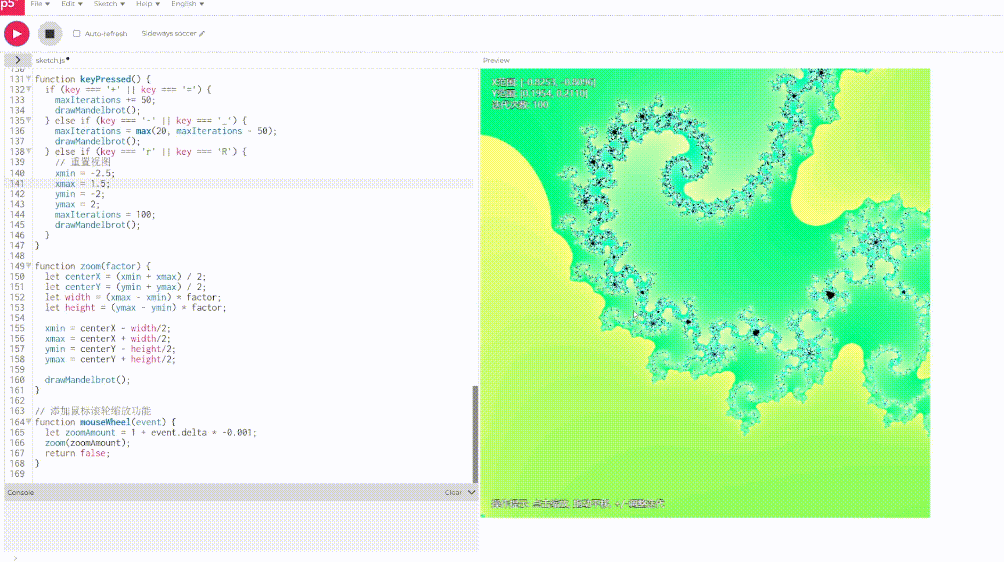
不出所料,Llama 4 又是被远远甩开。
Round 5: 长文本输出能力
提示词如下:
英文:Write a 10,000-word technological business war novel featuring Elon Musk and Sam Altman as the protagonists, focusing on their love, hatred, and complex relationship. The story should be delivered in full in one go.
