
机器之心编辑部
拥有行业最强多模态推理与交互能力的商汤「日日新 SenseNova V6」来了。
如果让大模型像人一样聪明,应该是什么样的?
你可能会回答,我们生活的世界纷繁复杂,常常涉及多模态信息(如声音、文字、视觉、时间、空间等等),对大模型提出了极为复杂和严苛的挑战。
这要求大模型必须拥有极强的推理和交互能力。
GPT-4o 的出现让我们看到了人机交互新方式。就像这样,它可以为你讲解数学题。
可以说,一直以来,GPT-4o 是可交互模型的行业标杆。
现在,来自国内的一款大模型,表现甚至更胜一筹。
下面是来自国产大模型的解题过程,它能循序渐进的教你如何解题,看起来比 GPT-4o 更像一位有耐心的老师:
又比如,我们指尖指向哪个单词,它就进行精准翻译,并自动生成单词卡,整个过程自然丝滑。
这正是商汤全新升级的融合多模态模型「日日新 SenseNova V6」(以下简称:日日新 V6)在 APP 端的体验效果。
模型通过多模态长思维链训练、全局记忆、强化学习等方面的技术突破,拥有行业最强的多模态推理与交互能力。

相比此前 V5.5 版本,日日新 V6 / V6 Reasoner 推理能力显著增强。其中在多模态推理任务上,SenseNova V6 Reasoner 同时超过了 OpenAI 的 o1 和 Gemini 2.0 flash-thinking 。在语言深度推理任务上,SenseNova V6 Reasoner 也同样超过了 OpenAI 的 o1 和 Gemini 2.0 flash-thinking。
