

作者|子川
来源|AI先锋官
安静许久的kimi,终于又有新动作了!
近日,Kimi团队甩出一套组合拳——视觉语言模型Kimi-VL及其推理版Kimi-VL-Thinking双双开源!
这波操作直接把多模态+推理全都给拿捏了。
据介绍,两款模型都是具有 28 亿激活参数、160 亿总参数的 MoE 结构的多模态模型,支持128K上下文窗口,同时采用的是比较宽松的MIT许可证。
模型虽小,但和同层次模型相比,跑分成绩丝毫不差!
Kimi-VL在MMMU、MMBench等通用基准测试中的表现出色,超越了Qwen2.5-VL-7B、GPT-4o等多模态模型,在多项中测中取得第一的成绩。
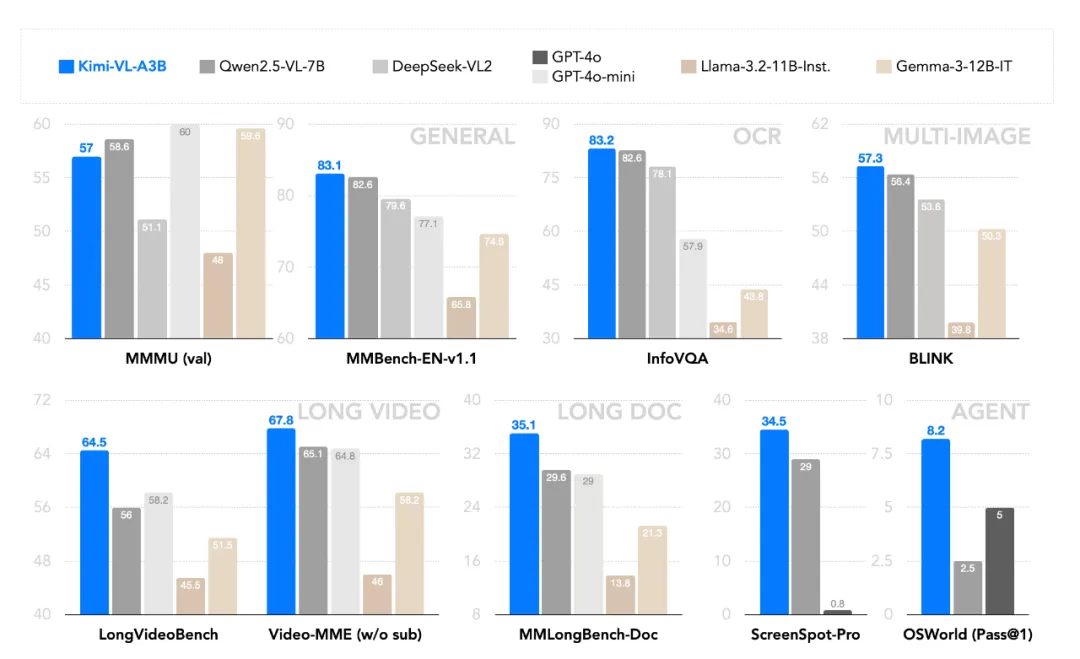
相较于基础版的Kimi-VL,支持长思考的Kimi-VL-Thinking会更强,在 MathVista 上提升了 2.6%,在 MMMU 上提升了 4.7%,在 MathVision 上提升了 15.4%。
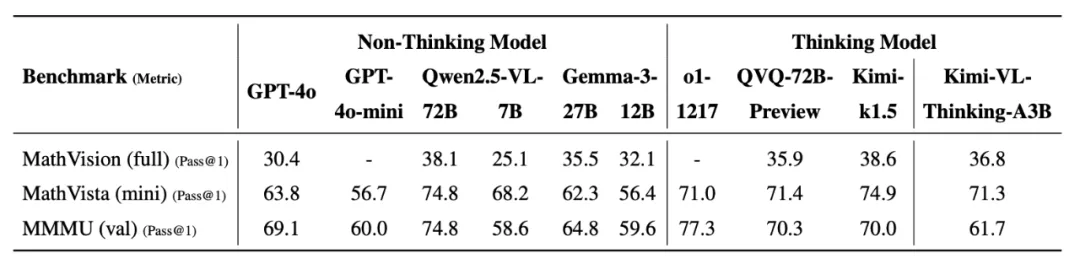
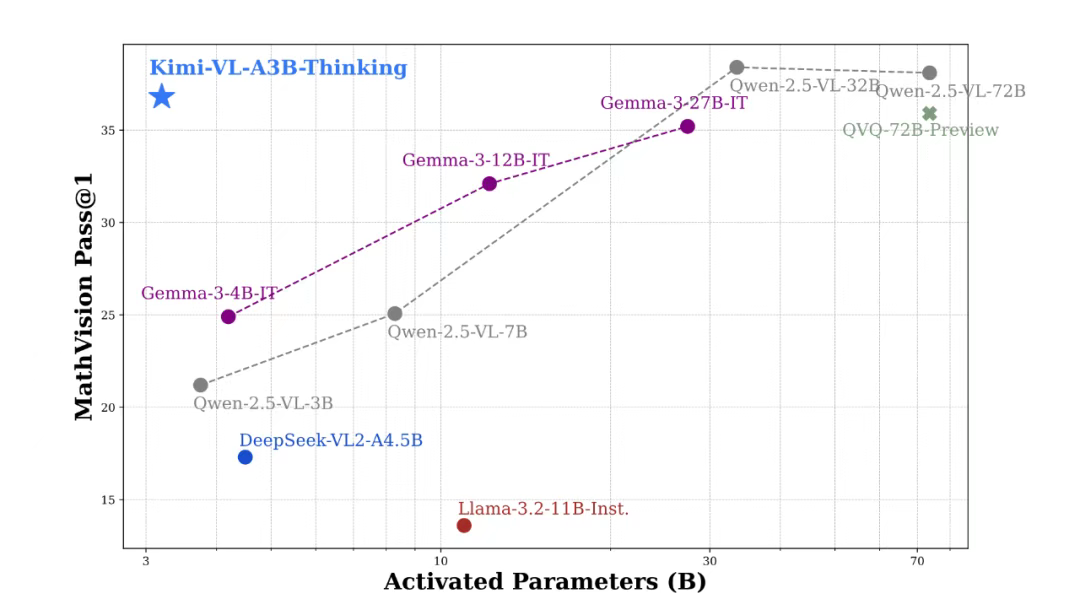
同时kimi团队表示, 尽管Kimi-VL-Thinking 是个只有 2.8B 激活参数的轻量级模型,但在有较高推理难度的基准测试(包括 MMMU,MathVision,MathVista)中,部分成绩可以接近甚至超过超大尺寸的前沿模型。
 目前两款模型均已上架Hugging Face,大家进行下载并部署到自己的程序上去使用。
目前两款模型均已上架Hugging Face,大家进行下载并部署到自己的程序上去使用。
Hugging Face 模型下载:
https://huggingface.co/moonshotai/Kimi-VL-A3B-Instruct、https://huggingface.co/moonshotai/Kimi-VL-A3B-Thinking
那这款只有 2.8B 激活参数的轻量级模型到底是如何媲美参数大10倍的模型的呢?
下面我们来扒一下Kimi此次公开的技术报告。
模型架构
