
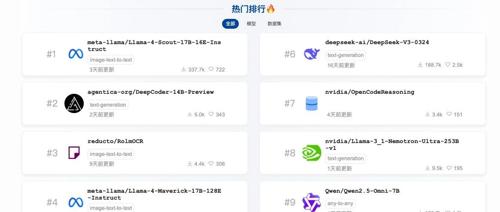
-
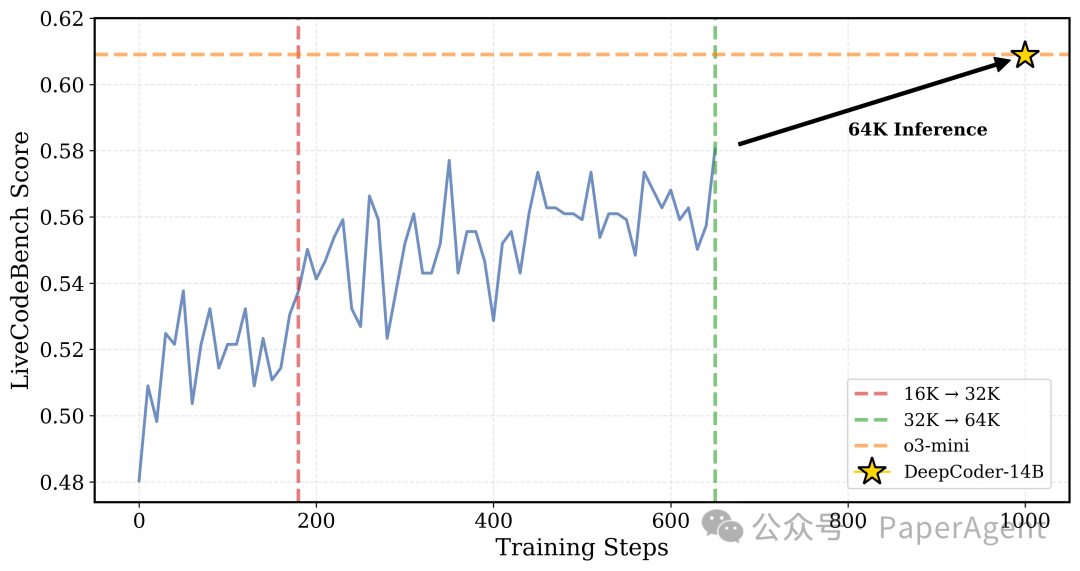
agentica-org/DeepCoder-14B-Preview -
nvidia/OpenCodeReasoning -
moonshotai/Kimi-VL-A3B-Thinking
-
Llama-3_1-Nemotron-Ultra-253B-v1
-
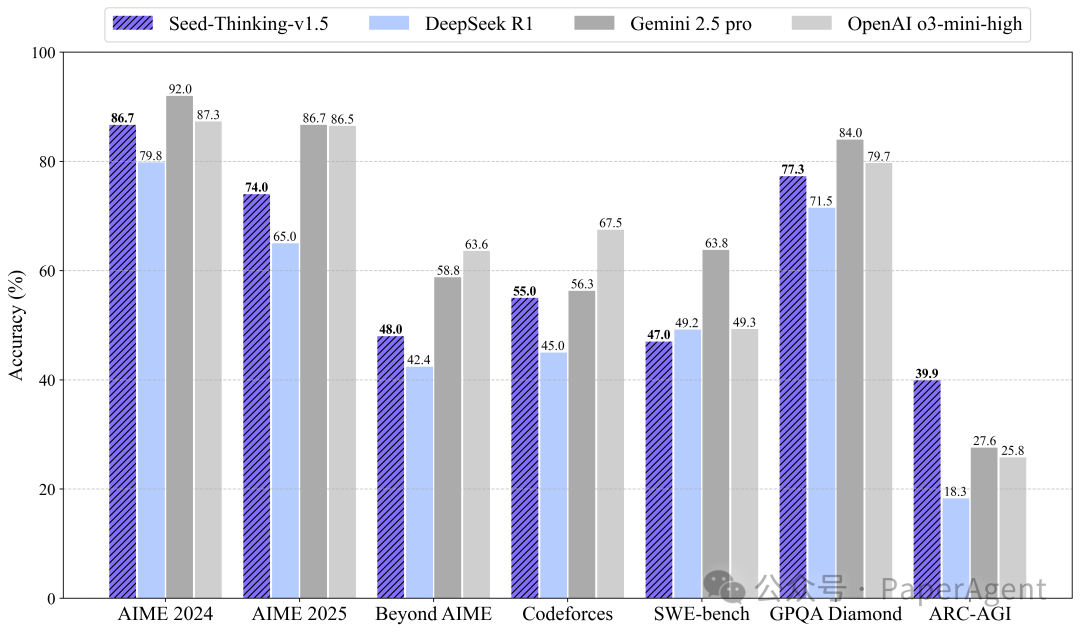
【未开源】字节豆包/Seed-Thinking-v1.5(说是200B击败了DeepSeek-R1)
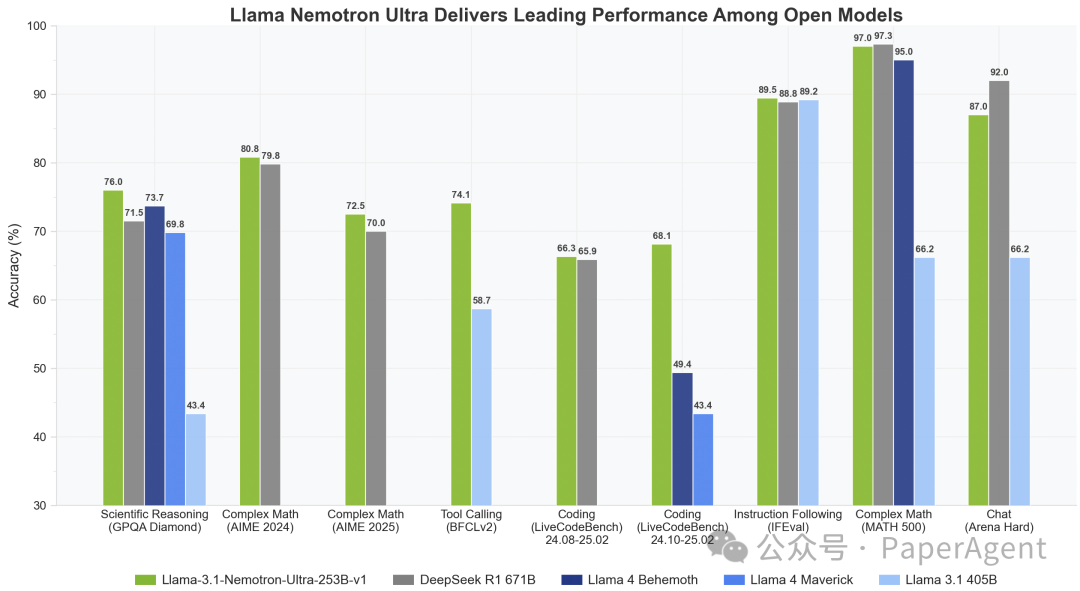
2、模型-英伟达/Llama-3.1-Nemotron-Ultra-253B-v1
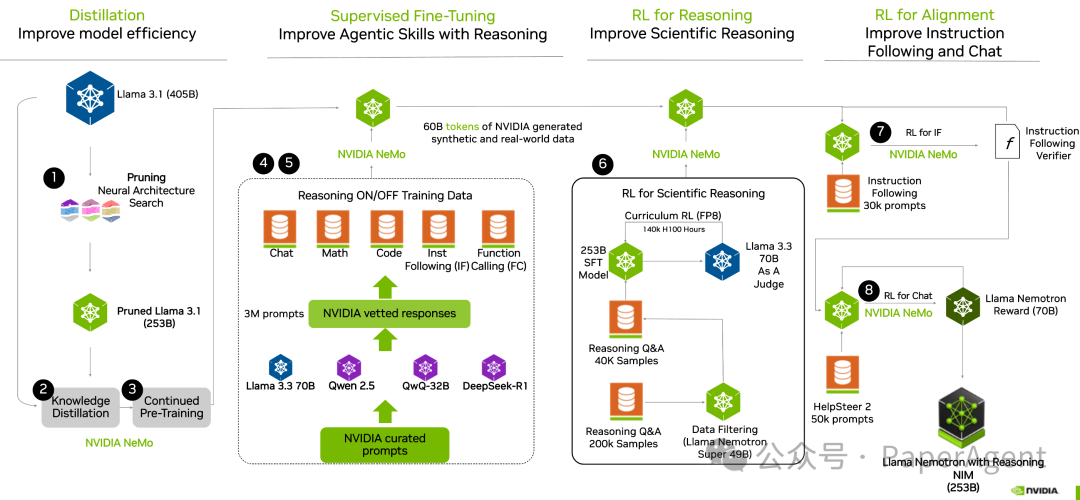