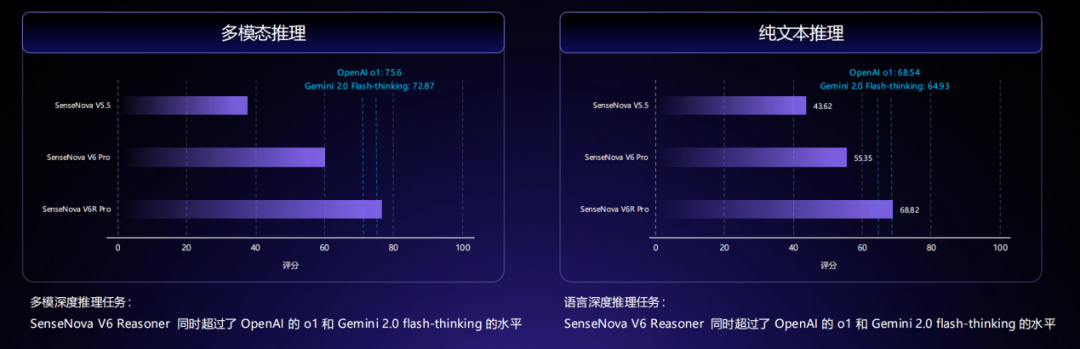
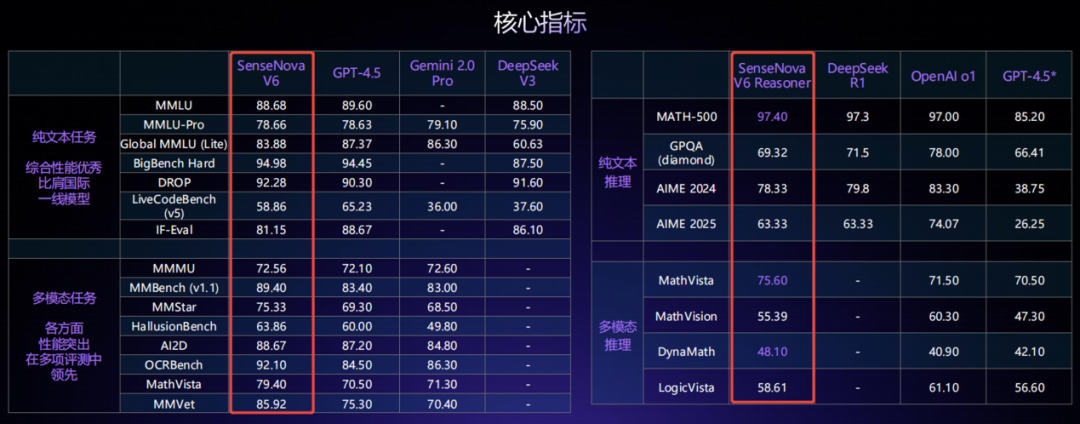
日日新 V6 在权威的推理能力及多模态能力评测中,也处于行业领先水平。在纯文本和多模态任务上,多项指标超越 GPT-4.5、Gemini 2.0 Pro,并且在纯文本任务上全面超越 DeepSeek V3。纯文本推理与多模态推理能力均对标 GPT-4.5 和 Gemini 2.0 Pro 等国际一流模型的水平。
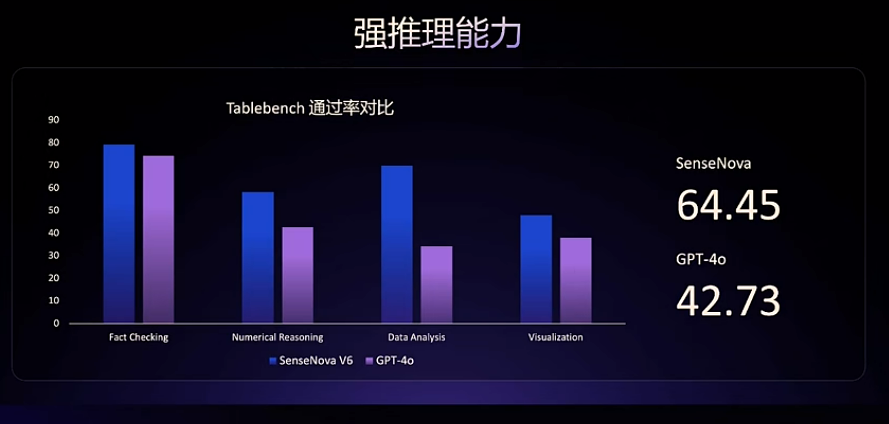
在强推理能力上,日日新 V6 大幅领先 GPT-4o。
此外,日日新 V6 在音频理解、视觉理解等基准上也处于领先水平。
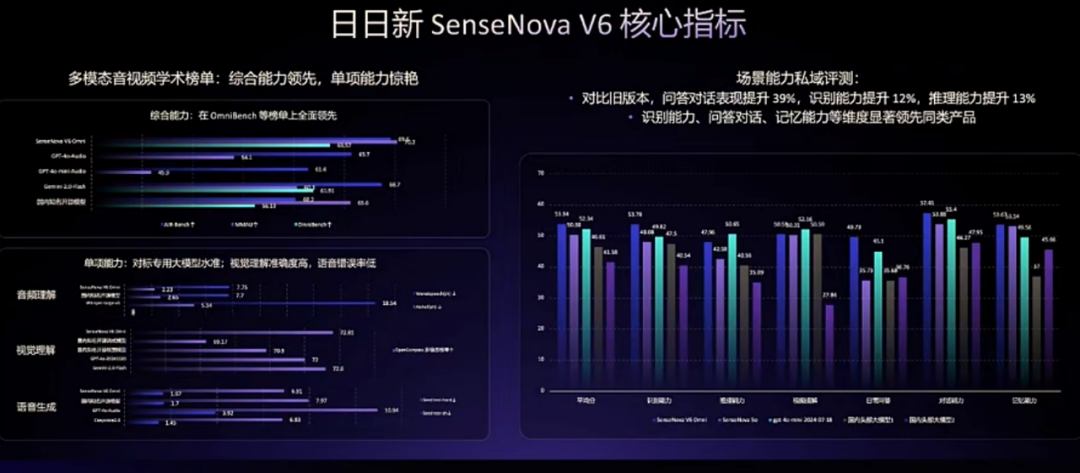
目前,日日新 V6 已经正式开放 API,并可通过商量 Web、商量 App(内测版),以及商汤小浣熊、咔皮记账等应用进行体验。
一手实测:主打多模态与深度思考的融合
既然日日新 V6 各项指标已经做到了全面领先水平,那真实体验效果如何呢?