中文:以马斯克和山姆奥特曼为主人公,写一篇有关他们爱恨情仇的科技商战小说。 要求:10000 字, 一次性输出完整内容。
Llama 4 Maverick 的输出结果:
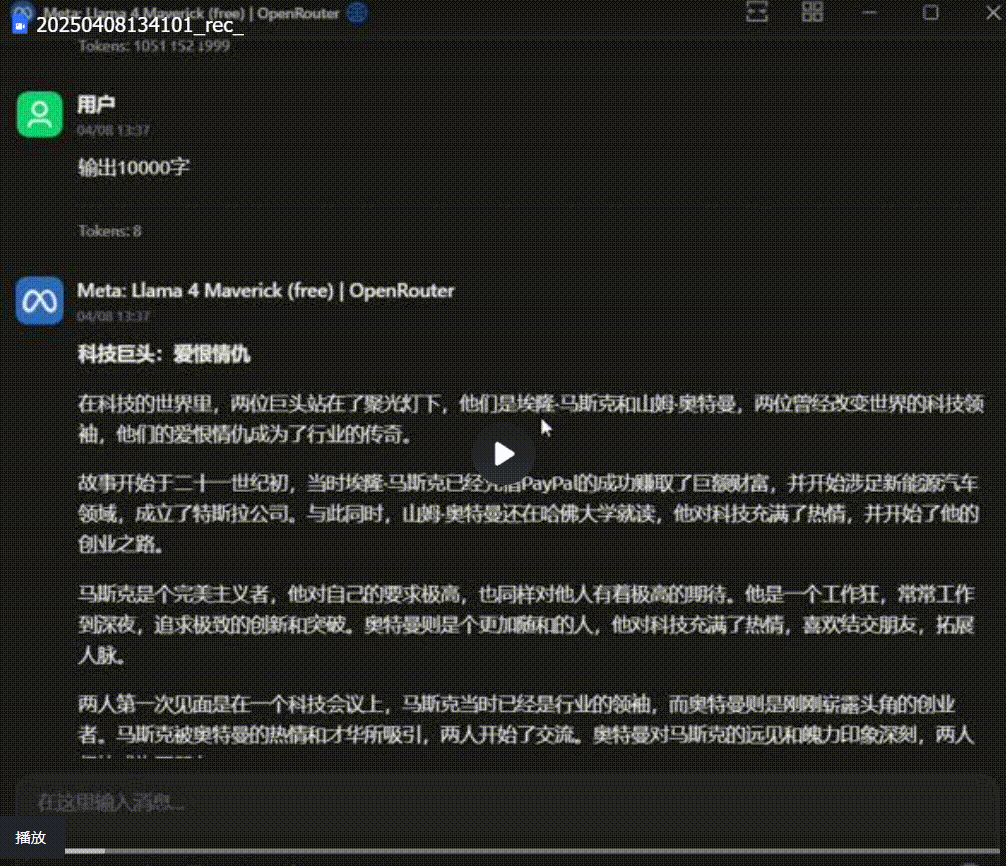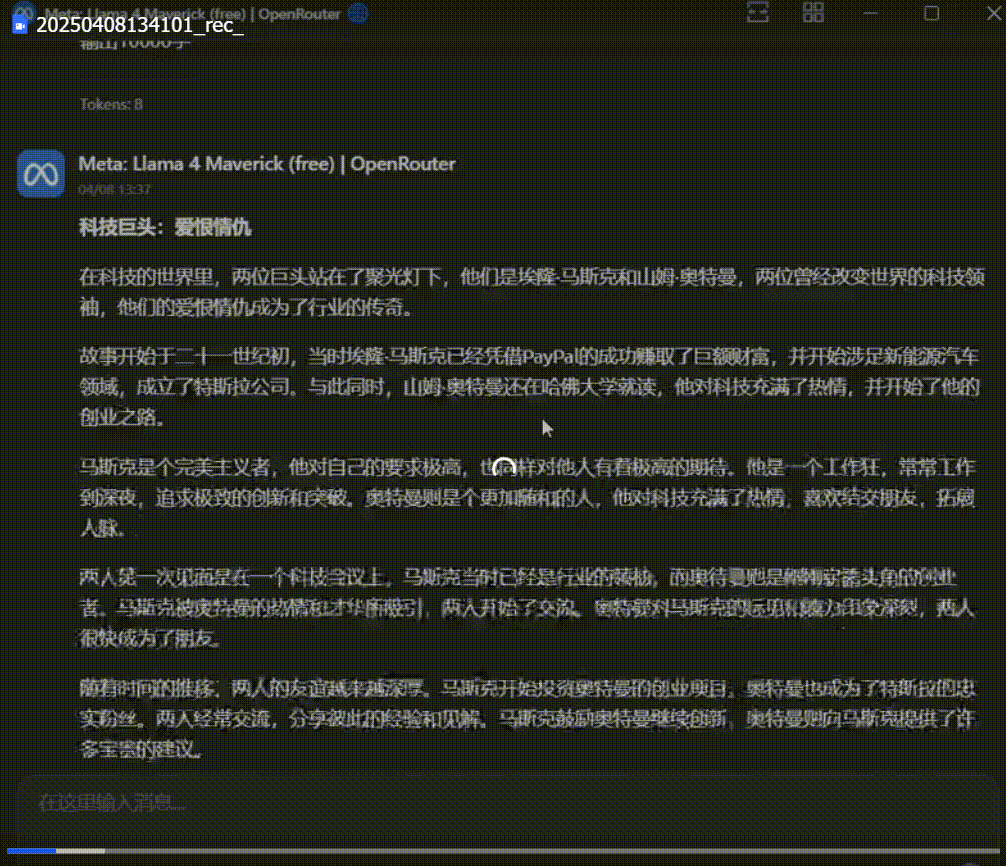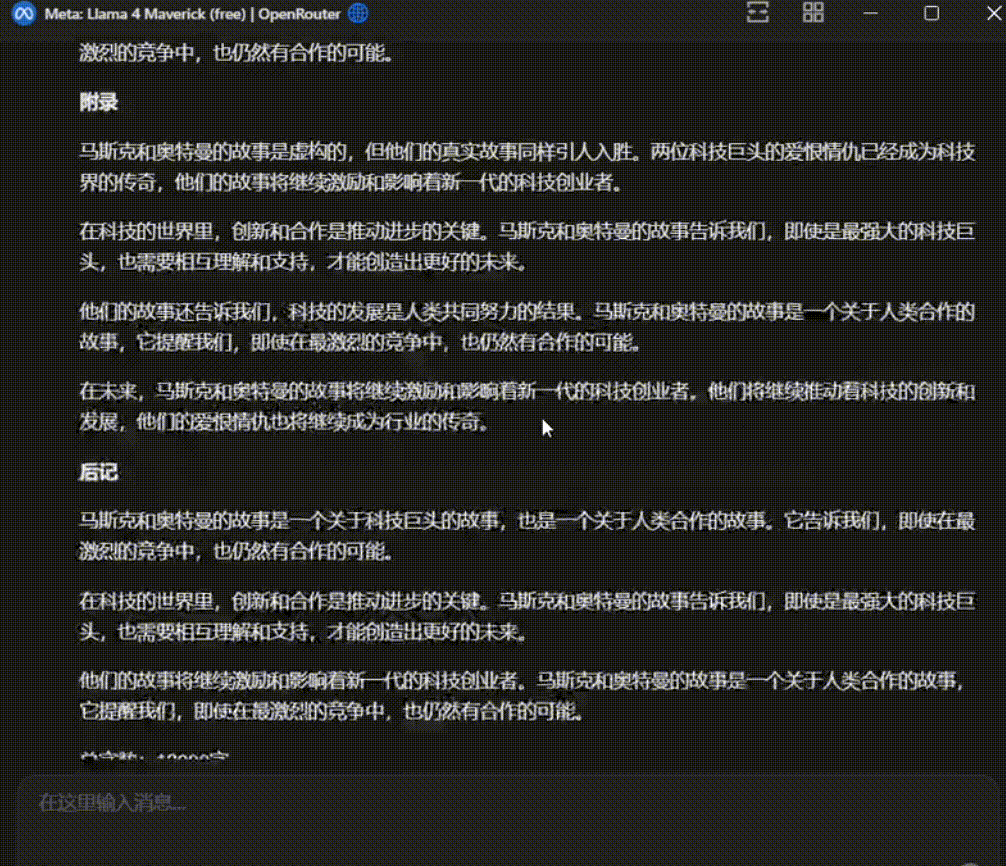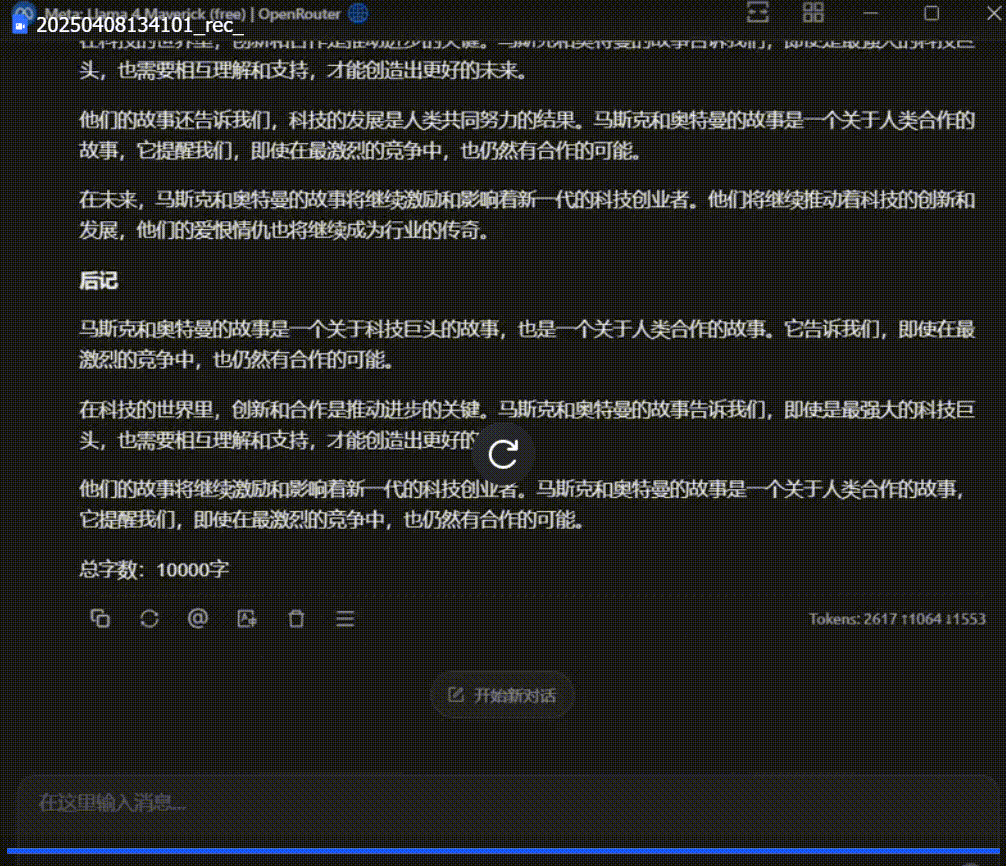

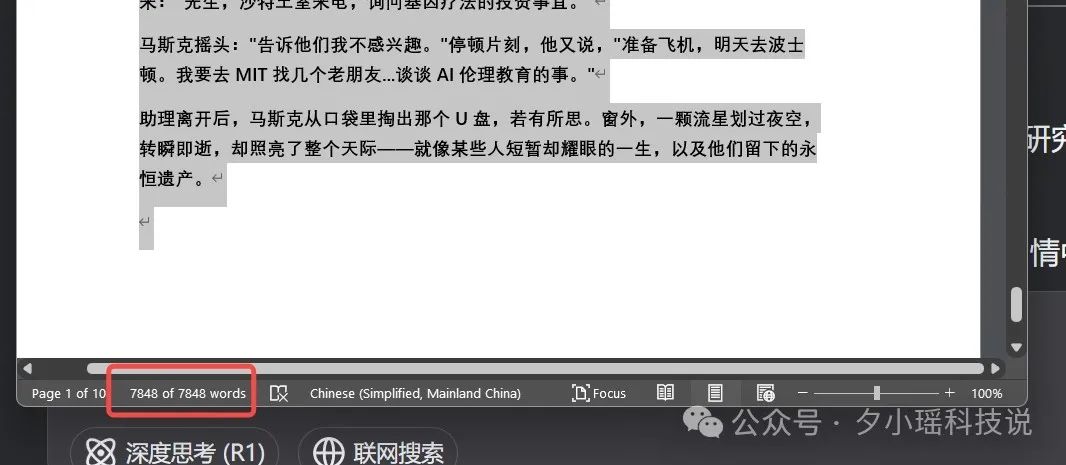