基于 Meta Llama-3.1-405B-Instruct 的一款推理模型,经过后续训练以增强推理能力、人类聊天偏好以及诸如 RAG 和工具调用等任务的性能。支持长达 128K 个标记的上下文长度,可以在单个 8xH100 节点上进行推理。
该模型经过了多阶段的后续训练过程,以增强其推理和非推理能力。这包括针对数学、代码、推理、聊天和工具调用的监督微调阶段,以及使用组相对策略优化(GRPO)算法进行推理、聊天和指令遵循的多个强化学习(RL)阶段。
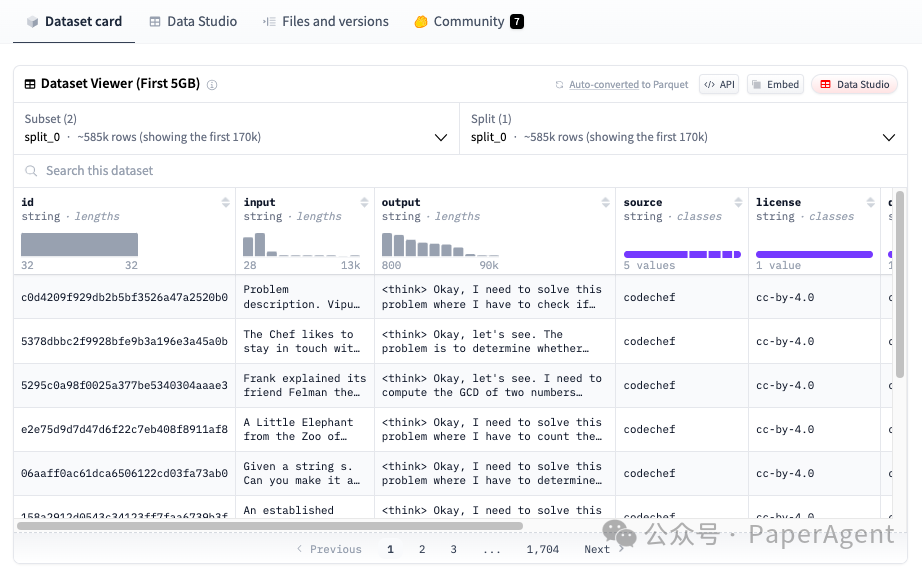
是迄今为止最大的基于推理的编程合成数据集,包含28,319个独特的编程竞赛问题中的735,255个Python样本。OpenCodeReasoning 是为监督式微调(Supervised Fine-Tuning, SFT)而设计的。
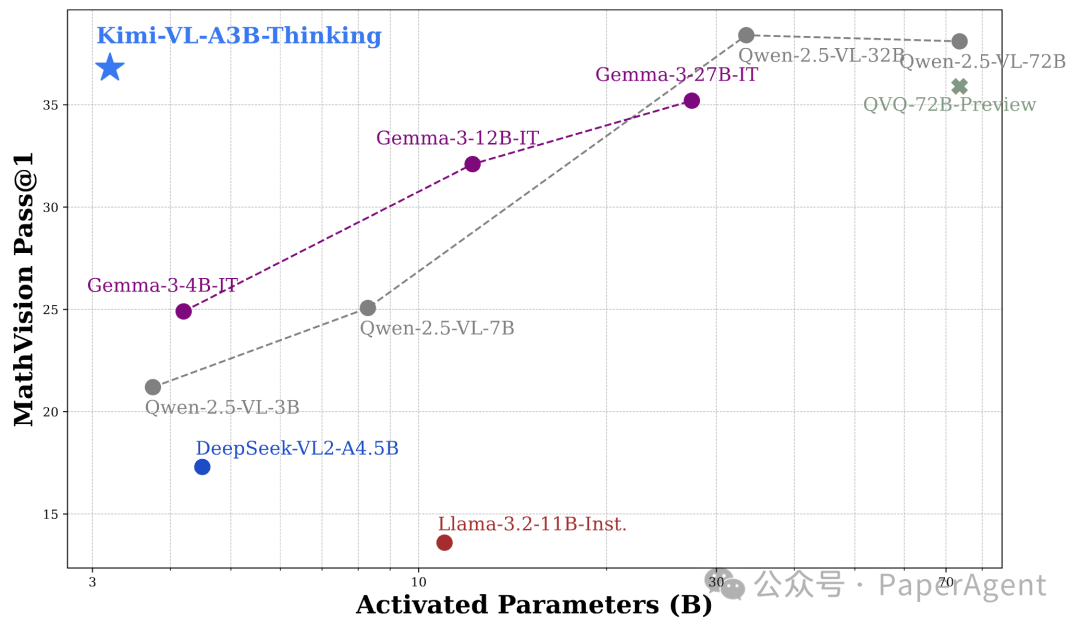