接下来,我们第一时间上手实测一下日日新 V6 大模型,看看它在实际应用场景中的表现究竟如何。
首先考考它的推理能力。
我们出了一道纯文本的逻辑推理题,商量花了 42 秒进行了深度思考,先根据题目条件来逐步推理,再倒推验证,最终给出正确答案,整个思路非常清晰。

商量还支持多模态深度思考,换句话说,我们不仅可以输入文字,还可以上传最多 4 张图片。
比如,我们上传了一张莫妮卡・贝鲁奇的经典剧照,看它能否准确说出其出处。


商量综合分析了红发黑裙的人物造型,石板街道、户外咖啡馆等场景细节,以及主题氛围和视觉风格,最后认出这是《西西里的美丽传说》。同时,它还一并回答了该电影的导演以及主要的影片内容。
接着,我们又测了下它的交互能力,涉及数学讲题、翻译点读、文旅讲解和绘本故事四大应用场景。
对于年轻父母来说,辅导孩子学习可是一件苦差事,甚至「不写作业,母慈子孝;一写作业,鸡飞狗跳」一度成为网络热梗,而商量的「数学讲题」场景,简直帮了父母们的大忙。
它包括判题和讲题两大功能。只要拿着孩子写的试卷,咔嚓拍个照,它就能精准识别手写答案,而且它的深度思考模式可显著提高解题准确性,正确率可达到 95%。
同时,基于强大的音视频沟通能力,商量还搞了个「免费数学私教」,不仅能快速锁定孩子在解题中的错误、以引导提问的方式逐步剖析解题思路,还可以实时一对一语音答疑。
视频开启 2 倍速
给孩子讲绘本故事也让不少家长头疼,虽然绘本图文并茂,但照本宣科讲出来就显得干干巴巴。商量则通过多模态识别与语音表达技术,将绘本内容进行情感化演绎,融入语音互动或后续故事问答等内容。
如果出门旅游,商量还是个合格的导游。拍摄一段文物或景点画面,它就能声情并茂地讲解相关历史背景。
从基准测试到实际体验来看,毫不夸张的说,日日新 V6 确实是一位名副其实的全能优等生。大家可能会疑问了,打造这样一款大模型体系,成本一定很高吧。
事实上成本与效率这块商汤也拿捏了。
技术解读:原生融合多模态,还有独门技术
在日日新 V6 大模型上,商汤通过一系列创新性的技术突破和商业策略,成功实现了高性能与低成本的完美平衡。
从硬件基础说起,利用商汤大装置,商汤构建了「模型 – 系统 – 计算」的垂直整合体系,实现了大模型算法与基础设施的联合优化,大幅提升了日日新 V6 的训练和推理效率。
依靠 6D 自动并行、FP8 低精度训练等技术,日日新 V6 的训练成本达到了行业最优水平。在推理时,日日新 V6 实现了生产级的 INT4 量化、高适应性的分级缓存、分钟级弹性扩缩容,整体推理成本也做到了行业最低,效率超过了 DeepSeek。
在此之上的大模型算法,也是商汤在 AI 领域深耕多年的结果。
如今,多模态大模型已成为人们追求的方向。然而,我们在很多应用中接触到的多模态模型并不能说是「完全体」。正如我们在很多应用中所接触到的,不少大模型是把图像、语音、文本分别训练好,再用「胶水代码」粘在一起。就像用翻译软件先把图片转文字,再把文字转成语音 —— 看似多模态,实际上是多个单模态在接力干活。