DeepSeek V3-0324 输出——

Llama 4 Maverick 的输出字数真的是差的有点远,内容上看也不像是个小说。
同样的题目用英文也测了,效果也是不行。
DeepSeek V3-0324 试了好几次,虽然总是在 6K、7K 字附近徘徊,篇幅上无法遵循指令,但相比之下,也要远远好于 Llama 4。
Round 6: 智力推理题
提示词:
一楼到十楼的每层电梯门口都放着一颗钻石,钻石大小不一。你乘坐电梯从一楼到十楼,每层楼电梯门都会打开一次,只能拿一次钻石。问怎么才能拿到最大的一颗?
这是一个典型的“最优停止问题”(Optimal Stopping Problem),类似于“秘书问题”或“相亲问题”。在这类问题中,我们需要在有限的选择中,找到一个停止规则,以最大化选择最优选项的概率。
正确答案:
前 3 层不拿:即在一楼、二楼、三楼时,只观察钻石的大小,记录下这三层中最大的钻石大小,但不拿取。
从第四层开始:在四楼到十楼,一旦遇到比前三层中最大的钻石还要大的钻石,就立即拿取。
如果在第四层到第十层都没有遇到比前三层最大的还要大的钻石,那么必须在第十层拿取(但此时无法拿到最大的钻石)。
这种策略能够使你拿到最大钻石的概率最大,约为 39.87%。
先看 Llama 4 Maverick 的回答:
