


Github: https://github.com/MoonshotAI/Kimi-VL
Paper: https://github.com/MoonshotAI/Kimi-VL/blob/main/Kimi-VL.pdf
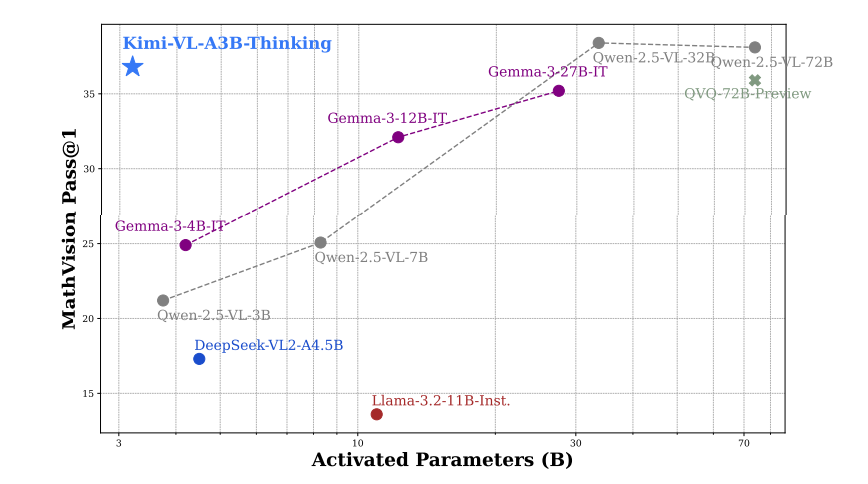
在榜单上,大多数超过Qwen2.5-7B模型,如下表所示。
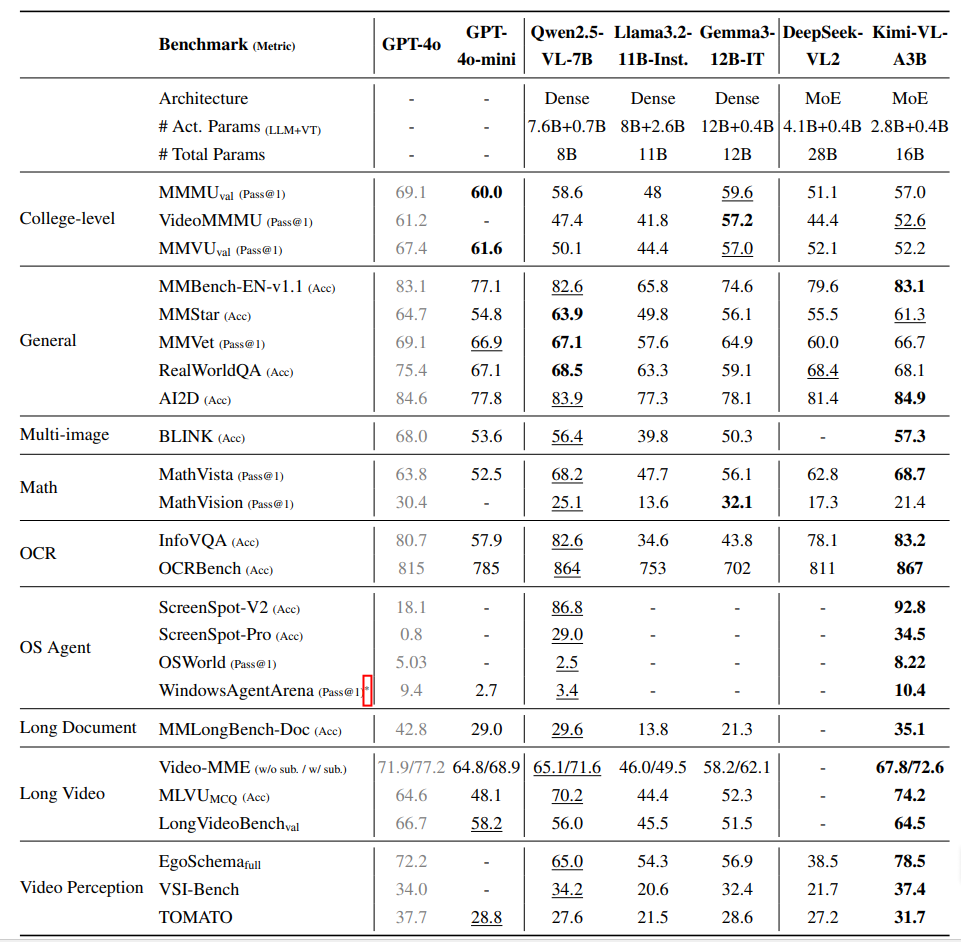
模型架构是由 MoE语言模型、原生分辨率视觉编码器(MoonViT)和 MLP 映射层 组成,如下图所示。

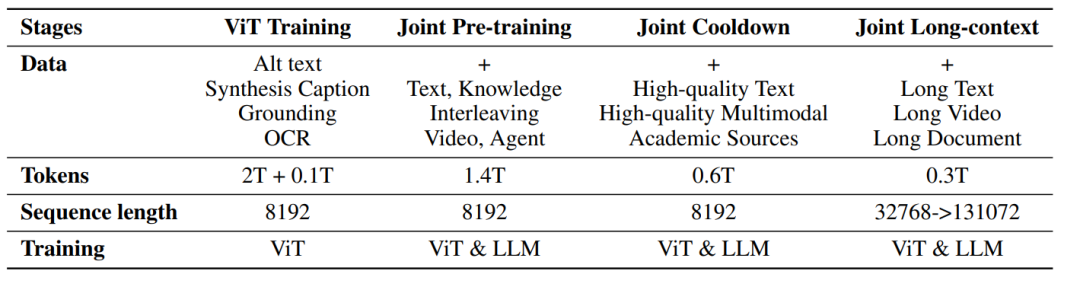
Pre-Train阶段涉及4个阶段,总计4.4T Tokens。
-
独立ViT训练:训练MoonViT,使其成为一个健壮的原生分辨率视觉编码器。 -
联合预训练:同时使用纯文本数据和多种多模态数据训练整体模型。 -
联合冷却阶段:使用高质量的语言和多模态数据集进行模型训练,并且加入合成数据,提升模型在数学推理、知识类任务和代码生成方面的表现。 -
联合长文本激活阶段:将模型的上下文长度从8192扩展到131072,以处理长文本和长视频。
Posting-Train阶段涉及3个阶段:
-
SFT阶段:利用多模态指令数据进行微调,先在32k序列长度下训练模型1个epoch,学习率从2e−5衰减到2e−6,然后在128k序列长度下再训练1个epoch。在第一阶段(32K),升温到1e−5最终衰减到1e−6。 -
CoT阶段:通过精心设计的提示工程构建了一个小而高质量的长CoT数据集,为了让模型学习基本的规划、评估、反思和探索的过程。 -
RL阶段:采用强化学习(RL)对模型进行训练,使其能够自主生成结构化的CoT推理路径。 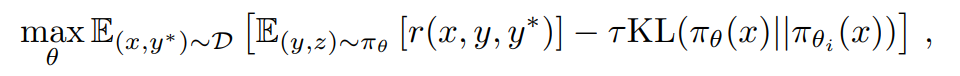
最后快速使用
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor
model_path = "moonshotai/Kimi-VL-A3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
image_path = "demo.png"
image = Image.open(image_path)
messages = [
{"role": "user", "content": [{"type": "image", "image": image_path}, {"type": "text", "text": "What is the dome building in the picture? Think step by step."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
inputs = processor(images=image, text=text, return_tensors="pt", padding=True, truncation=True).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=512)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
response = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(response)
(文:机器学习算法与自然语言处理)