真正的多模态应该像人类感官与大脑,比如当人类看到苹果时,视觉(颜色)、触觉(手感)、味觉(甜味)是同时感知的。
商汤从一开始就全面瞄准多模态。他们从模型底层架构和数据训练阶段就实现不同模态(如文本、图像、音频、视频等)的统一理解和生成,而非后期拼接多个单模态模型。
去年 7 月,商汤推出的日日新 SenseNova 5.5 大模型体系引发了业内关注。它是国内首个流式原生多模态交互模型,拥有 6000 亿参数,基于超过 10TB tokens 的高质量训练数据实现了 109.5 字 / 秒的推理速度。
今年 1 月,商汤在原生融合多模态训练上实现突破,发布了「日日新」融合大模型。并在 SuperCLUE 2024 年语言模型综合榜单、OpenCompass 多模态综合榜单上取得了国内模型榜首的成绩,验证和商汤融合训练技术的巨大潜力。
沿着这一路径,商汤进行了进一步优化和规模扩展,并在日日新 V6 上实现了多模态综合性能的显著提升。
日日新 V6 进一步强化了推理能力,它可以支撑起对人类意图的深化理解,对复杂信息进行分析判断,并解决真实环境中的难题。与此同时,它还可以充分理解感情,与人进行流畅的交互。它拥有足够长的记忆,能够记住过去一段时间内发生的事,并将记忆内信息融入推理。
模态越多,大模型处理的实际上下文就越长。在思维链上,商汤通过多智能体协作进行长思维链合成和验证,实现了多模态长思维链合成技术,可以支持合成最长 64K token 的多模态长思维链,这相当于让模型在给出答案之前可以连续进行长达 6 万字的思考,让模型具备了面对复杂问题的长时间思考能力。
日日新 V6 的思维链引擎中,商汤调用了一系列以往在计算机视觉方面的能力,包括视频、图像、3D 等以给出主思维链的反馈,其输出的多模态思维链会被智能体改写为符合模型的训练格式。日日新 V6 在思考时还可以调用沙盒甚至外部代码能力来呈现出更好的思维链。
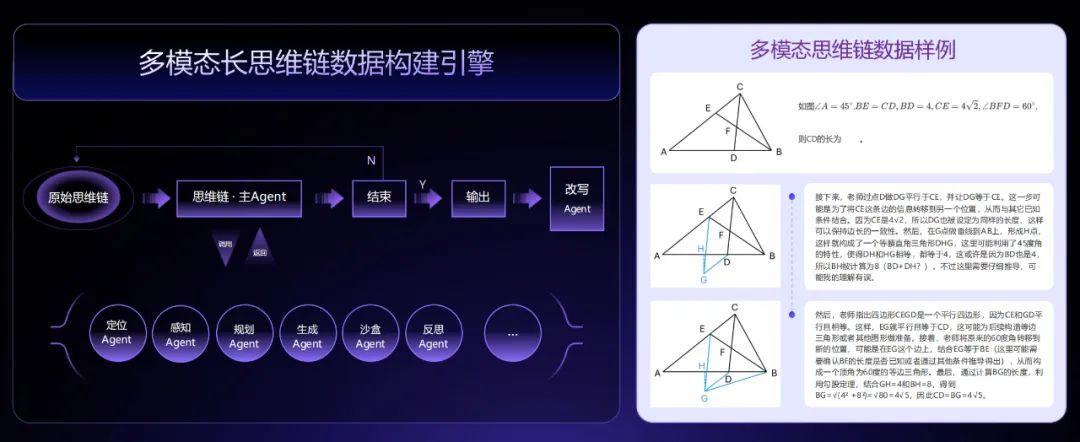
这就让日日新 V6 在做立体几何问题时,甚至可以做辅助线。
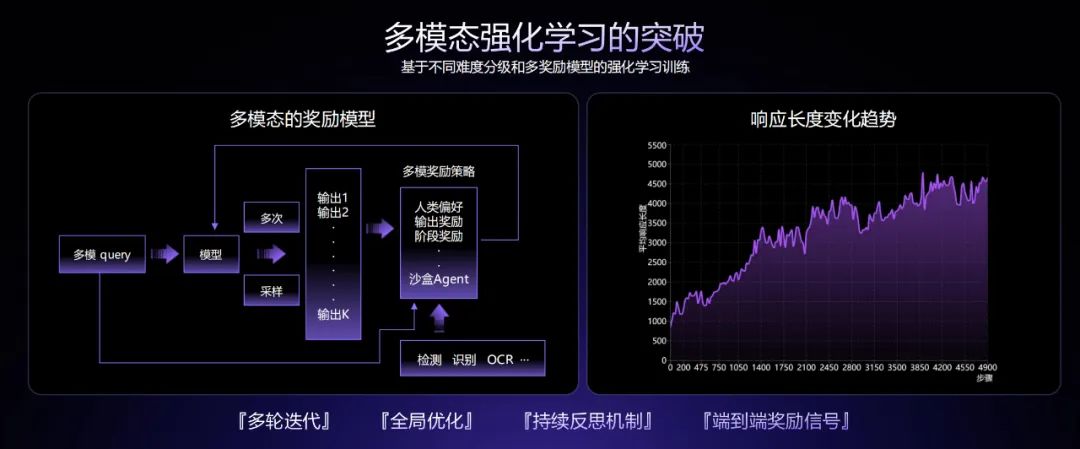
前不久,DeepSeek R1 通过强化学习算法 GRPO 取得了突破,商汤在 SenseNova V6 上为大模型带来了多模态混合强化学习,面向多种图文任务构建起混合增强学习框架,可以同步进行基于人类偏好的 RLHF 和基于确定性答案的 RFT,并且通过动态调节机制保证主客观表现的均衡,能在提升推理能力的同时不损害模型的情感表达。
在这个过程中,原始的多模态模型可以被调用到奖励模型中,获得先验知识的反馈,随着持续反思,模型的响应长度变得更长,这也意味着推理变得更仔细。
最后,日日新 V6 还具备独一无二的长视频统一表征和动态压缩能力,它可以将视觉、听觉、文本、时间轴逻辑进行对齐,形成多模态统一的时序表征,通过细粒度级联信息压缩和内容敏感的动态过滤,实现长视频的 400 倍高比例压缩。据介绍,商汤的大模型可以把 10 分钟视频压缩到仅有 16K tokens,仍能保留关键语义。