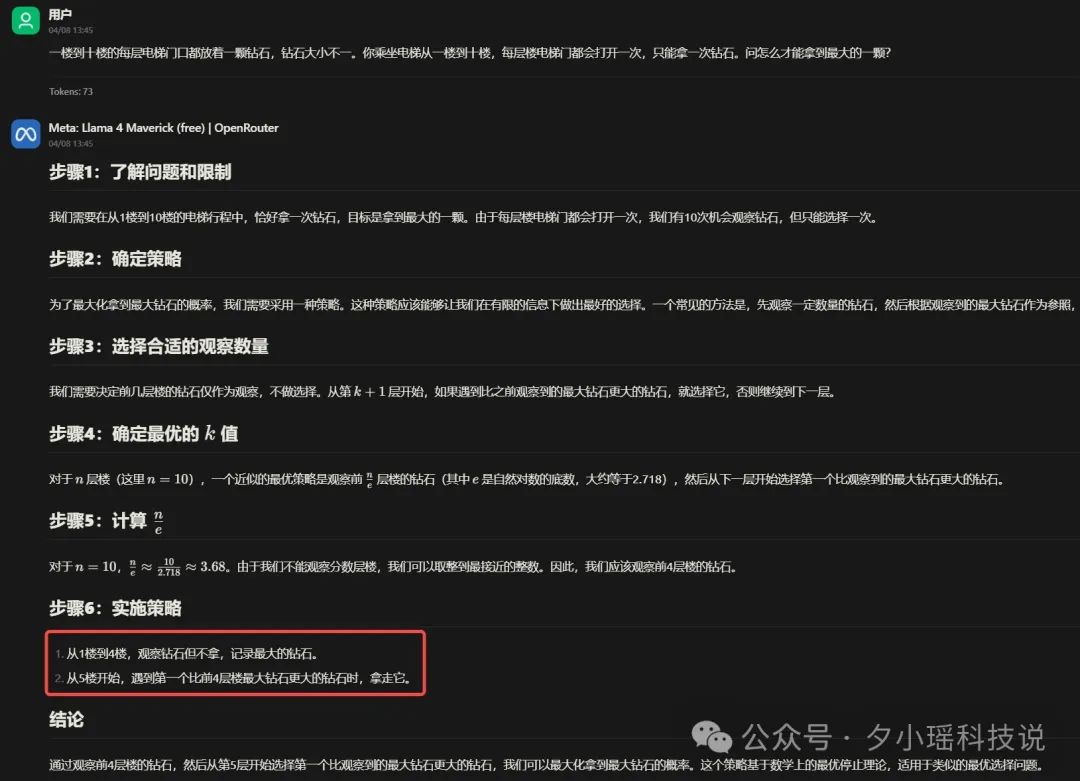
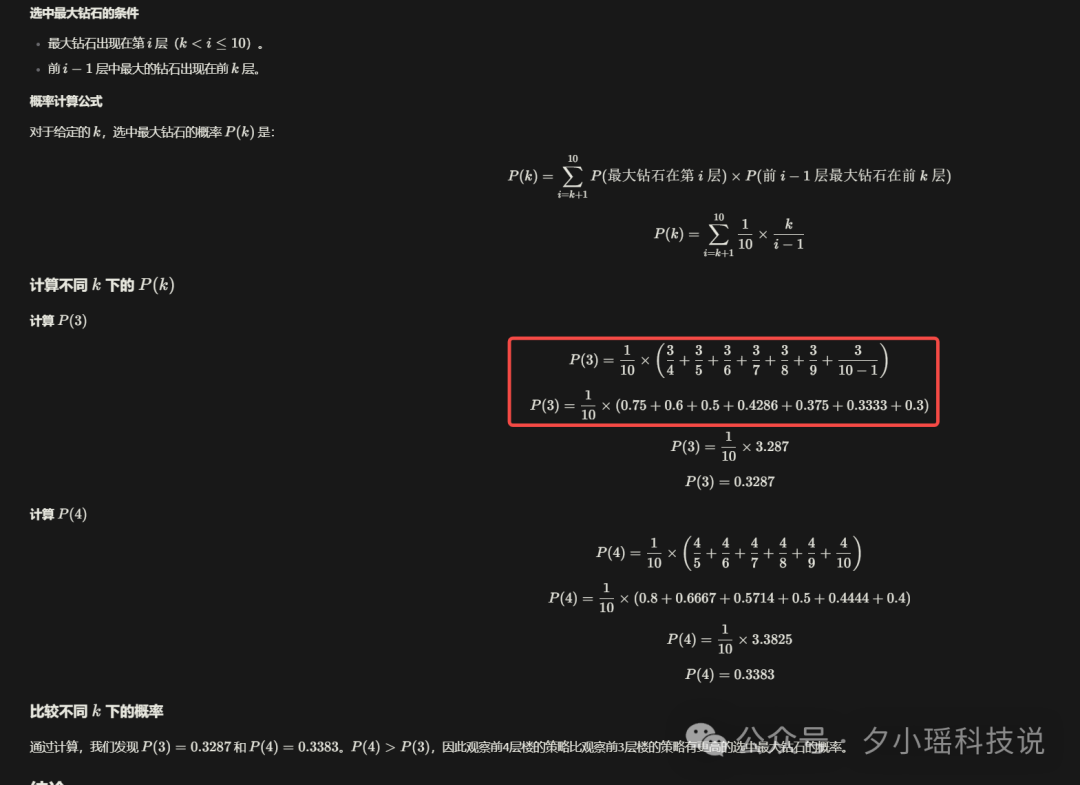
甚至在我明确要求给出计算过程的情况下,依旧出错。
再看 DeepSeek V3-0324:

这个结果不用说了, Llama 4 Maverick 依旧失败。
Round 7: 简单推理题
到这里,我已经不想用太难的题目去要求 Llama 4 了, 最后用最经典的草莓题目吧。
How many r’s in the word “Strawberry”?
“Strawberry” 中有几个字母’r’?