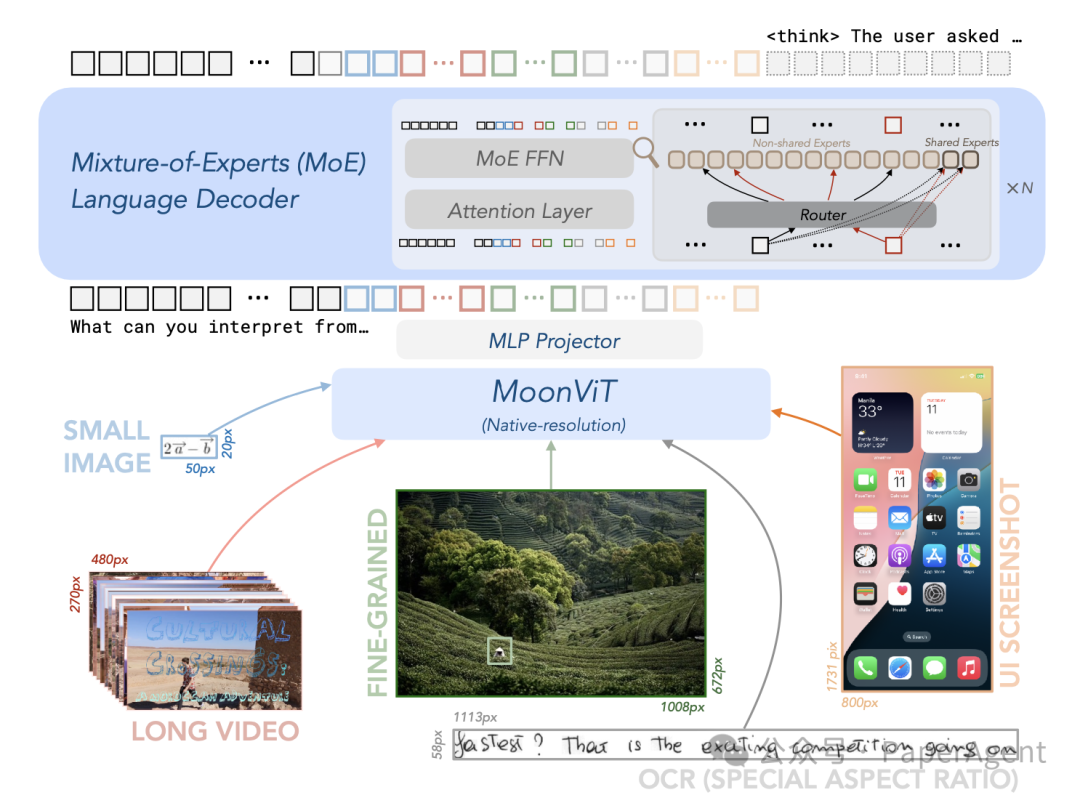
这是一款高效的开源混合专家(MoE)视觉-语言模型(VLM)。它在高级多模态推理、长文本理解以及强大的Agent能力方面表现出色,同时其语言解码器(Kimi-VL-A3B)仅激活了2.8B个参数。
在对比评估中,Kimi-VL 有效地与诸如 GPT-4o-mini、Qwen2.5-VL-7B 和 Gemma-3-12B-IT 等尖端高效的视觉-语言模型竞争,并且在几个专业领域中超越了 GPT-4o。

-
数据处理:将强化学习训练数据分为可验证问题(如STEM问题、代码问题)和不可验证问题(如创意写作、翻译),并针对不同问题类型采用不同的奖励建模方法,以提升模型的推理能力。
-
强化学习算法:为解决强化学习训练的不稳定性,提出了VAPO和DAPO两个框架,并借鉴了价值预训练、解耦GAE等关键技术,以提高模型的训练效率和性能。 -
RL基础设施:设计了流式Rollout系统(SRS)和混合分布式训练框架,通过并行机制、序列长度平衡、内存优化等手段,解决了长尾响应生成中的GPU空闲问题,提高了大规模训练的效率。

https://hf-mirror.com/agentica-org/DeepCoder-14B-Previewhttps://hf-mirror.com/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1https://hf-mirror.com/datasets/nvidia/OpenCodeReasoninghttps://github.com/ByteDance-Seed/Seed-Thinking-v1.5字节报告地址:https://github.com/ByteDance-Seed/Seed-Thinking-v1.5/blob/main/seed-thinking-v1.5.pdf
(文:PaperAgent)