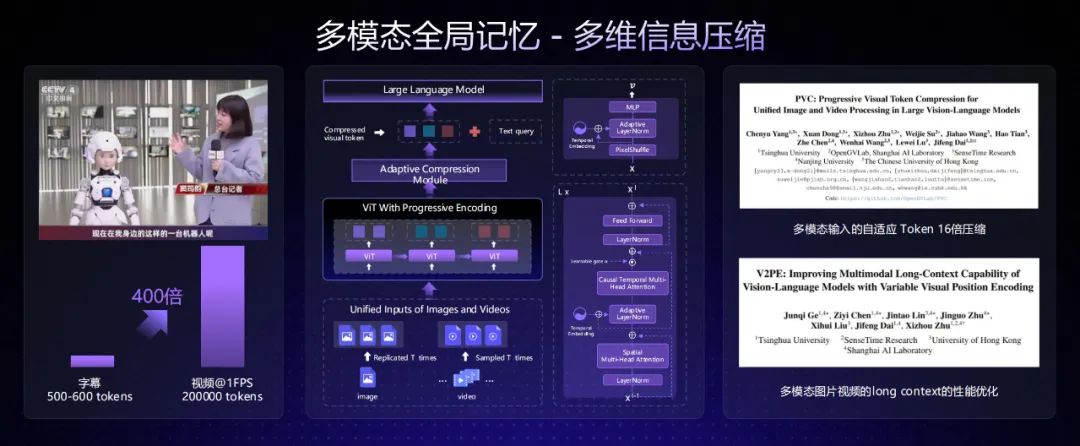
对于真实世界中的应用,这一系列技术至关重要。
发布会现场,我们看到商汤与傅利叶机器人合作,基于 SenseNova V6,傅利叶机器人可以通过融合图像、视频、语音和文本信息理解环境进行思考与表达,洞察用户的需求与情绪,与人类进行顺畅交互,机器人在说话的同时,还能同步生成与语义相匹配的动作,实现语言与行为的统一。
此外还有更多搭载 SenseNova V6 的 AI 产品和应用,涵盖办公、儿童教育、金融、翻译、电商购物、情感陪伴、支付等等,让我们感受到,AI 已经落实于百姓的日常生活场景。
生成式 AI,正在进入新时代
时间进入 2025 年,大模型技术的发展正在进入新的阶段,一些重要技术已经走入瓶颈期,新的方向正在出现。
图灵奖得主、Meta 首席 AI 科学家 Yann LeCun 在谈及 AI 为何难以做出科学发现时曾表示,纯粹的语言模型不能完整地表达智能,无法创造新的事物。
基于文本的生成式 AI 也在接近「上限」,大语言模型的发展正在快速耗尽互联网的文本数据。OpenAI 联合创始人 Ilya Sutskever 认为,耗尽的时间会在 2028 年前后。
另一方面,在数字世界、物理世界中还有很多、甚至更大数量级的更多模态的内容还没有挖掘。
从 DeepSeek 横空出世,到英伟达 H300 超算的发布,我们可以观察到,AI 领域正在出现几个新的趋势:
-
首先是对于 Scaling Laws 的新思考,随着大模型参数和训练数据量级增加效益的递减,业界正在逐渐把关注点转向效率提升;
-
其次是多模态能力,从 GPT-4o 和最近发布的 Llama 4 上可以看出,具备原生的多模态能力,能够实现更深度、更广泛的信息交互与整合,将会成为未来大模型的竞争重点;
-
在它们的基础上,大模型的强推理则会成为人们打造复杂任务智能体,实现高价值场景应用的关键。
有趣的是这三个方面,也正是商汤的优势项:凭借大量融入真实业务的应用,商汤构建出的大模型体系拥有处理复杂信息和解决复杂问题的能力;多年在计算机视觉等方向上的积累,让商汤在大模型迈向多模态时具备了绝对优势;在算力方面,商汤的大装置 SenseCore 一直在推动 AI 算力设施、应用与行业需求的深度融合,其能力还在不断增长。
在 AI 2.0 时代,基础设施、大模型和应用三者的关系已变得密不可分。越来越广泛的应用场景在推动着 AI 模型的发展,AI 技术也在不断创造并推动新的应用需求;与此同时,对大模型优化的 AI 基础设施正在出现,新的模型也在催生着更为强大的技术。
未来,商汤的日日新大模型,还会向生产力工具 + 交互工具两大方向进行大规模落地。其中生产力工具面向传统企业、金融、政务等领域,能帮助人们提升工作效率、优化工作流程;交互工具则面向所有普通用户,覆盖从智能助手、智能硬件到智能营销……
过不了多久,最常见的日常场景,也都能用上原生多模态 AI 的力量。
©
(文:机器之心)