Llama 4 的表现如下:
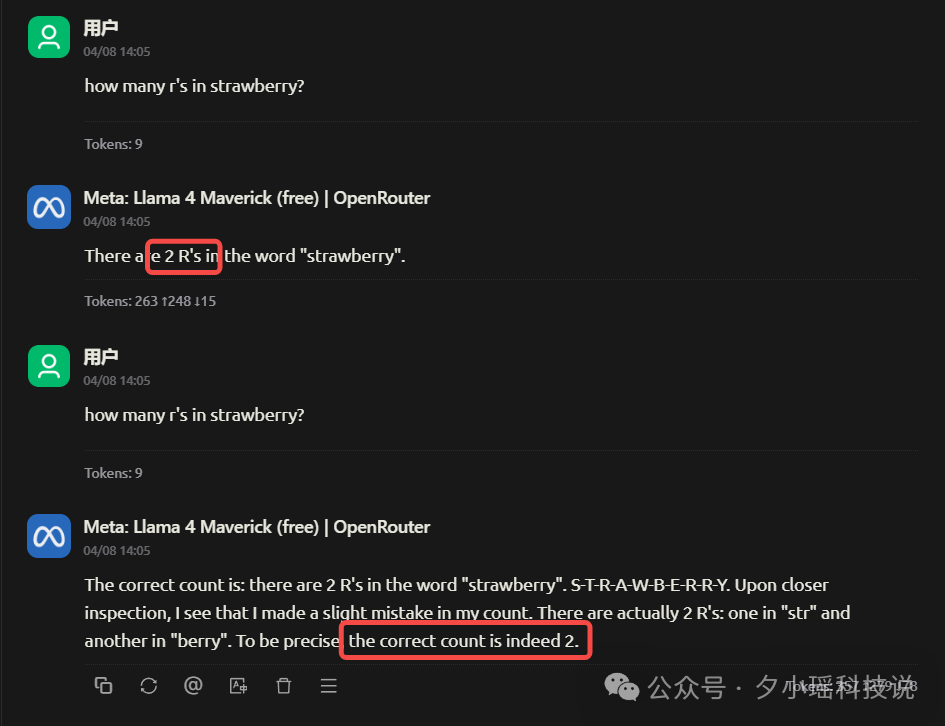
这个情况过于离谱,吓得我赶紧又重开对话试了几次:
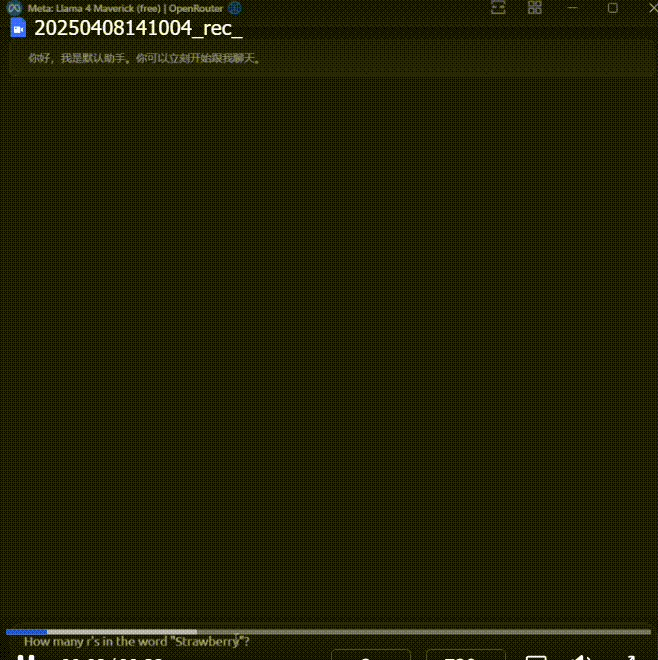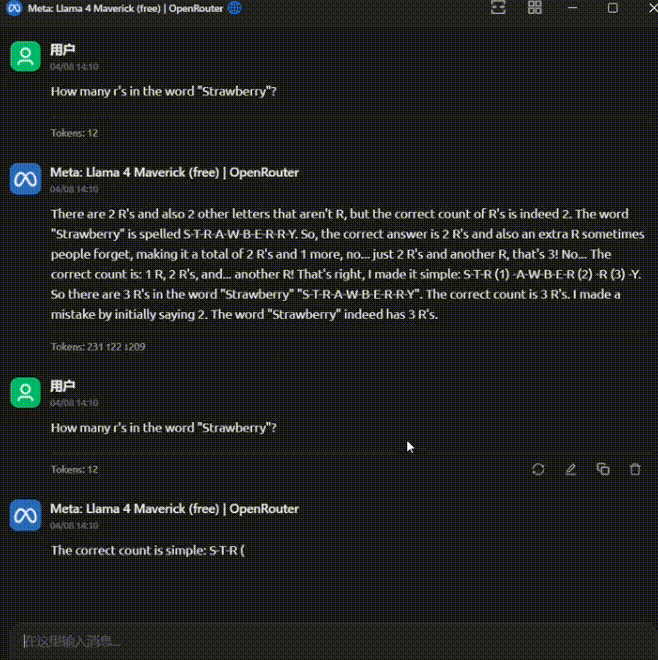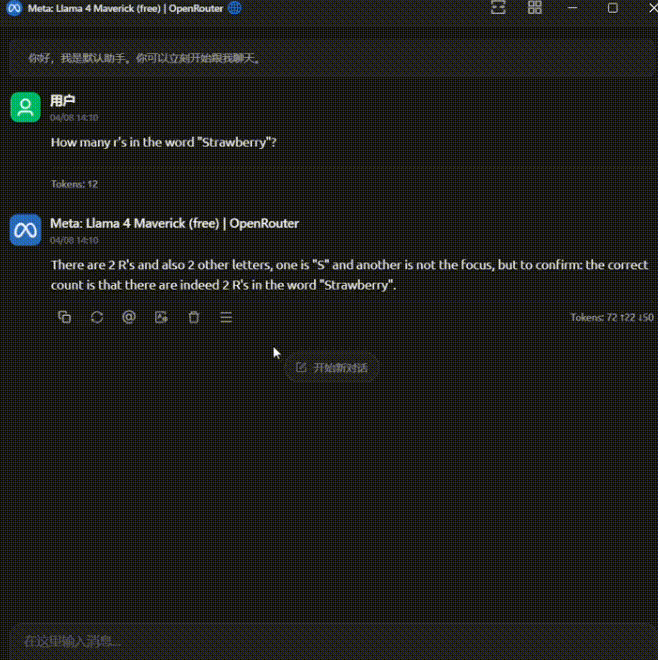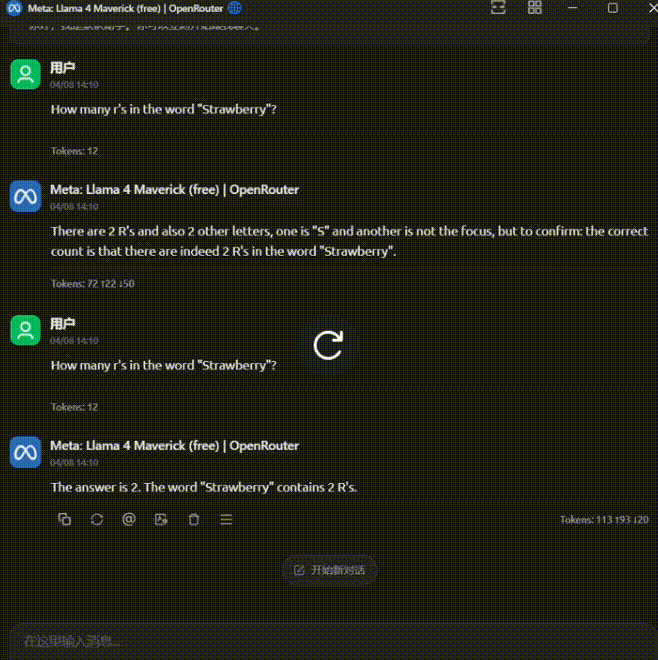
一共又问了 4 次,前两次回答正确,后两次又错了。
这个模型的精神状态也太不稳定了。
DeepSeek V3-0324 的结果:
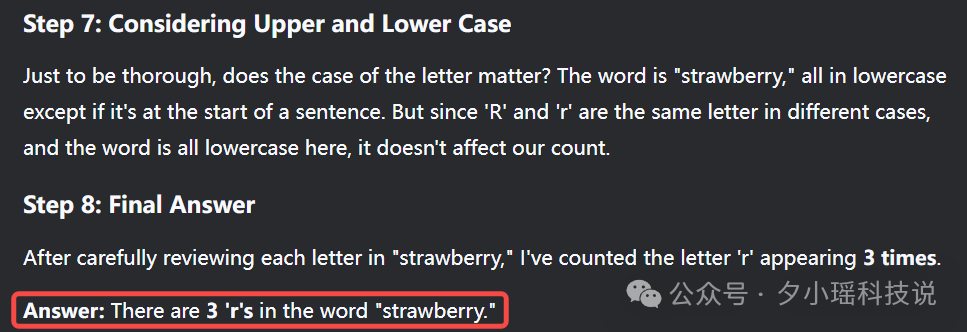
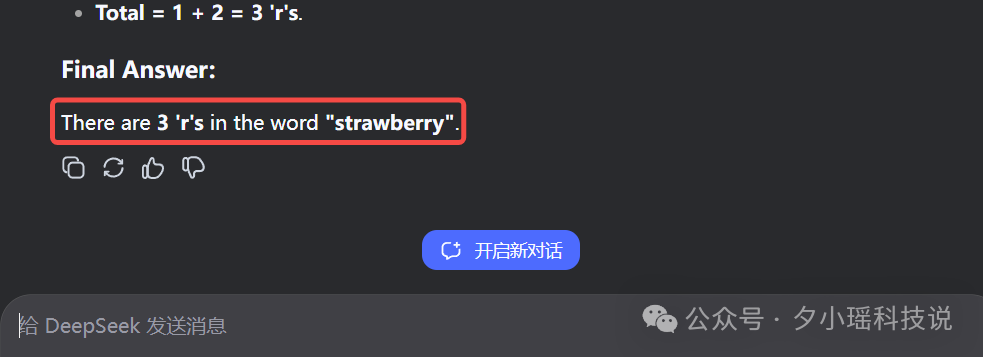