Kimi-VL和Kimi-VL-Thinking主要由三大部分构成:一个原生分辨率视觉编码器(MoonViT)、一个 MLP 投影仪以及一个混合专家(MoE)语言模型。
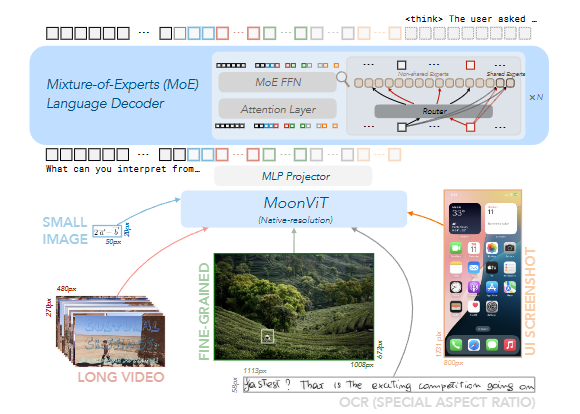
MoE 语言模型:语言生成模块
仅激活 2.8B 参数(总参数 16B),显著降低了计算成本,同时保持了强大的性能。
与传统的密集架构相比,MoE 架构通过稀疏激活专家网络,实现了更高的效率和扩展性。
MoonViT:图像处理模块
设计出的MoonViT,可以让它可以直接处理不同分辨率的图像,而不需要复杂的切割和拼接操作。
这里使用了一种方法,把图像切成小块,然后拼成一维序列。这样可以让 MoonViT 和语言模型共享计算方式,比如用 FlashAttention 技术处理不同长度的图像数据,确保不同分辨率的图像都能高效训练。
MLP 投影仪:连接模块
MLP 投影仪是一个两层的网络,用来连接图像处理模块和语言模型。它会先压缩图像特征的空间维度(比如 2×2 下采样),然后扩展通道维度,最后将特征转换为语言模型可以理解的形式。
数据处理与训练
-
多样化数据集: Kimi-VL 的预训练数据涵盖文本、图像、视频等多种模态,包括字幕数据、OCR 数据、知识数据和视频数据等,确保模型在不同任务中的广泛适用性。
-
渐进式训练策略: 模型通过多阶段训练(如 ViT 预训练、联合预训练、长上下文激活等)逐步提升语言和多模态能力,同时保留文本生成能力。
-
高效优化器(Muon): 使用增强版的 Muon 优化器,结合分布式实现和内存优化策略(如 ZeRO-1 和选择性检查点),显著提高了训练效率。
更多细节感兴趣可以查阅原论文。
论文地址:https://arxiv.org/abs/2504.07491v1#
最后,给大家分享一下大彩蛋。
在今年3月,基于Kimi-K1.6的数学模型被曝光了出来,在编程基准测试LiveCodeBench中超越o3、DeepSeek-R1等模型,取得第一的好成绩。
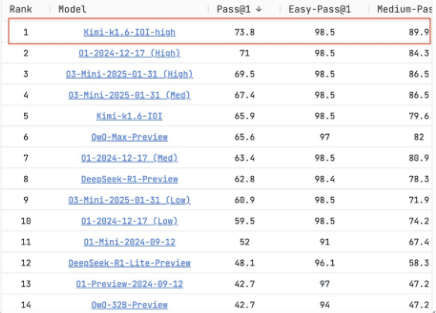
难怪kimi这几个月没有一点动静,原来是在在蒙声干大事。
(文:AI先锋官)