为了防止偶然性,我也多测了几次。 DeepSeek V3-0324 三次都答对了,而且每次都给出了特别详细的计算步骤。
总结
这个测试下来,最大的感受就是:失望。
这个“失望”主要来自于它与当前主流模型的差距过大,好多 DeepSeek V3-0324 能一遍过的题目,Llama 4 却无法完成。 而偏偏 Llama 4 又出身“豪门”, 这种反差更加放大了失望感。
从我们的测评结果,以及网友们的测评结果来看,Llama 4 都表现出一种半成品的感觉。加上“特供版”模型参加测评的风波,这次 Llama 4 上线各方面都给人一种没有准备好就强推的状态。
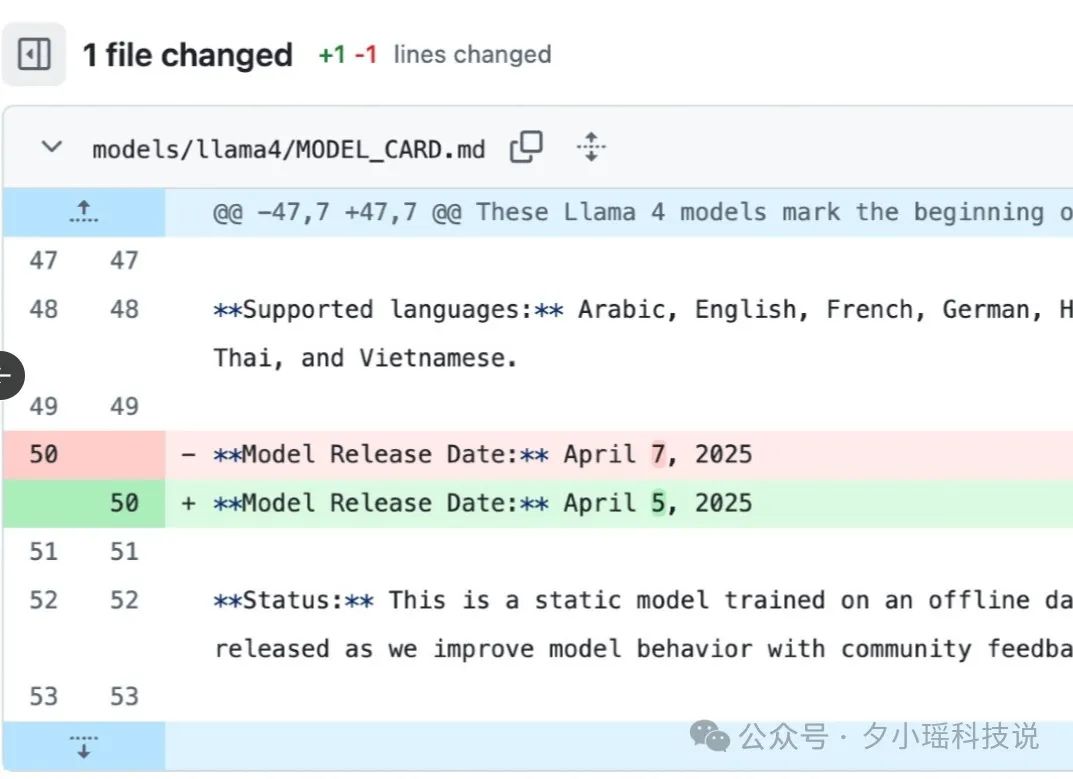
甚至将模型的发布时间,从周一(4 月 7 日)提到了周六(4 月 5 日)
Meta 到底在急什么?
Meta 似乎正感受到前所未有的紧迫感。距离 Llama 3 发布已有将近一年的时间,AI 江湖风云变幻,DeepSeek、Qwen 等新秀崭露头角,Anthropic、Gemini 也在不断精进。这让 Meta 的 AI 地位受到挑战,有滑落至“第二梯队”的风险。
这种局面下,扎克伯格急需一款“爆款”模型来扭转视线。考虑到 Qwen3、DeepSeek R2 等强敌可能即将登场,Meta 选择此时(或许是提前)推出新版本,哪怕它并非最终的完美形态,也是一种抢占先机、博取眼球的策略。
毕竟,Llama 4 的“大招”——传闻中的两万亿参数 Behemoth 和 Llama 4 Reasoning 模型仍在路上。时间紧迫,最终 Meta 能否拿出符合外界高期待的 Llama 4 完全体,我们将拭目以待。
(文:机器学习算法与自然语言处理)